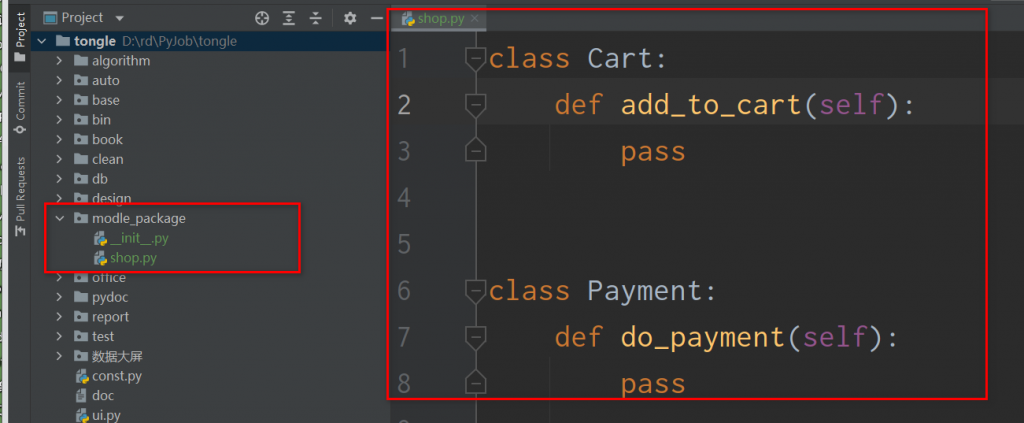
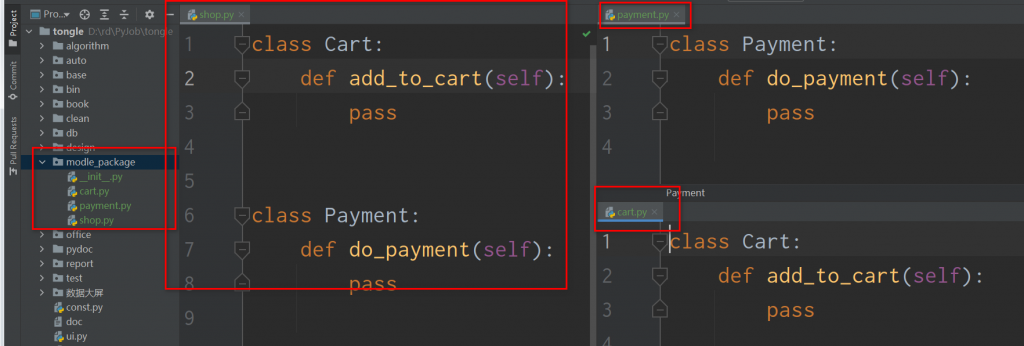
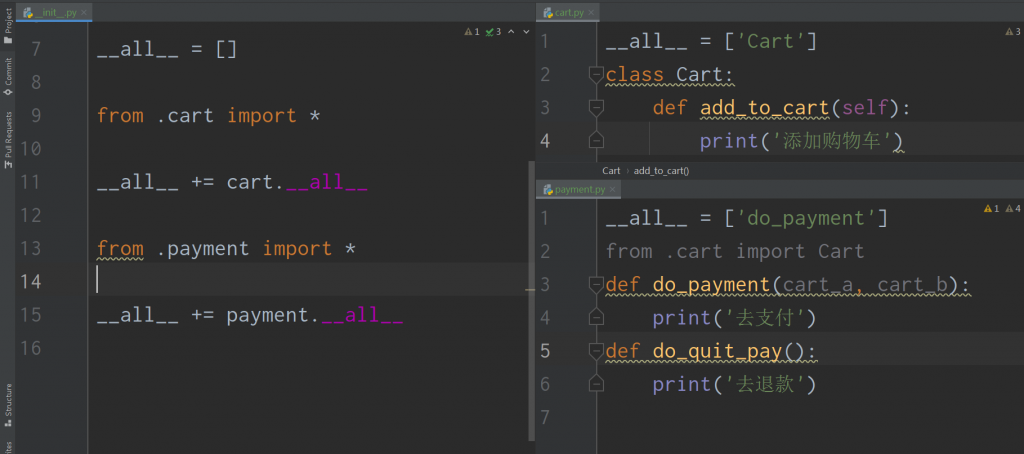
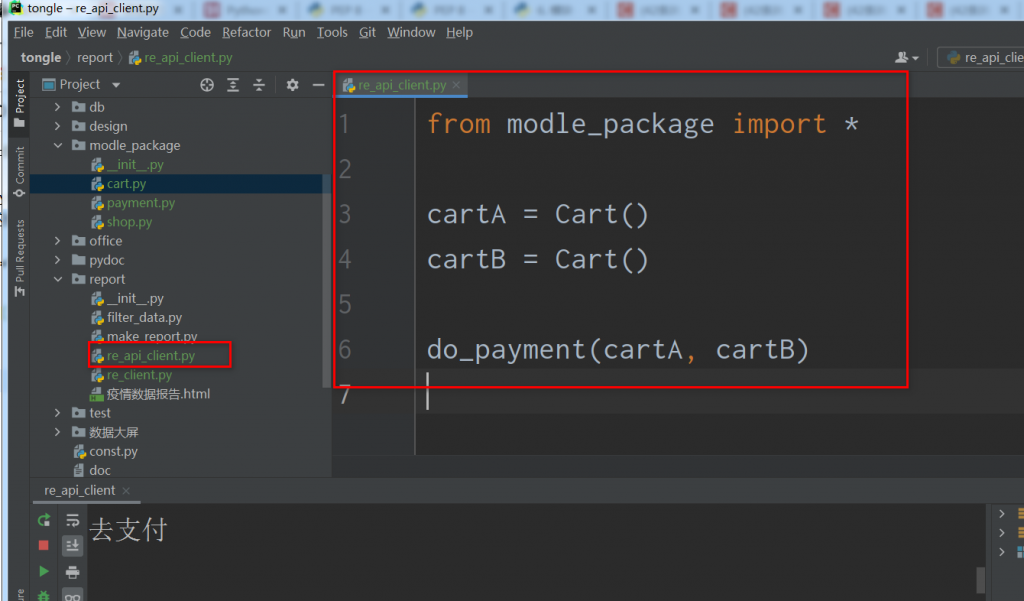
前言
小编之前录制的Python自动化办公课程里面没有录制Numpy 的内容,是因为有多维数组的存在,对于萌新来说,三维以上的数组,数据查询和计算,多多少少会有点头大。
Python 数据分析达人四剑客: numpy pandas sklearn 在加个平民版的Openpyxl 。
如果你想专业从事数据分析,外加个SQL技能。
pandas 你可以理解为它集成了 Numpy的查询和计算功能,以及Openpyxl 处理Excel的功能。
pandas是基于numpy数组构建的,但二者最大的不同是pandas是专门为处理表格和混杂数据设计的,比较契合统计分析中的表结构,而numpy更适合处理统一的数值数组数据。
大多数场景我们用Pandas 其实可以很好地完成我们的任务,但是Pandas ,它并没有完完全全的融合Numpy和Openpyxl.
在一些数据场景下,反而直接用Openpyxl 和Numpy处理起来更加快捷和方便。
numpy pandas or Openpyxl ,在处理复杂的数据情况下,我建议是可以混着用。
Numpy 学好,确实可以对Pandas的使用,更上一层楼。
这里,整合了一些于Numpy常用的知识点
- 1、创建ndarray数组
- 2、索引查询(单索引、切片、funcy index、联合索引)
- 3、通用函数(加减乘除取余次幂)
- 4、聚合函数(sum、mean、max、min、any、all、中位数、排名等)
- 5、广播规则
- 6、条件比较,布尔索引取值
- 7、排序
下面有将近2千行的Numpy 学习博客,让你一次学个够!
参考来源:Python数据科学手册
1、初识多维数组
import numpy as np
'''核心'''
'''
# 三维
# axis=0 :Y轴方向(竖着)以组为单位。
# axis=1 :Z轴方向竖着比较,以组中的上下行 。
# axis=2 :x轴方向横着比较。
# 二维
# axis=0 :Y轴方向(竖着)
# axis=1 :x轴方向(横这)
# 索引
# 一维
# x[start:stop:step]
# 二维
# x[Y,X] #Y轴索引,X轴索引
# x[Y1:Y2,X1:X2] # 索引切片范围查询
# x[Y1:Y2:step,X1:X2:step] # 索引切片范围查询,加索引步长
# 三维
# x[Y:Z:X] ,Y轴、 Z轴是每块(每组)的上下行索引,X轴
# x[Y1:Y2, Z1:Z2,X1:X2]
2、创建数组
#################1、创建数组##################################
np.random.seed(0) # seed for reproducibility
x1 = np.random.randint(10, size=6) # One-dimensional array
x2 = np.random.randint(10, size=(3, 4)) # Two-dimensional array
x3 = np.random.randint(10, size=(3, 4, 5)) # Three-dimensional array
'''
每个数组都有属性ndim(维数),
shape(每个维的大小)和size(数组的总大小):
'''
# print("x3 ndim: ", x3.ndim)
# print("x3 shape:", x3.shape)
# print("x3 size: ", x3.size)
# print("dtype:", x3.dtype) # 另一个有用的属性是dtype数组的数据类型
'''
其他属性包括itemsize,列出每个数组元素的大小(以字节为单位),
以及nbytes列出数组的总大小(以字节为单位):
一般而言,我们期望它nbytes等于itemsizeTimes size。
'''
# print("itemsize:", x3.itemsize, "bytes")
# print("nbytes:", x3.nbytes, "bytes")
3、利用索引访问单一元素
# 二维数组
# print(x2)
# 二维数组访问
# print(x2[0,0])
# print(x2[2,0])
# print(x2[2,-1])
# 二维数组赋值
# x2[0,0] = 12
# print(x2)
'''
请记住,与Python列表不同,NumPy数组具有固定类型。
例如,这意味着,如果您尝试将浮点值插入整数数组,则该值将被静默截断。
不要被这种行为所困扰!
'''
# x1 [ 0 ] = 3.14159 #这将被截断!
# print(x1)
4、数组切片
# 一维
# x[start:stop:step]
# x[::2] # 1,3,5,7
# x[1::2]
# x[:8:-1] # step 为负 为逆序
# 二维
# x[Y,X] #Y轴索引,X轴索引
# x[Y1:Y2,X1:X2] # 索引切片范围查询
# x[Y1:Y2:step,X1:X2:step] # 索引切片范围查询,加索引步长
# print(x2)
# print(x2[2,1]) # Y轴索引为2,X轴索引为1的数据:6,,索引0 开始,y 轴(竖) 索引为2 ,x轴(横)为1的数据。
# print(x2[:2, :3]) # 切片范围查询,Y轴索引0到索引1 的数据。X轴索引0 到索引2的数据。
# print(x2[:3, ::2]) # Y轴索引0 到2,X轴索引全部但是索引的步长为2.
# print(x2[::-1, ::-1]) # Y轴和X轴,均逆序输出
# 三维切片
# x[Y:Z:X] ,Z轴是每块(每组)的索引
# arr1 = np.arange(24)
#
# # 重塑矩阵
# arr2 = arr1.reshape(4,2,3) # 4块、每块两行、每块3列。 #将arr1变为4×2×3=24 个元素的多维数组,row * col * 列中列,
# # print(arr2)
# print(arr2[2,1,0]) # 单个索引
# print(arr2[:3, :1,:3]) # 展示2块,每块1行。 因为arr2 最大每块就是2行。
5、np.newaxis 增加维度
# a=np.array([1,2,3,4,5])
# aa=a[np.newaxis,:]
# print(aa)
# print(aa.shape)
6、axis详解
# arr3 = np.arange(24).reshape(4,2,3)
#
# print(arr3)
# # print(arr3.min(axis=1))
# print(arr3.sum(axis=0))
# 三维
# axis=0 :Y轴方向(竖着)以组为单位。
# axis=1 :Z轴方向竖着比较,以组中的上下行 。
# axis=2 :x轴方向横着比较。
# 二维
# axis=0 :Y轴方向(竖着)
# axis=1 :x轴方向(横这)
7、数组的串联和分隔
# x = np.array([1, 2, 3])
# y = np.array([3, 2, 1])
# z = np.array([5,6,7])
# xyz = np.concatenate([x, y,z])
# print(xyz)
#
# boy = np.array([[1, 2, 3],
# [4, 5, 6]])
# girl = np.array([[8, 9,10],
# [43, 52, 61]])
#
# boy_girl = np.concatenate([boy,girl],axis=1)
# print(boy_girl)
#
# x = np.array([1, 2, 3])
# grid = np.array([[9, 8, 7],
# [6, 5, 4]])
# vertically(垂直) stack the arrays
# vs = np.vstack([x, grid])
# print(vs)
# 水平堆叠
# y = np.array([[99],
# [99]])
# hs = np.hstack([grid, y])
# print(hs)
# 分列数组
# x = [1, 2, 3, 99, 99, 3, 2, 1]
# x1, x2, x3 = np.split(x, [3, 5]) # 从索引3 到索引4 砍两刀
# print(x1, x2, x3)
# grid = np.arange(16).reshape((4, 4))
# print(grid)
# #
# print('------------------------')
#
# upper,lower = np.vsplit(grid, [3]) # 水平分隔
# print(upper)
# print('------------------------')
# print(lower)
# left, right = np.hsplit(grid, [1]) # 垂直分隔
# print(left)
# print('------------------------')
# print(right)
8、数组通用的函数
# x = np.arange(4)
# print("x =", x)
# print("x + 5 =", x + 5)
# print("x - 5 =", x - 5)
# print("x * 2 =", x * 2)
# print("x / 2 =", x / 2)
# print("x // 2 =", x // 2) # floor division
# print("x ** 2 = ", x ** 2)
# print("x % 2 = ", x % 2)
'''
Operator Equivalent ufunc Description
+ np.add Addition (e.g., 1 + 1 = 2)
- np.subtract Subtraction (e.g., 3 - 2 = 1)
- np.negative Unary negation (e.g., -2)
* np.multiply Multiplication (e.g., 2 * 3 = 6)
/ np.divide Division (e.g., 3 / 2 = 1.5)
// np.floor_divide Floor division (e.g., 3 // 2 = 1)
** np.power Exponentiation (e.g., 2 ** 3 = 8)
% np.mod Modulus/remainder (e.g., 9 % 4 = 1)
'''
# https://numpy.org/doc/stable/reference/ufuncs.html
################9、聚合函数####################
'''
功能名称 NaN安全版本 描述
np.sum np.nansum 计算元素总和
np.prod np.nanprod 计算元素的乘积
np.mean np.nanmean 计算元素均值
np.std np.nanstd 计算标准偏差
np.var np.nanvar 计算方差
np.min np.nanmin 求最小值
np.max np.nanmax 寻找最大值
np.argmin np.nanargmin 查找最小值的索引
np.argmax np.nanargmax 查找最大值的索引
np.median np.nanmedian 计算元素的中位数
np.percentile np.nanpercentile 计算元素的基于排名的统计信息
np.any 不适用 评估任何元素是否为真
np.all 不适用 评估所有元素是否为真
我们将在本书的其余部分中经常看到这些汇总。
'''
# 小案例
# import pandas as pd
# data = pd.read_csv('data/president_heights.csv')
# heights = np.array(data['height(cm)'])
# print("Mean height: ", heights.mean())
# print("Standard deviation:", heights.std())
# print("Minimum height: ", heights.min())
# print("Maximum height: ", heights.max())
#
# # 百分之25 的平均身高
# print("25th percentile: ", np.percentile(heights, 25))
# # 中位数的身高
# print("Median: ", np.median(heights))
# # 百分之75人的平均很高
# print("75th percentile: ", np.percentile(heights, 75))
9、广播的规则
'''
广播的规则
NumPy中的广播遵循一组严格的规则来确定两个数组之间的交互:
规则1:如果两个数组的维数不同,则维数较少的数组的形状将在其前(左侧)填充。
规则2:如果两个数组的形状在任何维度上都不匹配,则将在该维度上形状等于1的数组拉伸以匹配其他形状。
规则3:如果在任何维度上尺寸不一致,且两个尺寸都不等于1,则会引发错误。
'''
# 具有相同shape的数组
# a = np.array([0, 1, 2])
# b = np.array([5, 5, 5])
# print(a+b)
#数组加零维数组
# print(a+5) # 扩展或复制5到数组[5, 5, 5]
# 二维数组 + 一维数组
# M = np.ones((3, 3))
# print(M)
# print(M +a)
# 一维数组a被拉伸或在第二维上广播以匹配的形状。
# 两个广播,同时拉伸a 和b,匹配一个通用的形状。
# a = np.arange(3)
# b = np.arange(3)[:, np.newaxis]
#
# print(a)
# print(b)
# print(a+b)
'''
广播示例1
M = np.ones((2, 3))
a = np.arange(3)
让我们考虑对这两个数组的操作。数组的形状是
M.shape = (2, 3)
a.shape = (3,)
通过规则1可以看到数组a的维数较少,因此我们在数组的左侧填充了1维:
M.shape -> (2, 3)
a.shape -> (1, 3)
根据规则2,我们现在看到第一个维度不一致,因此我们拉伸该维度以使其匹配:
M.shape -> (2, 3)
a.shape -> (2, 3)
形状匹配,我们看到最终形状将是(2, 3):
M + a
array([[1.,2.,3.],
[1.,2.,3.]])
广播示例2
a = np.arange(3).reshape((3, 1))
b = np.arange(3)
再次,我们将从写出数组的形状开始:
a.shape = (3, 1)
b.shape = (3,)
规则1规定我们必须用1填充形状b:
a.shape -> (3, 1)
b.shape -> (1, 3)
规则2告诉我们,我们将每个升级,以匹配另一个数组的相应大小:
a.shape -> (3, 3)
b.shape -> (3, 3)
因为结果匹配,所以这些形状是兼容的。我们可以在这里看到:
广播示例3
M = np.ones((3, 2))
a = np.arange(3)
数组的形状是
M.shape = (3, 2)
a.shape = (3,)
再次,规则1告诉我们,必须使用填充形状a:
M.shape -> (3, 2)
a.shape -> (1, 3)
根据规则2,的第一个维度a被拉伸以匹配的第一个维度M:
M.shape -> (3, 2)
a.shape -> (3, 3)
最终形状不匹配,因此这两个数组不兼容导致报错ValueError
为了消除错误可以,增加数组维度,来进行配
a[:, np.newaxis].shape
(3, 1)
M + a[:, np.newaxis]
'''
10、数组条件比较
'''
== np.equal != np.not_equal
< np.less <= np.less_equal
> np.greater >= np.greater_equal
'''
# rng = np.random.RandomState(0)
# x = rng.randint(10, size=(3, 4))
# print(x)
# print(x<3)
# print(x[x<3]) # 布尔索引
# 计数,计算数组中小于3的数据有多少个
# print(np.count_nonzero(x<3))
# 同样用sum 也可以求出小于5的个数
# print(np.sum(x < 5))
# #每行有多少个小于6的值?
# print(np.sum(x<6,axis=1))
# print(np.all(x < 8, axis=1)) # 判断每行中的所有数据
# 判断每行中的任一一个数据小于8,就返回true.
# print(np.any(x < 8, axis=1))
11、numpy 核心布尔运算符
# 与:(x > 3) & (x < 6)
# print(np.sum((x > 3) & (x < 6)))
# print(np.sum((x <= 3))) # x<=3 是5个
# print(np.sum((x >=7))) # x>=7 是3 个
# 或:(x <= 3) | (x>= 7) )),匹配的条件更多
# 非:~
# print(np.sum(( ~(x <= 3) | (x>= 7) )))
12、fancy index 神奇索引(花样索引)
# rand = np.random.RandomState(42)
# x = rand.randint(100, size=10)
# print(x)
# 第一种方式,索引取值
# print([x[3], x[7], x[2]])
# 第二种方式
# ind = [3,7,4]
# print(x[ind])
# 第三种方式,这种为花样索引
# ind = np.array([[3, 7],
# [4, 5]])
# print(x[ind])
# X = np.arange(12).reshape((3, 4))
# print(X)
# row = np.array([0, 1, 2]) # Y轴
# col = np.array([2, 1, 3]) # X轴
#
# print(X[row, col])
#
# print('----------------------------')
# print(X [ row [:, np.newaxis ], col])
'''
在这里,每个行值都与每个列向量匹配,就像我们在广播算术运算中看到的那样。例如:
务必记住,使用花式索引时,返回值反映的是索引的广播形状,而不是所索引数组的形状。
'''
13、联合索引
print(X [ 2 , [ 2,0,1 ]]) # Y轴第二个,X轴索引为2,0,1 这三个数据
14、花式索引修改其值
# x = np.arange(10)
# i = np.array([2, 1, 8, 4])
# 把i 对应的索引的值都修改成99
# x[i] = 99
# print(x)
# 把i 对应的值都相应的减去10
# x[i] -= 10
# print(x)
# i = [2, 3, 3, 4, 4, 4]
# x[i] += 1
# print(x)
15、排序
# a = np.array([[1,4],[3,1]])
# print(a)
# aa= np.sort(a,axis=1) # 沿最后一个轴排序
# print(aa)
# bb= np.sort(a, axis=None) # 多维变一维进行排序
# print(bb)
# cc = np.sort(a, axis=0) # Y轴排序
# print(cc)
# 通过字段进行排序
# 使用order关键字指定对结构化数组进行排序时要使用的字段:
# dtype = [('name', 'S10'), ('height', float), ('age', int)]
# values = [('Arthur', 1.8, 41), ('Lancelot', 1.9, 38),
# ('Galahad', 1.7, 38)]
# a = np.array(values, dtype=dtype) # create a structured array
# ab =np.sort(a, order='height')
# print(ab)
# 按年龄排序,如果年龄相等,则按身高排序:
# abc = np.sort(a, order=['age', 'height'])
# print(abc)
16、创建结构化数组
# 第一种方式
# nd1 = np.dtype({'names':('name', 'age', 'weight'),
# 'formats':('U10', 'i4', 'f8')})
#
# # 第二种方式
# nd2 = np.dtype({'names':('name', 'age', 'weight'),
# 'formats':((np.str_, 10), int, np.float32)})
# # 第三种方式
# nd3 = np.dtype('S10,i4,f8')
# print(nd3)
'''
Character Description Example
'b' Byte np.dtype('b')
'i' Signed integer np.dtype('i4') == np.int32
'u' Unsigned integer np.dtype('u1') == np.uint8
'f' Floating point np.dtype('f8') == np.int64
'c' Complex floating point np.dtype('c16') == np.complex128
'S', 'a' String np.dtype('S5')
'U' Unicode string np.dtype('U') == np.str_
'V' Raw data (void) np.dtype('V') == np.void
'''
# np.array([1, 2, 3]) # 创建一维数组
# np.array([[1, 2], [3, 4]]) # 创建二维数组
# np.array([1, 2, 3], ndmin=2) # 通过ndmin 来指定创建2维数组
#
# str_arr = np.array([1, 2, 3], dtype=str) #提供类型来创建数组
# print(str_arr)
#
# # a,b 为字段名称,'<i4' 为int 数据类型
# x = np.array([(1,2),(3,4)],dtype=[('a','<i4'),('b','<i4')])
# print(x['b'])
# 创建一个矩阵,就是一个二维ndarray简化版
# mat_arr = np.array(np.mat('1 2 ; 3 4'))
# print(mat_arr)
参考来源:利用Python进行数据分析
1、生成随机数组
import numpy as np
'''
用来存储和处理大型矩阵,
比Python自身的嵌套列表(nested list structure)结构要高效的多
,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
'''
data = np.random.rand(2,3)
print(data)
print(data*10) # 所有元素都乘以了10
print(data+data) # 数组中的对应元素进行了相加
2、生成ndarray
data1 = [6,7.5,8,0,1]
arr1 = np.array(data1)
print(arr1)
data2 = [[1,2,3,4],[5,6,7,8]]
arr2 = np.array(data2)
print(arr2) # 因为是嵌套列表,so,形成了二维数组
# 通过检查ndim,shape属性来确认
arr2.ndim #阵列的轴数(维度)
arr2.shape
#判断数组元素类型
arr1.dtype
# 创建数组
np.zeros(10)
np.zeros((3,6))
np.empty((2,3,2))
np.arange(15)
3.ndarray 数据类型
arr1 = np.array([1, 2, 3], dtype=np.float64)
arr2 = np.array([1, 2, 3], dtype=np.int32)
arr1.dtype
arr2.dtype
arr = np.array([1, 2, 3, 4, 5])
arr.dtype
float_arr = arr.astype(np.float64)
float_arr.dtype
arr = np.array([3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
arr
arr.astype(np.int32)
numeric_strings = np.array(['1.25', '-9.6', '42'], dtype=np.string_)
numeric_strings.astype(float)
int_array = np.arange(10)
calibers = np.array([.22, .270, .357, .380, .44, .50], dtype=np.float64)
int_array.astype(calibers.dtype)
empty_uint32 = np.empty(8, dtype='u4')
empty_uint32
4、Numpy数组运算
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
arr
arr * arr
arr - arr
1 / arr
arr ** 0.5
arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
arr2
arr2 > arr
5、基础索引与切片
arr
arr[5]
arr[5:8]
arr[5:8] = 12
arr
arr_slice = arr[5:8]
arr_slice
arr_slice[1] = 12345
arr
arr_slice[:] = 64
arr
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
arr2d[2]
arr2d[0][2]
arr2d[0, 2]
arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
arr3d
arr3d[0]
old_values = arr3d[0].copy()
arr3d[0] = 42
arr3d
arr3d[0] = old_values
arr3d
arr3d[1, 0]
x = arr3d[1]
x
x[0]
6、切片索引
arr
arr [1:6 ]
arr2d
arr2d [:2 ]
arr2d [:2 , 1 :]
arr2d [ 1 , :2 ]
arr2d [:2, 2 ]
arr2d [:, :1 ]
arr2d [:2,1:] = 0
7、 布尔索引
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
data = np.random.randn(7, 4) #生成一些正态分布的数据 7行 4列
names
data
names == 'Bob'
data[names == 'Bob'] # 把布尔值数组作为data 的索引。 注意:布尔值数组的长度必须和数组轴索引长度一致,
data[names == 'Bob', 2:]
data[names == 'Bob', 3]
names != 'Bob'
data[~(names == 'Bob')]
cond = names == 'Bob'
data[~cond]
mask = (names == 'Bob') | (names == 'Will')
mask
data[mask]
data[data < 0] = 0
data
data[names != 'Joe'] = 7
data
8、神奇索引
'''
神奇索引是Numpy中的术语,用于描述使用整数数组进行数据索引
'''
arr = np.empty((8, 4))
for i in range(8):
arr[i] = i
arr
arr[[4, 3, 0, 6]]
arr[[-3, -5, -7]]
arr = np.arange(32).reshape((8, 4))
arr
arr[[1, 5, 7, 2], [0, 3, 1, 2]]
arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]]
9、数组转置和换轴
'''
转置是一种特殊的数据重组形式,可以返回底层数据的视图而不需要复制任何内容
数组拥有transpose方法,也有特殊的T属性
'''
arr = np.arange(15).reshape((3, 5))
arr
arr.T
arr = np.random.randn(6, 3)
arr
#如果arr5和arr6都是二维数组,那么它返回的是矩阵乘法。
arr5 = np.array([[2,3],[4,5]])
arr6 = np.array([[6,7],[8,9]])
np.dot(arr5,arr6)
# 1、 2 * 6 + 3 * 8 = 36
# 2、 2 * 7 + 3 * 9 = 41
# 3、 4 * 6 + 5 * 8 = 64
# 4、 4 * 7 + 5 * 9 = 73
arr = np.arange(16).reshape((2, 2, 4))
arr
arr.transpose((1, 0, 2))
arr
arr.swapaxes(1, 2) # swapaxes 返回的是数据的视图,而没有对数据进行复制
10、通用函数
arr
np.sqrt(arr)
np.exp(arr)
x = np.random.randn(8)
y = np.random.randn(8)
x
y
np.maximum(x, y)
arr = np.random.randn(7) * 5
arr
remainder, whole_part = np.modf(arr)
remainder
whole_part
arr
np.sqrt(arr)
np.sqrt(arr, arr)
arr
11、使用数组进行面向数组编程
points = np.arange(-5, 5, 0.01) # 1000 equally spaced points
xs, ys = np.meshgrid(points, points)
ys
z = np.sqrt(xs ** 2 + ys ** 2)
z
import matplotlib.pyplot as plt
plt.imshow(z, cmap=plt.cm.gray); plt.colorbar()
plt.title("Image plot of $\sqrt{x^2 + y^2}$ for a grid of values")
plt.draw()
plt.close('all')
12、将条件逻辑作为数组操作
xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
yarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
cond = np.array([True, False, True, True, False])
result = [(x if c else y)
for x, y, c in zip(xarr, yarr, cond)]
result
result = np.where(cond, xarr, yarr)
result
arr = np.random.randn(4, 4)
arr
arr > 0
np.where(arr > 0, 2, -2)
np.where(arr > 0, 2, arr) # set only positive values to 2
13、数学和统计方法
arr = np.random.randn(5, 4)
arr
arr.mean()
np.mean(arr)
arr.sum()
arr.mean(axis=1)
arr.sum(axis=0)
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7])
arr.cumsum()
arr = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
arr
arr.cumsum(axis=0)
arr.cumprod(axis=1)
14、布尔值数组的方法
arr = np.random.randn(100)
(arr > 0).sum() # Number of positive values
bools = np.array([False, False, True, False])
bools.any()
bools.all()
15.排序
arr
arr.sort()
arr
arr = np.random.randn(5, 3)
arr
arr.sort(1)
arr
large_arr = np.random.randn(1000)
large_arr.sort()
large_arr[int(0.05 * len(large_arr))] # 5% quantile
16 、唯一值与其它集合逻辑
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
np.unique(names)
ints = np.array([3, 3, 3, 2, 2, 1, 1, 4, 4])
np.unique(ints)
sorted(set(names))
values = np.array([6, 0, 0, 3, 2, 5, 6])
np.in1d(values, [2, 3, 6])
17、使用数组进行文件输入和输出
arr = np.arange(10)
np.save('some_array', arr)
np.load('some_array.npy')
np.savez('array_archive.npz', a=arr, b=arr)
arch = np.load('array_archive.npz')
arch['b']
np.savez_compressed('arrays_compressed.npz', a=arr, b=arr)
18、线性代数
y = np.array([[6., 23.], [-1, 7], [8, 9]])
x
y
x.dot(y)
np.dot(x, y)
np.dot(x, np.ones(3))
x @ np.ones(3)
from numpy.linalg import inv, qr
X = np.random.randn(5, 5)
mat = X.T.dot(X)
inv(mat)
mat.dot(inv(mat))
q, r = qr(mat)
r
Numpy快速入门
基础知识
# 基础知识
# NumPy的主要对象是齐次多维数组。它是一个元素表(通常是数字),所有相同的类型,由正整数的元组索引。在NumPy维度被称为轴。轴的数量是等级。
#
# 例如,三维空间中一个点的坐标[1,2,1]是一个等级为1的数组,因为它具有一个坐标轴。该轴的长度为3.
#
# 在下面的示例中,该数组具有等级2(它是二维的)。第一维(轴)的长度为2,第二维的长度为3。
#
# [[ 1. , 0. , 0 ],
# [ 0. , 1. , 2. ]]
# NumPy的数组类叫做ndarray。它也被别名数组所知 。请注意,numpy.array与标准Python库类array.array不一样,它只处理一维数组,并且提供较少的功能。ndarray对象的更重要的属性是:
#
# ndarray.ndim
# 阵列的轴数(维度)。在Python世界中,维度的数量被称为等级。
# ndarray.shape
# 数组的尺寸。这是一个整数的元组,指示每个维度中数组的大小。对于有n行m列的矩阵,形状将是(n,m)。形状元组的长度 因此是等级或维数 ndim。
# ndarray.size
# 数组元素的总数。这等于形状的元素的乘积。
# ndarray.dtype
# 一个描述数组中元素类型的对象。可以使用标准的Python类型创建或指定dtype。另外NumPy提供它自己的类型。numpy.int32,numpy.int16和numpy.float64是一些例子。
# ndarray.itemsize
# 数组中每个元素的字节大小。例如,类型为float64的元素的数组具有项目大小 8(= 64/8),而类型complex32中的一个具有项目大小 4(= 32/8)。这相当于ndarray.dtype.itemsize。
# ndarray.data
# 包含数组的实际元素的缓冲区。通常,我们不需要使用这个属性,因为我们将使用索引设施访问数组中的元素。
'''
import numpy as np #可用来存储和处理大型矩阵的工具
from numpy import pi
import matplotlib.pyplot as plt
a = np.arange(15).reshape(3, 5) # 默认是从生成0-14个数字,分成三组,每组5个元素。
np.random.randint(11,size=(2,3)) #通过随机生成二维三列的矩阵
print(a)
a.shape #数组的尺寸
a.ndim #阵列的轴数
a.dtype.name #一个描述数组中元素类型的对象
a.itemsize #数组中每个元素的字节大小
a.size #数组元素的总数
type(a)
b = np.array([6, 7, 8.1,'ztloo',1]) #创建一个数组
b
b.dtype
type(b) #获取变量b的数据类型
np.array([(1.5, 2, 3), (4, 5, 6)]) #数组将序列序列转换成二维数组,将序列序列转换成三维数组,等等
np.array([[1, 2], [3, 4]], dtype=complex) #数组的类型也可以在创建时明确指定:,complex:复杂类型
#NumPy提供了几个函数来创建具有初始占位符内容的数组。 这样可以最大限度地减少增加阵列的成本
np.zeros((3,4)) #创建全是零的二维,三组4列的元素。默认情况下,创建的数组的dtype是float64。
np.ones((2,3,4), dtype=np.int16) #创建全是1的三维数组,分两组,4列。
np.empty((2,3))#空函数创建一个数组,其初始内容是随机的,取决于内存的状态
np.arange(10, 30, 5) #返回一个范围数组数组
np.linspace( 0, 2, 9 ) #arange与浮点参数一起使用时,由于有限的浮点精度,获得不到元素的数量。 使用函数linspace作为参数来接收我们想要的元素的数量
x = np.linspace( 0, 2*pi, 100 ) #用于评估许多点的功能
f = np.sin(x)
np.arange(6) #一维数组
np.arange(12).reshape(4,3) #二维数组
np.arange(24).reshape(2,3,4) #三维数组
np.arange(10000) #如果数组太大而无法打印,NumPy会自动跳过数组的中心部分,只打印角点:
创建矩阵
np.mat([[1,2,3],[4,5,6]])
np.mat(np.arange(10)) #把数组转换成矩阵
#数组上的算术运算符应用于元素。 一个新的数组被创建并填充结果
a = np.array([20, 30, 40, 50])
b = np.arange(4)
b
a-b
b**2
10*np.sin(a)
a<35
#与许多矩阵语言不同,运算符 *在NumPy数组中以元素形式操作。 矩阵乘积可以使用点函数或方法执行:
A = np.array( [[1,1],[0,1]] )
B = np.array( [[2,0],[3,4]] )
A*B
A.dot(B) #所得到的数组中的每个元素为,第一个矩阵中与该元素行号相同的元素与第二个矩阵与该元素列号相同的元素,两两相乘后再求和。
#A第一行元素:[1,1] * B第一列元素 [2,3] = 1*2 +1*3 = 5 =X = array([[X, Y], [X1, Y1]])
#A第一行元素:[1,1] * B第二列元素 [0,4] = 1*0 +1*4 = 4 =Y = array([[X, Y], [X1, Y1]])
#A第二行元素:[0,1] * B第一列元素 [2,3] = 0*2 +1*3 = 3 =x1 = array([[X, Y], [X1, Y1]])
#A第二行元素:[0,1] * B第二列元素 [0,4] = 0*0 +1*4 = 4 =y1 = array([[X, Y], [X1, Y1]])
# 最终输出结果:array([[5, 4], [3, 4]])
#例如+=和*=)适当地修改现有数组,而不是创建一个新数组。
a = np.ones((2,3), dtype=int)
b = np.random.random((2, 3))
a *= 3
a
b += a
b
a += b #报错,因为b不会自动转换为整数类型
#在使用不同类型的数组时,结果数组的类型对应于更更精确的数组(称为上传)。
a = np.ones(3, dtype=np.int32)
b = np.linspace(0, pi, 3)
b.dtype.name
c = a+b
c
c.dtype.name
d = np.exp(c*1j) #计算各元素的指数值
d
d.dtype.name
一元运算
a = np.random.random((2,3))
a
a.sum()
a.min()
a.max()
a.mean()
a = np.random.random((2,3))
a
a.sum()
a.min()
a.max()
a.mean()
#通过指定轴参数,您可以沿着数组的指定轴应用操作
b = np.arange(12).reshape(3, 4)
b
b.sum(axis=0)#每列的总和
b.min(axis=1)#每行最小的数
b.cumsum(axis=1)#每行的累计和,每行除开头外,第二个数是开头数+本身,进行累计。第三个数=第二个数+第三个数
#常用的数学函数,如sin,cos和exp。 在NumPy中,这些被称为“通用函数”(ufunc)
B = np.arange(3)
B
np.exp(B)
np.sqrt(B)
C = np.array([2., -1., 4.])
np.add(B, C)
列表一样的一维数组,既能索引又能
a = np.arange(10)**3
a
a[2]
a[2:5]
a[:6:2] = -1000 #相当于[0:6:2] = -1000; 从开始到第6位,独占,每第二个元素设置为-1000
a
a[::-1] #把a反向输出
for i in a:
print(i ** (1 / 3.))
#多维数组每个轴可以有一个索引。 这些索引用逗号分隔: [y的索引:x的索引] =[y+1:x+1]
def f(x,y):
return 10 * x + y
b = np.fromfunction(f,(5,4),dtype=int) #以f函数式创建数组 ,创建整数数组,y轴为5,x轴为4的数组,
b
b[2, 3]#索引是从零开始,y轴=3,x轴为2 的数为=23
b[0:5, 1] #第二列中的每一行,0:5 是从y轴的取值范围,索引:1 相当于x轴的第二列、
b[ : ,1] #相当于b[0:5, 1],不给取值范围,默认去x轴第二列
b[1:3, :] #第二行和第三行中的每一列。
#当提供的索引数量少于轴数时,缺失的索引被认为是完整的切片:
b[-1] #最后一行 相当于b [-1 ,:]
# a 3D array (two stacked 2D arrays)
c = np.array( [[[ 0, 1, 2], [ 10, 12, 13]],[[100,101,102],[110,112,113]]])
c.shape
c[1,...] #同c [1,:,]或c [1]
c[...,2] #与c [:,:,2]相同
迭代多维数组是相对于第一个轴完成的:
for row in b:
print(row)
对数组中的每个元素执行操作
for element in b.flat:
print(element)
改变数组的形状
a = np.floor(10*np.random.random((3,4)))
a
a.shape
a.ravel()#返回展开的数组变成一维度。
a.reshape(6,2) #返回具有修改形状的数组,y变成6行,x变成2列。
a.T #返回数组,转置 x和y轴互换。
a.T.shape
a.shape
a.resize((2,6)) #y轴变两行。x轴变6列。
a
a.reshape(3,-1)#y轴变3行。x轴其-1,会自动计算x轴的列数。
#几个阵列可以沿不同的轴堆叠在一起:
a = np.floor(10*np.random.random((2,2)))
a
b = np.floor(10*np.random.random((2,2)))
b
np.vstack((a,b)) #b数组拼接在a数组的y轴的负方向上
np.hstack((a,b)) #b数组拼接在a数组的x轴的正方向上
#函数column_stack将 一维数组作为列叠加到2维数组中。它相当于仅用于一维数组的vstack:
from numpy import newaxis
np.column_stack((a,b)) # 把a的x和b的x轴的第一行和第二行分别拼接。
a = np.array([4.,6.])
b = np.array([3.,8.])
a[:,newaxis] #这允许有一个2D列向量,
np.column_stack((a[:,newaxis],b[:,newaxis]))
np.vstack((a[:,newaxis],b[:,newaxis])) #把a,b的x变成y,然后进行串联拼接
np.r_[1:4, 0, 4]
#使用hsplit,可以通过指定要返回的相同形状的数组的数量,或通过指定分割应该发生之后的列来沿着其横轴拆分数组:
a = np.floor(10*np.random.random((2,12)))
a
np.hsplit(a, 3) # 沿着x轴拆分成3列(4,4,4)
np.hsplit(a,(3,4)) # 沿着x轴拆分成3列,然后再把第四列拆分为一组。由(4,4,4)变(3,1,8)
#当操作和操作数组时,它们的数据有时会被复制到一个新的数组中,这通常是初学者混淆的来源。有三种情况:
a = np.arange(12)
b = a # 不创建新对象
b is a
b.shape = 3, 4 ##改变形状
a.shape
#Python将可变对象作为引用传递,所以函数调用不会复制。
def f(x):
print(id(x))
id(a) #id是对象的唯一标识符
f(a)
c = a.view()
c is a
c.base is a #c是由拥有的数据的视图
c.flags.owndata
c.shape = 2,6 # 一个的形状不改变
a.shape
c[0,4] = 1234 # a的数据变化
a
s = a[ : , 1:3]
# 为了清晰起见,添加了#个空格; 也可以写成“s = a [:,1:3]”
s[:] = 10 #s [:]是s的视图。注意S = 10和s之间的差[:] = 10
a
深复制;该复制方法使阵列及其数据的完整副本
d = a.copy() #创建新数据的新数组对象
d is a
d.base is a # d不与分享任何
d[0,0] = 9999
a
常用的函数大全
数组创建
#-arange, array, copy, empty, empty_like, eye, fromfile,
#-fromfunction, identity, linspace,
logspace, mgrid, ogrid, ones, ones_like,
#- r, zeros, zeros_like
转换
#- ndarray.astype, atleast_1d, atleast_2d, atleast_3d, mat
手法
#--- array_split, column_stack, concatenate, diagonal, dsplit,dstack, hsplit, hstack,
#--- ndarray.item, newaxis, ravel, repeat, reshape, resize,
#--- squeeze, swapaxes, take, transpose, vsplit, vstack
问题
#--- all, any, nonzero, where
函数指令
#- argmax, argmin, argsort, max, min, ptp, searchsorted, sort
操作
#--- choose, compress, cumprod, cumsum, inner,
ndarray.fill, imag, prod, put, putmask, real, sum
基本统计
#--- cov, mean, std, var
基本的线性代数
#--- cross, dot, outer, linalg.svd, vdot
Numpy的API
a = np.arange(12)**2 # 前12个平方数
i = np.array( [ 1,1,3,8,5 ] ) # 一个索引的阵列
a[i] # 的在位置上的元件我
j = np.array( [ [ 3, 4], [ 9, 7 ] ] ) # 索引的二维阵列
a[j] # 相同的形状为J
# -----当索引数组a是多维时,单个索引数组指向a的第一维。 以下示例通过使用调色板将标签图像转换为彩色图像来显示此行为。--------#
palette = np.array( [ [0,0,0], # 黑色
[255,0,0], # 红色
[0,255,0], # 绿色
[0,0,255], # 蓝色
[255,255,255] ] ) # 白色
image = np.array( [ [ 0, 1, 2, 0 ], # 每一值对应于在调色板中的颜色
[ 0, 3, 4, 0 ] ] )
palette[image] # (2,43)彩色图像
# 可以给一个以上的维度指标。每个维度的索引数组必须具有相同的形状。
a = np.arange(12).reshape(3,4)
a
i = np.array( [ [0,1], # 用于第一暗淡的指数
[1,2] ] )
j = np.array( [ [2,1], # 第二个暗淡的指数
[3,3] ] )
a[i,j] #i和j必须具有相同的形状,a(0,2) =2 a(1,1)=5 ,a(1,3) =7 ,a(2,3) =11 最终结果-->array([[ 2, 5],[ 7, 11]])
a[i,2]#i和j必须具有相同的形状,a(0,2) =2 a(1,2)=6 , a(1,2)=6 ,a(2,2) =10 最终结果-->array([[ 2, 6], [ 6, 10]])
a[:,j] # i.e., a[ : , j]
# 可以把i和j放在一个序列中(比如说一个列表),然后用列表进行索引。
l = [i,j]
a[l] # 等同于[i,j]
s = np.array([i,j])
a[s] # 出错,不能通过将i和j放入一个数组。
a[tuple(s)] # 相同作为[i,j]
# 数组索引的另一个常见用途是搜索时间相关系列的最大值:
time = np.linspace(20, 145, 5) # 时标
data = np.sin(np.arange(20)).reshape(5,4) # 4随时间变化的一系列
time
data
ind = data.argmax(axis=0) # 每个系列最大值的索引
ind
time_max = time[ind] # 对应于最大值的次数
data_max = data[ind, range(data.shape[1])] # => data[ind[0],0], data[ind[1],1]...
time_max
data_max
np.all(data_max == data.max(axis=0))
# 使用数组的索引作为分配给的目标:
a = np.arange(5)
a
a[[1,3,4]] = 2
a
# 当索引列表包含重复时,分配会执行好几次,而留下最后一个值
a = np.arange(5)
a #输出array([0, 1, 2, 3, 4])
#索引0 更为为1,第二次索引更改为2,所以数组的a处的零索引取值为原数组的为2索引的值:2 ,然后索引2处的数改为索引3的数,
a[[0,0,2]]=[1,2,3]
a
# 这足够合理,但要小心如果你想使用Python的 + =构造,因为它可能不会做你期望的:
a = np.arange(5)
a[[0,0,2]]+=1
a
# 布尔索引最自然的方法就是使用与原始数组形状相同的布尔数组:
a = np.arange(12).reshape(3,4)
b = a > 4
b # b为具有的形状的布尔
a[b] # 一维数组与选定的元素
# 这个属性在作业中非常有用:
a[b] = 0 #'A'大于4的所有元素用零代替
a
# 使用布尔索引来生成Mandelbrot集的图像:
def mandelbrot( h,w, maxit=20 ):
"""返回Mandelbrot分形的图像大小(h,w )."""
y,x = np.ogrid[ -1.4:1.4:h*1j, -2:0.8:w*1j ]
c = x+y*1j
z = c
divtime = maxit + np.zeros(z.shape, dtype=int)
for i in range(maxit):
z = z**2 + c
diverge = z*np.conj(z) > 2**2 # 正在发偏离的人
div_now = diverge & (divtime==maxit) # 现在偏离的人
divtime[div_now] = i # 注意何时
z[diverge] = 2 # 避免偏离太多
return divtime
plt.imshow(mandelbrot(400,400))
plt.show()
# 用布尔值编制索引的第二种方法更类似于整数索引; 对于数组的每个维度,我们给出一个1D布尔数组,选择我们想要的切片:
a = np.arange(12).reshape(3,4)
a
b1 = np.array([False,True,True]) # 第一个dim选择
b1
b2 = np.array([True,False,True,False]) # 第二个dim选择
b2
a[b1,:] # 选择行(b1([False, True, True]),第一行不显示
a[b1] # 一样
a[:,b2] # 选择列
a[b1,b2] # 一个奇怪的事情要做
# ix_()函数:该ix_函数可用于不同的载体结合,以便获得对于每一个n-uplet结果。
# 例如,如果要计算从每个矢量a,b和c取得的所有三元组的所有a + b * c:
a = np.array([2,3,4,5])
b = np.array([8,5,4])
c = np.array([5,4,6,8,3])
ax,bx,cx = np.ix_(a,b,c)
ax
bx
cx
ax.shape, bx.shape, cx.shape
result = ax+bx*cx
result
# 你也可以按如下方式执行reduce:
def ufunc_reduce(ufct, *vectors):
vs = np.ix_(*vectors)
r = ufct.identity
for v in vs:
r = ufct(r,v)
return r
ufunc_reduce(np.add,a,b,c)
# 用字符串索引
# ----参考:https://docs.scipy.org/doc/numpy-dev/user/basics.rec.html#structured-arrays
# 线性代数
a = np.array([[1.0, 2.0], [3.0, 4.0]])
a
a.transpose() #x,y转换
np.linalg.inv(a)
u = np.eye(2) # 2×2矩阵; “眼睛”代表“我”
u
j = np.array([[0.0, -1.0], [1.0, 0.0]])
np.dot (j, j) # 矩阵产品
np.trace(u) # 返回数组的对角线的和。
y = np.array([[5.], [7.]])
np.linalg.solve(a, y)
np.linalg.eig(j)
# 参数:
# 方矩阵
# 返回
# 特征值,每个特征根据其多重性重复。
# 归一化的(单位“长度”)特征向量,
# 列``v [:,i]`是对应的特征向量
# 特征值``w [i]``。
# 技巧和提示: 要更改数组的尺寸,可以省略其中一个尺寸,然后自动推导出这些尺寸
a = np.arange(30)
a.shape = 2,-1,3 # -1表示“任何需要”
a.shape
a
# 矢量堆叠
x = np.arange(0,10,2) # x=([0,2,4,6,8])
y = np.arange(5) # y=([0,1,2,3,4])
m = np.vstack([x,y]) # m=([[0,2,4,6,8],
# [0,1,2,3,4]])
xy = np.hstack([x,y]) # xy =([0,2,4,6,8,0,1,2,3,4])
# 直方图
# #构建10000个正常偏离的矢量方差0.5 ^ 2和平均2
mu, sigma = 2, 0.5
v = np.random.normal(mu,sigma,10000)
# #绘制一个规格化的直方图与50箱
plt.hist(v, bins=50, normed=1) # matplotlib版本(图)
plt.show()
# #用numpy计算直方图,然后绘制
(n, bins) = np.histogram(v, bins=50, normed=True) # #NumPy版本(无图)
plt.plot(.5*(bins[1:]+bins[:-1]), n)
plt.show()
###################
# 使用pickle序列化numpy array
import pickle
x = np.arange(10)
x
f = open('x.pkl', 'wb')
pickle.dump(x, f) #b把x数组序列化到磁盘上为x.pkl文件
f = open('x.pkl', 'rb')
pickle.load(f) #在从文件中反序列化回来
np.save('one_array', x) #通过save方法来进行序列化到磁盘
np.load('one_array.npy') #通过load方法直接反序列化
y = np.arange(20)
np.savez('two_array.npz',a=x,b=y) #可以压缩多个数组到一个文件当当中
c = np.load('two_array.npz')
c['a']
c['b']
a =np.array([(1.5, 2, 3), (6, 4, 8)]) #数组将序列序列转换成二维数组,将序列序列转换成三维数组,等等
a
a.sort()
a
a.dtype
type(a)