使用代理
为啥要使用代理,是因为我们谷歌浏览器可以通过插件配置好代理,我们通过谷歌浏览器访问的所有网站请求,都会经过mitmproxy,但是我们写的脚本和shell 不会,所以需要告诉大家 如何在程序上加代理。我们程序访问的所有网站urL和接口都会经过mitmproxy-代理服务器,这样才能进行保存我们的所有记录,过滤,统计等额外操作。
curl --proxy http://127.0.0.1:8080 "http://wttr.in/Innsbruck?0" UI自动化加代理
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://127.0.0.1:8080")
#你如果代理服务器多
proxy_arr = [
'--proxy-server=http://60.168.81.177:1133',
'--proxy-server=http://118.212.107.177:9999',
'--proxy-server=http://36.248.132.145:9999',
'--proxy-server=http://163.125.112.207:8118',
'--proxy-server=http://119.134.110.69:8118',
'--proxy-server=http://123.163.27.101:9999',
'--proxy-server=http://1.198.73.167:9999'
]
proxy = random.choice(proxy_arr) # 随机选择一个代理
chrome_options.add_argument('--proxy-server='+proxy)
browser = webdriver.Chrome(options=chrome_options)Requests模块代理:接口自动化加代理
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('http://example.org', proxies=proxies)插件
Mitmproxy 的插件机制由一组支持任何复杂性组件的 API 组成。插件通过响应事件与 mitmproxy 交互,这允许它们连接并更改 mitmproxy 的行为
如果你想要实现,抓取特定的接口、内容、保存到你想要保存的地方。
你要使用mitmproxy,给我们的提供的插件功能,这个插件就是一个py程序
在这个py程序中,你可以定义好抓取内容,存储到哪的逻辑代码。 在开启mitmproxy 的同时指定脚本一起运行。
控制台执行命令:
mitmdump -s ./proxy_util.py建议把mitmdump 配置到环境变量里面,要不然每次启动还得切换到mitmdump的安装目录甚是麻烦。
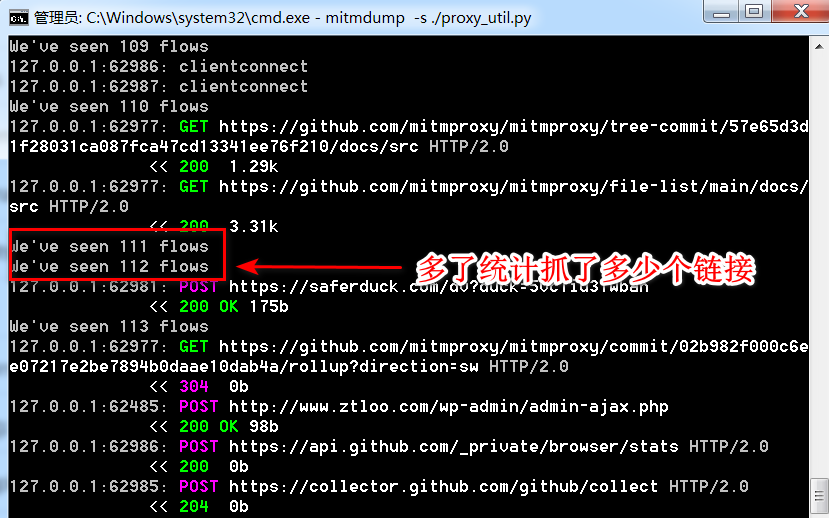
proxy_util.py 脚本长这样:
"""
Basic skeleton of a mitmproxy addon.
Run as follows: mitmproxy -s proxy_util.py
"""
from mitmproxy import ctx
class Counter:
def __init__(self):
self.num = 0
def request(self, flow):
self.num = self.num + 1
ctx.log.info("We've seen %d flows" % self.num)
addons = [
Counter()
]
"""
关于上面的代码,有几点需要注意:
Mitmproxy 获取addons全局列表的内容并将其找到的内容加载到插件机制中。
插件只是对象——在这种情况下,我们的插件是Counter.
该request方法是一个事件的例子。插件只是为他们想要处理的每个事件实现一个方法。
每个事件都有一个由传递给方法的参数组成的签名。因为request,这是 的一个实例mitmproxy.http.HTTPFlow。
最后,该ctx模块是一个holdall 模块,它公开了一组在插件中常用的标准对象。我们可以将一个ctx对象作为第一个参数传递给每个事件,但我们发现将其公开为可导入的全局对象更为简洁。在这种情况下,我们使用该ctx.log对象来进行日志记录。
"""
插件之给response添加header
"""Add an HTTP header to each response."""
class AddHeader:
def __init__(self):
self.num = 0
def response(self, flow):
self.num = self.num + 1
flow.response.headers["count"] = str(self.num)
addons = [
AddHeader()
]
支持的事件
这列只说明我们用到的HTTP事件,*(还包括通用事件和webscocket事件,不过我们自动化项目暂时用不到),如果需要请看官方文档,下面给出具体链接:
https://docs.mitmproxy.org/archive/v5/addons-events/
上面插件里已经包含了了两个事件
request 客户端请求事件、response服务端返回数据事件
我们用这些事件,就可以轻松拦截用户的请求,获取服务端返回的数据篡改、保存到我们想要保存的地方一些列操作,操控性,可玩性大大增加。其实核心的我们知道request和response 怎么用就行了。
具体所有1HTTP事件如下:
"""HTTP-specific events."""
import mitmproxy.http
class Events:
def http_connect(self, flow: mitmproxy.http.HTTPFlow):
"""
An HTTP CONNECT request was received. Setting a non 2xx response on
the flow will return the response to the client abort the
connection. CONNECT requests and responses do not generate the usual
HTTP handler events. CONNECT requests are only valid in regular and
upstream proxy modes.
"""
def requestheaders(self, flow: mitmproxy.http.HTTPFlow):
"""
HTTP request headers were successfully read. At this point, the body
is empty.
"""
def request(self, flow: mitmproxy.http.HTTPFlow):
"""
The full HTTP request has been read.
"""
def responseheaders(self, flow: mitmproxy.http.HTTPFlow):
"""
HTTP response headers were successfully read. At this point, the body
is empty.
"""
def response(self, flow: mitmproxy.http.HTTPFlow):
"""
The full HTTP response has been read.
"""
def error(self, flow: mitmproxy.http.HTTPFlow):
"""
An HTTP error has occurred, e.g. invalid server responses, or
interrupted connections. This is distinct from a valid server HTTP
error response, which is simply a response with an HTTP error code.
"""有了这些事件,我们就可以做很多事情了,比如可以获取到用户与服务端链接状态。获取请求的header,获取到用户请求失败的状态码啊,等等。
脚本
脚本是插件的进阶,之前的插件,都需要创建个类,还得再结尾添加
addons = [Counter()],非常的麻烦,为了简化这一操作,mitmproxy 有个脚本的概念。
有时,我们想编写一个快速的脚本,而不用经历创建类的麻烦。插件机制有一个简写,它允许将一个模块作为一个整体视为一个插件对象。这让我们可以在模块范围内放置事件处理函数。例如,这是一个完整的脚本,它为每个请求添加了一个标头。
案例:截获对特定 URL 的请求并发送任意响应的示例
"""Send a reply from the proxy without sending any data to the remote server."""
from mitmproxy import http
def request(flow: http.HTTPFlow) -> None:
if flow.request.pretty_url == "http://example.com/path":
flow.response = http.HTTPResponse.make(
200, # (optional) status code
b"Hello World", # (optional) content
{"Content-Type": "text/html"} # (optional) headers
)API
官方文档他没有提供API脚本中flow对象包含那些属性和方法的,原文说浪漫我们自己参考源码自己看就OK了。
官方的原话是酱紫:
本文档将向您展示如何使用事件、选项 和命令构建插件。但是,这不是 API 手册,mitmproxy 源代码仍然是规范参考。从命令行探索 API 的一种简单方法是使用pydoc。例如,这里是一个显示 mitmproxy 的 HTTP 流类的 API 文档的命令:
好吧,我们使用
python -m pydoc mitmproxy.http
好了,官方文档也比较简单,也就这么多。
备注
这个还是比较重点,有的小伙伴不会编程,工作中也需要经常抓包改包,fiddler、charles 也是能够满足,如果你想要非常的灵活的抓包,假设服务端抓包、架设服务端抓包功能,一定要在linux 安装mitmproxy ,因为windows不支持在cmd窗口中,进行命令式交互,只有linux 支持。
但是因为我们的项目是需要全脚本,无手工参与的自动化过程,所以可以安装在windows。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~






