一、目录切换、清屏,与手册学习
|
1、cd
|
切换到root目录,也可以执行cd ~
|
|
2、cd /
|
切换到根目录
|
|
3、cd -
|
切换到上回使用的目录
|
|
4、pwd
|
显示当前目录
|
|
5、cd /usr/local/
|
切换到相对路径
|
|
6、cd mysql
|
当前在local目录下,执行相对路径 |
|
7、stat hello
|
显示当前文件的详细信息,跟windows的文件信息一样,唯独没有创建时间。
最近访问(atime: 最后一次访问(仅仅是访问,没有改动)文件的时间)、
最近更改(mtime:表示我们最后一次修改文件的时间)。
最近改动(ctime:表示我们最后一次对文件属性改变的时间,包括权限,大小,属性等等)
注意:ls参数里没有--mtime这个参数,因为我们默认通过ls -l查看到的时间就是mtime 。
|
|
8、clear
|
清屏操作
|
|
9、man ls
|
打开 ls 命令的学习手册。
|
二、文件与目录展示
|
1、ls
|
用来显示目标列表
|
|
2、ls -a
|
显示所有档案及目录,将名称为“.”的视为影藏,不会列出
|
|
3、ls -A
|
显示除隐藏文件之外的所有文件
|
|
4、ls -c
|
与“-lt”选项连用时,按照文件状态时间排序输出目录内容,排序的依据是文件的索引节点中的ctime字段。与“-l”选项连用时,则排序的依据是文件的状态改变时间;
|
|
5、ls -C
|
多列显示输出结果。这是默认选项;
|
|
6、ls -d
|
d选项是显示当前目录名称,一般与l 选项连用,用来查看某个文件的详情
|
|
7、ls -f
|
对输出的文件不进行排序,-aU 选项生效,-lst 选项失效
|
|
8、ls -F
|
在每个输出项后追加文件的类型标识符.具体含义:
“*”表示具有可执行权限的普通文件,“/”表示目录,
“@”表示符号链接,
“|”表示命令管道FIFO,
“=”表示sockets套接字。
当文件为普通文件时,不输出任何标识符;
小技巧:ls -F --color 可以很快确定目录中有哪些文件
|
|
9、ls -g
|
不打印所有者信息,就是好比ls -l 少了用户信息。
|
|
10、ls -h
|
与-l 一起,以易于阅读的格式输出文件大小,会显示体积单位的
|
|
11、ls -i
|
显示文件索引节点号(inode)。一个索引节点代表一个文件
|
|
12、ls -k
|
以KB(千字节)为单位显示文件大小它默认。
|
|
13、ls -l
|
所有输出信息用单列格式输出,跟C相反。
输出的信息从左到右依次包括
文件名,文件类型、权限模式、硬连接数、所有者、组、文件大小和文件的最后修改时间等;
|
|
14、ls -m
|
用“,”号区隔每个文件和目录的名称;
|
|
15、ls -n
|
用编号显示组合用户
|
|
16、ls -o
|
类似 -l,但不列出所有者信息。
|
|
17、ls -p
|
对目录加上表示符号"/", 建议直接用 ls -F
|
|
18、ls -r
|
以文件名反排序,降序,例如文件头字母以z-a
|
|
19、ls -R
|
递归处理,将指定目录下的所有文件及子目录一并处理;
|
|
20、ls -s
|
显示文件和目录的大小,以区块为单位
|
|
21、ls -S
|
按照文件大小排序,默认是降序大到小,升序是加个 -r.
|
|
22、ls -t
|
用文件和目录按照最新的更改时间排序;
|
|
23、ls -u
|
-u with -lt:排序和显示访问时间;
with -l:显示访问时间并按名称排序;
否则:按访问时间排序
|
|
24、ls -U
|
不要排序; 按目录顺序列出条目
|
|
25、ls -x
|
按行而不是按列列出条目
|
|
26、ls -X
|
按条目扩展名按字母顺序排序
|
|
27、ls --full-time
|
列出完整的日期与时间;
|
|
28、ls --color=auto
|
使用不同的颜色高亮显示不同类型的。默认是auto、 never、 always
|
|
29、ls -lL
|
L只 显示符号链接的 源目录.
|
|
30、ls -la
|
列出所有文件目录的详细信息
|
|
31、ls -lart
|
输出并按照时间从旧到新,并按文件名倒序全部文件详细内容。
|
|
32、ls -Salh
|
输出全部文件,按照文件大小进行倒序排序
|
|
33、ls *mysql*
|
使用通配符,列出全部目录文件
|
|
34、cat hello
|
展示hello文件内的内容。
|
|
35、cat m1 m2
|
同时显示文件ml和m2的内容,m1的文件尾下面就是m2的头行,如果要有分开点,可以在文件顶部有个空白行等。
|
|
36、cat m1 m2 > m3
|
将m1 和m2 文件的内容拼接成文件m3
|
|
37、more +4 /etc/profile
|
注:从profile的第4行开始显示;
|
|
38、more -dc file
|
|
|
39、more -c -10 file
|
显示文件file的内容,每10行显示一次,而且在显示之前先清屏
|
|
40、more +/MAIL /etc/profile
|
注:从profile中的第一个MAIL单词的前两行开始显示;
|
|
41、history | less
|
分页显示 在此系统中使用过的命令。
|
|
42、less log2013.log log2014.log
|
浏览多个文件, 输入:n 切换到下一页,输入 :p切换到上一页。别忘记 输入 分号。
|
|
43、head file
|
查看文件前10行的内容
|
|
44、head -n 2 m1 m2
|
查看多个文件的前2行内容,==> m1 <== 以这种格式来区分每个文件。
|
|
45、head -c 100 file1
|
查看某个文件前100个字节的内容,
|
|
46、head -c 100KB file1
|
查看某个文件前100kb的内容,
|
|
47、head -c 100MB file1
|
查看某个文件前100MB的内容
|
|
48、tail file
|
查看文件后10行的内容
|
|
49、 tail -n 2 m1 m2
|
查看m1,m2文件的后两行内容。注意,空白行也算。
|
|
50、tail -f file
|
根据文件描述符进行追踪,当文件改名或被删除,追踪停止
|
|
51、 tail -F
|
根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
|
|
52、tailf file
|
如果文件不增长,它不会去访问磁盘文件,所以tailf特别适合那些便携机上跟踪日志文件,因为它减少了磁盘访问,可以省电。
|
|
53、tail -f --pid=2112 /var/log/apache/error.log
|
在阿帕奇服务器进程停止时,tail将停止监控,你需要具体的文件和生成文件得pid。
|
cat选项
-A, --show-all 等于-vET
-b, --number-nonblank 对非空输出行编号
-e 等于-vE
-E, --show-ends 在每行结束处显示"$"
-n, --number 对输出的所有行编号
-s, --squeeze-blank 不输出多行空行
-t 与-vT 等价
-T, --show-tabs 将跳格字符显示为^I
-u (被忽略)
-v, --show-nonprinting 使用^ 和M- 引用,除了LFD和 TAB 之外
--help 显示此帮助信息并退出
--version 显示版本信息并退出
MORE选项
选项:
-d 显示帮助,而不是响铃
-f 统计逻辑行数而不是屏幕行数
-l 抑制换页(form feed)后的暂停
-p 不滚屏,清屏并显示文本
-c 不滚屏,显示文本并清理行尾
-u 抑制下划线
-s 将多个空行压缩为一行
-NUM 指定每屏显示的行数为 NUM
+NUM 从文件第 NUM 行开始显示
+/STRING 从匹配搜索字符串 STRING 的文件位置开始显示
-V 输出版本信息并退出
MORE.常用操作命令:
Enter 向下n行,需要定义。默认为1行
Ctrl+F 向下滚动一屏
空格键 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
V 调用vi编辑器
!命令 调用Shell,并执行命令
q 退出more
LESS选项和按键命令
-b <缓冲区大小> 设置缓冲区的大小
-e 当文件显示结束后,自动离开
-f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
-g 只标志最后搜索的关键词
-i 忽略搜索时的大小写
-m 显示类似more命令的百分比
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-Q 不使用警告音
-s 显示连续空行为一行
-S 行过长时间将超出部分舍弃
-x <数字> 将"tab"键显示为规定的数字空格
|
按键命令
|
操作
|
|
(下箭头,e)、上箭头
|
前进一行、后退一行 |
|
空格、pg dn
|
前进一页
|
|
b、pg up
|
后退一页
|
|
g、1G
|
回到文件的开始
|
|
G
|
前进到文件的结尾
|
|
Q
|
退出
|
|
左箭头、右箭头
|
向左滚动、向右滚动
|
|
n
|
重复前一个搜索(与 / 或 ? 有关)
|
|
N
|
反向重复前一个搜索(与 / 或 ? 有关)
|
|
v
|
进入编辑模式,使用配置的编辑器编辑当前文件
|
|
ma
|
标记当前位置
|
|
'a
|
直接导航到标记位置 |
|
/字符串
|
向前搜索"字符串"的功能
|
|
?字符串
|
向后搜索"字符串"的功能
|
|
/正则表达式
|
向前用正则表达式功能搜索 |
三、文件与目录权限
ls -l 中显示的内容如下:
|
-rwxrw-r‐- 1 root root 1213 Feb 2 09:39 abc
|
- 10个字符确定不同用户能对文件干什么
- 第一个字符代表文件(-)、目录(d),链接(l)
- 其余字符每3个一组(rwx),读(r)、写(w)、执行(x)
- 第一组rwx:文件所有者的权限是读、写和执行
- 第二组rw-:与文件所有者同一组的用户的权限是读、写但不能执行
- 第三组r--:不与文件所有者同组的其他用户的权限是读不能写和执行
也可用数字表示为:r=4,w=2,x=1 因此rwx=4+2+1=7
- 1 表示连接的文件数
- root 表示用户
- root表示用户所在的组
- 1213 表示文件大小(字节)
- Feb 2 09:39 表示最后修改日期
- abc 表示文件名
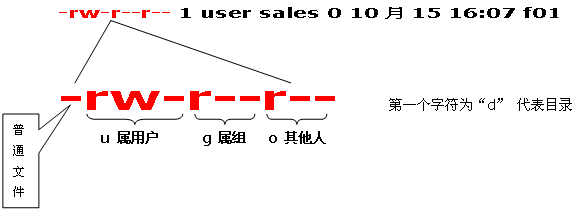
例:rwx rw- r--
r=读取属性 //值=4
w=写入属性 //值=2
x=执行属性 //值=1
chmod u+x,g+w f01 //为文件f01设置自己可以执行,组员可以写入的权限
chmod u=rwx,g=rw,o=r f01
chmod 764 f01
chmod a+x f01 //对文件f01的u,g,o都设置可执行属性
chown user:market f01 //把文件f01给uesr,添加到market组
1、chgrp(转变文件所属用户组)
2、chown(转变文件拥有者)
3、chmod(变动文件属性)
4、查看对应用户和组。
cat /etc/passwd|grep -v nologin|grep -v halt|grep -v shutdown|awk -F":" '{ print $1"|"$3"|"$4 }'|more
|
1、su username
|
切换到另一个与用户
|
|
2、whoami
|
检查当前用户名称
|
|
3、su -l username
|
切换到另一个用户,并且使用其环境变量
|
|
4、su
|
直接切换到root用户
|
|
5、su -
|
直接切换到root用户 并使用root用户下的环境变量
|
|
6、 groups
|
查看当前用户所在组
|
|
7、chgrp -R mengxin /usr/meng
|
将/usr/meng及其子目录下的所有文件的用户组改为mengxin。对目录,文件等都有效。
|
|
8、 chown -R liu /usr/meng
|
将目录/usr/meng及其下面的所有文件、子目录的文件主改成 liu:
|
|
9、chmod mysql:mysql mysql-files
|
给这个mysql-files 文件,更改至mysql用户和mysql组当中。第一个mysql是用户,第二个mysql是组。
|
四、文件与目录操作
|
1、mkdir /usr/local/test
|
创建单个目录
|
|
2、mkdir -pv /usr/local/test{A,B}
|
创建多个目录,v选项是显示创建过程
|
|
3、tocuh ztloo.txt
|
如果此文件不存在创建一个空的文件,否则更新此文件时间为系统当前时间。
|
|
4、touch -r log.log log2012.log
|
更新log.log的时间和log2012.log时间戳相同,
r选项:把指定文档或目录的日期时间,统统设成和参考文档或目录的日期时间相同
|
|
5、touch -t 201809252154 hello
|
修改hello文件的mtime 时间为任意时间 。
|
|
6、cp hello /usr/local/test/hello
|
把hello文件复制到test目录下。注意在相同目录下cp hello hello 是不允许的。
|
|
7、cp ~/pictures/dogs/ztloo*.jpg .
|
把root用户图片目录下前缀为ztloo的jpg图片复制到当前目录。
“.”表示当前目录
|
|
8、cp ~/pictures/dogs/ztloo_0[1-3].jpg .
|
匹配ztloo_01、ztloo_02、ztloo_03 的jpg复制到当前目录。
显示复制文件的过程就 加v选项,cp -v
|
|
9、cp -r /usr/men /usr/zh
|
(r选项可以复制目录)将目录/usr/men下的所有文件及其子目录复制到目录/usr/zh中
|
|
10、cp -i /usr/men m*.c /usr/zh
|
交互式地将目录/usr/men中的以m打头的所有.c文件复制到目录/usr/zh中。遇到相同文件内容每次都会提示是否覆盖。
|
|
11、 cp -r -a test/* testA
|
强制覆盖,即使有相同文件也不询问,在cp 前面加个 就可以。 -a 选项可以传递目录以及子目录和文件的属性。
|
|
12、cp -n test/* testA
|
test目录下和testA目录下有相同文件,也不会询问直接跳过相同的文件。
|
|
13、 cp -u -v file1 file2
|
只在源文件比目标文件新,或目标文件不存在时才进行复制
|
|
14、 cp -p a.txt tmp/
|
复制时保留文件属性
|
|
15、 cp -P /var/tmp/a.txt ./temp/
|
复制时保留文件的目录结构
|
|
16、cp -bv file1 file2
|
如果file2 和file1 内容相同,这时候加-b选项,在覆盖的过程中,会先把file2 备份到file2的当前目录,结尾以 ~结尾。
|
|
17、mv ex3 new1
|
将文件ex3改名为new1。文件和目录同样适用。
|
|
18、mv /usr/men/* .
|
将目录/usr/men中的所有文件移到当前目录(用.表示)中:
|
|
19、mv info/ logs
|
将info目录放入logs目录中。注意,如果logs目录不存在,则该命令将info改名为logs。
|
|
20、 ln -s source target
|
创建软连接,类似于windows上的一个快捷方式。
|
|
21、 ln source target
|
创建硬链接( 硬链接则透过文件系统的inode来产生新档名,而不是产生新档案。)
|
|
22、ln /mub1/m2.c /usr/liu/a2.c
|
在执行ln命令之前,目录/usr/liu中不存在a2.c文件。执行ln之后,在/usr/liu目录中才有a2.c这一项,表明m2.c和a2.c链接起来(注意,二者在物理上是同一文件),利用ls -l命令可以看到链接数的变化
|
|
23、ln -s /usr/mengqc/mub1 /usr/liu/abc
|
在目录/usr/liu下建立一个符号链接文件abc,使它指向目录/usr/mengqc/mub1 执行该命令后,/usr/mengqc/mub1代表的路径将存放在名为/usr/liu/abc的文件中。
|
|
24、rm -d test
|
test 目录为空才可以删除
|
|
25、rm -r *
|
删除当前目录下除隐含文件外的所有文件和子目录 (默认是 “i”),每个文件都询问
|
|
26、rm -rf *
|
同25,加了f选项,强制删除,当前目录所有文件,不带询问的。注意,这样做是非常危险的。
|
|
27、rm "hello world"
|
删除不好删除的文件1、删除名称中带有空格的文件,将文件的名称用双引号括起来,
|
|
28、rm -- -hello.jpg
|
删除不好删除的文件2、删除名称以 横杆开头- 的文件, 在有问题的名称前面加 --,告诉rm命令跟在其后的任何字符都不应该视为选项。
|
|
29、mkdir $(date "+%Y-%m-%d")
|
将一条命令的输出作为参数插入另一条命令当中, $() ,可以嵌套。可以在$() 内部放入另一个$() 、
|
|
30、ls -l | less
|
将一条命令的输出作为用作另一条命令的输入。把ls -l的输出结果传递给less.如果目录太多,就用less分屏分页显示
|
|
31、 ls -lF testA/ > testA.txt
|
信息重定向到文件:将testA目录下的所有文件信息都打印到testA.txt 文件当中。注意:如果文件存在,会出现完全被覆盖。有一种方法可以防止。#>set -o noclobber 每次执行覆盖会提示。不喜欢可以关闭:
set +o noclobber
|
|
32、date >> testA.txt
|
内容追加:在上面testA.txt 里面包含目录 的信息,在末尾追加一个 当前系统的时间信息。
|
|
33、tr 'A-Z' 'a-z' < testA.txt > testA_tr.txt
|
将命令作用到文件中,将文件中的大写英文字母改成小写英文字母。 注意:如使用命令是输入到stdout,还得进行重定向一个不重名的文件中。变更的最后内容在:testA_tr.txt 文件中,
|
|
34、ls -lF testA/ | tee testA.txt
|
将输出同时发送到文件和stdout中,31 的的另一种形式,相当于在31的基础上加了个cat命令。
|
额外需要知道的知识:
在linux中经常会看到stdin,stdout和stderr,这3个可以称为终端(Terminal)的标准输入(standard input),标准输出( standard out)和标准错误输出(standard error)。
组合命令
多条命令之间以“;”间隔,就组成组合命令,依次执行,上条语句执行成功与否不影响下个语句的执行。
如果使用“&&”代替“;”,在上条语句执行成功的前提下才能执行下条命令
当用“||”代替“;”时,上条命令执行失败时才能执行下条语。
Touch命令
-a:或--time=atime或--time=access或--time=use 只更改存取时间;
-c:或--no-create 不建立任何文件;
-d:<时间日期> 使用指定的日期时间,而非现在的时间;
-f:此参数将忽略不予处理,仅负责解决BSD版本touch指令的兼容性问题;
-m:或--time=mtime或--time=modify 只更该变动时间;
-r:<参考文件或目录> 把指定文件或目录的日期时间,统统设成和参考文件或目录的日期时间相同;
-t:<日期时间> 使用指定的日期时间,而非现在的时间;
--help:在线帮助;
--version:显示版本信息。
CP命令
cp(选项)(参数)
参数:
源文件:制定源文件列表。默认情况下,cp命令不能复制目录,如果要复制目录,则必须使用-R选项;
目标文件:指定目标文件。当“源文件”为多个文件时,要求“目标文件”为指定的目录。
-a:此参数的效果和同时指定"-dpR"参数相同;
-d:当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录;
-f:强行复制文件或目录,不论目标文件或目录是否已存在;
-i:覆盖既有文件之前先询问用户;
-l:对源文件建立硬连接,而非复制文件;
-p:保留源文件或目录的属性;
-R/r:递归处理,将指定目录下的所有文件与子目录一并处理;
-s:对源文件建立符号连接,而非复制文件;
-u:使用这项参数后只会在源文件的更改时间较目标文件更新时或是名称相互对应的目标文件并不存在时,才复制文件;
-S:在备份文件时,用指定的后缀“SUFFIX”代替文件的默认后缀;
-b:覆盖已存在的文件目标前将目标文件备份;
-v:详细显示命令执行的操作。
MV命令
-b:当文件存在时,覆盖前,为其创建一个备份;
-f:若目标文件或目录与现有的文件或目录重复,则直接覆盖现有的文件或目录;
-i:交互式操作,覆盖前先行询问用户,如果源文件与目标文件或目标目录中的文件同名,则询问用户是否覆盖目标文件。用户输入”y”,表示将覆盖目标文件;输入”n”,表示取消对源文件的移动。这样可以避免误将文件覆盖。
--strip-trailing-slashes:删除源文件中的斜杠“/”;
-S<后缀>:为备份文件指定后缀,而不使用默认的后缀;
--target-directory=<目录>:指定源文件要移动到目标目录;
-u:当源文件比目标文件新或者目标文件不存在时,才执行移动操作。
LN命令
如果使用-s选项创建符号连接,则“源文件”可以是文件或者目录。创建硬连接时,则“源文件”参数只能是文件;
-b或--backup:删除,覆盖目标文件之前的备份;
-d或-F或——directory:建立目录的硬连接;
-f或——force:强行建立文件或目录的连接,不论文件或目录是否存在;
-i或——interactive:覆盖既有文件之前先询问用户;
-n或--no-dereference:把符号连接的目的目录视为一般文件;
-s或——symbolic:对源文件建立符号连接,而非硬连接;
-S<字尾备份字符串>或--suffix=<字尾备份字符串>:用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字符串是符号“~”,用户可通过“-S”参数来改变它;
-v或——verbose:显示指令执行过程;
-V<备份方式>或--version-control=<备份方式>:用“-b”参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这个字符串不仅可用“-S”参数变更,当使用“-V”参数<备份方式>指定不同备份方式时,也会产生不同字尾的备份字符串;
--help:在线帮助;
--version:显示版本信息。
RM命令
rm命令可以删除一个目录中的一个或多个文件或目录,也可以将某个目录及其下属的所有文件及其子目录均删除掉。对于链接文件,只是删除整个链接文件,而原有文件保持不变。
-d:直接把欲删除的目录的硬连接数据删除成0,删除该目录;
-f:强制删除文件或目录;
-i:删除已有文件或目录之前先询问用户;
-r或-R:递归处理,将指定目录下的所有文件与子目录一并处理;
--preserve-root:不对根目录进行递归操作;
-v:显示指令的详细执行过程。
软连接与硬链接区别
硬链接是有着相同 inode 号仅文件名不同的文件. 只能对已存在的文件进行创建,
删除一个硬链接文件并不影响其他有相同 inode 号的文件.
不能交叉文件系统进行硬链接的创建, 不能对目录进行创建,只可对文件创建.
[root@c7_m8_s1 local]# link hello hello2

五、使用过滤器操作文本
|
1、wc file
|
会显示file文件的行数、单词数、字符数
|
|
2、wc -w m3
|
只会显示m3 文件的单词数量。
|
|
3、wc -m m3
|
提供字符数量。
|
|
4、wc -l m3
|
显示行数。
|
|
5、wc m1 m2
|
分别显示m1、m2文件的行数,单词书,字符数,底部要有他俩文件的总计。
|
|
5.1 wc -c hello2
|
显示hello2 文件的byte字节大小。
|
|
6、grep JerkyJerks server_access.log | wc -l
|
找出名字为“JerkyJerks ”的网络蜘蛛对我的服务攻击了多少次。
|
|
7、nl -b a m2
|
对文件m2 进行编号,对空行也进行编号。
|
|
8、 cat /etc/passwd | cut -b1-3
|
取每行的第1-3字字节
|
| 9、cat /etc/passwd | cut -b1-3,5-7,8 |
取每行的第1-3,5-7,8的字节(后面的数字会先进行从小到大的排列) 需要事先知道具体字节,很容易出错
|
|
10、cat /etc/passwd | cut -d : -f 3
|
以:分割,取第三段
|
|
11、cat /etc/passwd | cut -d ''
|
以空格进行分割,且是一个空格。
|
|
12、cat song.txt |cut -nb 1,2,3
|
当 -b 添加 -n 后则不会分割多字节 (我的系统是utf-8,所以需要用三个字节来表示一个汉字)
|
|
13、cat /etc/passwd | cut -c1,3
|
适用于中文
|
|
14、sort sort.txt
|
sort将文件/文本的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
|
|
15、sort -u sort.txt
|
忽略相同行使用-u选项或者uniq:
|
|
16、du -d 1 -h | sort -n
|
查看当前深度为1 的目录的大小,并且从小到大进行排序
|
|
17、history | awk '{print $2}' | uniq -c > testHis.txt
|
删除文件中的重复行,并输出文件。-c 是重复的次数
|
|
18、cat tr.txt | tr a-z A-Z
|
把tr.txt文件中的小写字母转换成大写字母。另 也可以这样, tr [:lower:] [:upper:]
|
|
19、tr -s [:blank:] < tr.txt > trUp.txt
|
把tr.txt文件中有重复的空格,变成一个空格。-s选项只留一个指定的字符。
|
|
20、tr -d '[0-9]' < ghostwu.txt
|
删除了里面的数字。 |
|
21、sed '2a 106,dandan,CSO' person.txt
|
插入:在persion.txt 文件的第二行之后插入一行,下面的next+1.
|
|
22、sed '2c 106,dandan,CSO' person.txt
|
修改:修改persion.txt 文件的第二行
|
|
23、sed '2d' person.txt
|
删除:删除第二行内容。
|
|
24、sed -n '2p' person.txt
|
查找:第二行内容。 *(sed 的增删改查详细,请看下面案例。)
|
|
25、 awk [options] 'pattern{action}' filename
|
awk 使用方法。尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令
|
|
26、 awk -F: '{ print $1 }' /etc/passwd
 |
输出 以passwd文件冒号:为分隔符 输出 从左往右索引为1的列。
|
|
27、awk '{if(NR>=20 && NR<=30) print $1}' test.txt
|
只查看test.txt文件(100行)内第20到第30行的内容。
一样的效果:sed -n '29,30p' test.txt
|
|
28、awk '{count++;print $0;} END{print "user count is ",count}' /etc/passwd
|
统计 etc下passwd文件有多少账户。
|
|
29、ll | awk 'BEGIN{size=0;} {size=size+$5;} END{print "[end]size is ",size/1024/1024,"M"}'
|
统计某个文件夹下的文件占用的大小单位为mb。针对ls 列出的更为精确,和灵活。
|
|
30、yum install mlocate
|
安装快速文件查找工具,比find快很多,可用于。 updatedb 更新数据库存储的快照。
|
|
31、locate /etc/sh
|
搜索etc目录下所有以sh开头的文件
|
|
32、locate -i ~/m
|
搜索用户主目录下,所有以m开头的文件,并且忽略大小写:
|
|
33、updatedb
|
更新locate 使用的数据库
|
|
34、grep b hello2
|
在文中搜索一个包含字母‘b’的匹配行。
|
|
35、 echo this is a test line. | grep -o -E "[a-z]+."
|
只输出正则表达式输出的部分,用-o选项标识。 |
|
36、 grep ‘hei you’*
|
适用于当前目录的每个文件去查找。
|
|
37、grep -R ‘hei you’*
|
在36 的基础上,如遇到目录,也可以继续递归的找下去。 |
|
38、grep -i Bat hello2
|
在hello2 文件中搜索忽略大小写
|
|
39、grep -n pain *
|
搜索单词pain 在当前目录所有文件中的第几行。
|
|
40、grep -c "text" file_name
|
统计文件或者文本中包含匹配字符串的行数 -c 选项
|
|
41、grep -v "match_pattern" file_name
|
输出除之外的所有行 -v 选项:
|
|
42、grep -il "text" file1 file2 file3...
|
在众多文件中寻找包含text单词的文件,。
|
|
43、grep "text" . -r -n
|
在多级目录中对文本进行递归搜索: .表示当前目录。
|
|
44、echo this is a text line | grep -e "is" -e "line" -o
|
通过 -e 选项,一次可以匹配多个记录。 同时匹配 is 和line。
|
|
45、grep "main()" . -r --include *.{php,html}
|
#只在目录中所有的.php和.html文件中递归搜索字符"main()" |
|
46、grep "main()" . -r --exclude "README"
|
#在搜索结果中排除所有README文件
|
|
47、grep "main()" . -r --exclude-from filelist
|
#在搜索结果中排除filelist文件列表里的文件
|
|
48、#测试文件:echo "aaa" > file1 、 echo "bbb" > file2 、echo "aaa" > file3
grep "aaa" file* -lZ | xargs -0 rm
|
#执行后会删除file1和file3,grep输出用-Z选项来指定以0值字节作为终结符文件名(�),xargs -0 读取输入并用0值字节终结符分隔文件名,然后删除匹配文件,-Z通常和-l结合使用。
|
|
49、find /home -name "*.txt"
|
在/home目录下查找以.txt结尾的文件名
|
|
50、find /home -iname "*.txt"
|
同上,但忽略大小写
|
|
51、find . ( -name "*.txt" -o -name "*.pdf" ) 或者
find . -name "*.txt" -o -name "*.pdf"
|
当前目录及子目录下查找所有以.txt和.pdf结尾的文件
|
|
52、find . ! -name "*.jpg"
|
找出当前目录不是以.jgp结尾的文件
|
|
53、find . -user Scott
|
查找当前目录为scott 的用户的文件。
|
|
54、find . - group mysql
|
查找当前目录为mysql 组的文件。
|
|
55、find .
|
|
|
56、find . -type f -atime -7
|
搜索最近七天内被访问过的所有文件
|
|
57、find . -type 类型参数
|
类型参数列表:
f 普通文件
l 符号连接
d 目录
c 字符设备
b 块设备
s 套接字
p Fifo
|
|
58、 find . -type f -atime 7
|
搜索恰好在七天前被访问过的所有文件
|
|
59、find . -type f -atime +7
|
搜索超过七天内被访问过的所有文件
|
|
60、find . -type f -amin +10
|
搜索访问时间超过10分钟的所有文件
|
|
61、find . -maxdepth 3 -type f
|
向下最大深度限制为3
|
|
62、find . -mindepth 2 -type f
|
搜索出深度距离当前目录至少2个子目录的所有文件
|
|
63、find . -regex ".*(.txt|.pdf)$"
|
基于正则表达式匹配文件路径
|
|
64、find . -type f 时间戳
|
UNIX/Linux文件系统每个文件都有三种时间戳:
访问时间(-atime/天,-amin/分钟):用户最近一次访问时间。
修改时间(-mtime/天,-mmin/分钟):文件最后一次修改时间。
变化时间(-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。
|
|
65、find . -type f -size 文件大小单元
|
文件大小单元:
b —— 块(512字节)
c —— 字节
w —— 字(2字节)
k —— 千字节
M —— 兆字节
G —— 吉字节
|
|
66、find . -type f -size +10k
|
搜索大于10KB的文件
|
|
67、find . -type f -size -10k
|
搜索小于10KB的文件
|
|
68、find . -type f -size 10k
|
搜索等于10KB的文件
|
|
69、find . -type f -name "*.txt" -delete
|
删除当前目录下所有.txt文件
|
|
70、find . -type f -perm 777
|
当前目录下搜索出权限为777的文件
|
|
71、find . -type f -user root -exec chown mysql {} ;
|
找出当前目录下所有root的文件,并把所有权更改为用户mysql用户。
|
|
72、find . -type f -mtime +30 -name "*.log" -exec cp {} old ;
|
将30天前的.log文件移动到old目录中
|
|
73、find . -path "./sk" -prune -o -name "*.txt" -print
|
查找当前目录或者子目录下所有.txt文件,但是跳过子目录sk
|
|
74、find . -empty
|
要列出所有长度为零的文件
|
nl选项
-b, --body-numbering=样式 使用指定样式编号文件的正文行目
-d, --section-delimiter=CC 使用指定的CC 分割逻辑页数
-f, --footer-numbering=样式 使用指定样式编号文件的页脚行目
-h, --header-numbering=样式 使用指定样式编号文件的页眉行目
-i, --page-increment=数值 设置每一行遍历后的自动递增值
-l, --join-blank-lines=数值 设置数值为多少的若干空行被视作一行
-n, --number-format=格式 根据指定格式插入行号
-p, --no-renumber 在逻辑页数切换时不将行号值复位
-s, --number-separator=字符串 可能的话在行号后添加字符串
-v, --starting-line-number=数字 每个逻辑页上的第一行的行号
-w, --number-width=数字 为行号使用指定的栏数
a 对所有行编号
t 对非空行编号
n 不编行号
pBRE 只对符合正则表达式BRE 的行编号
FORMAT 是下列之一:
ln 左对齐,空格不用0 填充
rn 右对齐,空格不用0 填充
rz 右对齐,空格用0 填充
cut选项
-b, --bytes=列表 只选中指定的这些字节
-c, --characters=列表 只选中指定的这些字符
-d, --delimiter=分界符 使用指定分界符代替制表符作为区域分界
-f, --fields=LIST select only these fields; also print any line
that contains no delimiter character, unless
the -s option is specified
-n with -b: don't split multibyte characters
--complement 补全选中的字节、字符或域
-s, --only-delimited 不打印没有包含分界符的行
--output-delimiter=字符串 使用指定的字符串作为输出分界符,默认采用输入
的分界符
每种参数格式表示范围如下:
N 从第1 个开始数的第N 个字节、字符或域
N- 从第N 个开始到所在行结束的所有字符、字节或域
N-M 从第N 个开始到第M 个之间(包括第M 个)的所有字符、字节或域
-M 从第1 个开始到第M 个之间(包括第M 个)的所有字符、字节或域
sort 使用教程及选项
[root@mail text]# cat sort.txt
AAA:BB:CC
aaa:30:1.6
ccc:50:3.3
ddd:20:4.2
bbb:10:2.5
eee:40:5.4
eee:60:5.1
#将BB列按照数字从小到大顺序排列:
[root@mail text]# sort -nk 2 -t: sort.txt
AAA:BB:CC
bbb:10:2.5
ddd:20:4.2
aaa:30:1.6
eee:40:5.4
ccc:50:3.3
eee:60:5.1
#将CC列数字从大到小顺序排列:
[root@mail text]# sort -nrk 3 -t: sort.txt
eee:40:5.4
eee:60:5.1
ddd:20:4.2
ccc:50:3.3
bbb:10:2.5
aaa:30:1.6
AAA:BB:CC
# -n是按照数字大小排序,-r是以相反顺序,-k是指定需要爱排序的栏位,-t指定栏位分隔符为冒号
-b, --ignore-leading-blanks 忽略前导的空白区域
-d, --dictionary-order 只考虑空白区域和字母字符
-f, --ignore-case 忽略字母大小写
-g, --general-numeric-sort compare according to general numerical value
-i, --ignore-nonprinting consider only printable characters
-M, --month-sort compare (unknown) < 'JAN' < ... < 'DEC'
-h, --human-numeric-sort 使用易读性数字(例如: 2K 1G)
-n, --numeric-sort 根据字符串数值比较
-R, --random-sort 根据随机hash 排序
--random-source=文件 从指定文件中获得随机字节
-r, --reverse 逆序输出排序结果
--sort=WORD 按照WORD 指定的格式排序:
一般数字-g,高可读性-h,月份-M,数字-n,
随机-R,版本-V
-V, --version-sort 在文本内进行自然版本排序
其他选项:
--batch-size=NMERGE 一次最多合并NMERGE 个输入;如果输入更多
则使用临时文件
-c, --check, --check=diagnose-first 检查输入是否已排序,若已有序则不进行操作
-C, --check=quiet, --check=silent 类似-c,但不报告第一个无序行
--compress-program=程序 使用指定程序压缩临时文件;使用该程序
的-d 参数解压缩文件
--debug 为用于排序的行添加注释,并将有可能有问题的
用法输出到标准错误输出
--files0-from=文件 从指定文件读取以NUL 终止的名称,如果该文件被
指定为"-"则从标准输入读文件名
-k, --key=KEYDEF sort via a key; KEYDEF gives location and type
-m, --merge merge already sorted files; do not sort
-o, --output=文件 将结果写入到文件而非标准输出
-s, --stable 禁用last-resort 比较以稳定比较算法
-S, --buffer-size=大小 指定主内存缓存大小
-t, --field-separator=分隔符 使用指定的分隔符代替非空格到空格的转换
-T, --temporary-directory=目录 使用指定目录而非$TMPDIR 或/tmp 作为
临时目录,可用多个选项指定多个目录
--parallel=N 将同时运行的排序数改变为N
-u, --unique 配合-c,严格校验排序;不配合-c,则只输出一次排序结果
-z, --zero-terminated 以0 字节而非新行作为行尾标志
TR命令选项
用法:tr [选项]... SET1 [SET2]
从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
-c, -C, --complement 首先补足SET1
-d, --delete 删除匹配SET1 的内容,并不作替换
-s, --squeeze-repeats 如果匹配于SET1 的字符在输入序列中存在连续的
重复,在替换时会被统一缩为一个字符的长度
-t, --truncate-set1 先将SET1 的长度截为和SET2 相等
--help 显示此帮助信息并退出
--version 显示版本信息并退出
SET 是一组字符串,一般都可按照字面含义理解。解析序列如下:
NNN 八进制值为NNN 的字符(1 至3 个数位)
\ 反斜杠
a 终端鸣响
b 退格
f 换页
n 换行
r 回车
t 水平制表符
v 垂直制表符
字符1-字符2 从字符1 到字符2 的升序递增过程中经历的所有字符
[字符*] 在SET2 中适用,指定字符会被连续复制直到吻合设置1 的长度
[字符*次数] 对字符执行指定次数的复制,若次数以 0 开头则被视为八进制数
[:alnum:] 所有的字母和数字
[:alpha:] 所有的字母
[:blank:] 所有呈水平排列的空白字符
[:cntrl:] 所有的控制字符
[:digit:] 所有的数字
[:graph:] 所有的可打印字符,不包括空格
[:lower:] 所有的小写字母
[:print:] 所有的可打印字符,包括空格
[:punct:] 所有的标点字符
[:space:] 所有呈水平或垂直排列的空白字符
[:upper:] 所有的大写字母
[:xdigit:] 所有的十六进制数
[=字符=] 所有和指定字符相等的字符
仅在SET1 和SET2 都给出,同时没有-d 选项的时候才会进行替换。
仅在替换时才可能用到-t 选项。如果需要SET2 将被通过在末尾添加原来的末字符的方式
补充到同SET1 等长。SET2 中多余的字符将被省略。只有[:lower:] 和[:upper:]
以升序展开字符;在用于替换时的SET2 中以成对表示大小写转换。-s 作用于SET1,既不
替换也不删除,否则在替换或展开后使用SET2 缩减。
SED命令选项
用法: sed [选项]... {脚本(如果没有其他脚本)} [输入文件]...
-n, --quiet, --silent
取消自动打印模式空间
-e 脚本, --expression=脚本
添加“脚本”到程序的运行列表
-f 脚本文件, --file=脚本文件
添加“脚本文件”到程序的运行列表
--follow-symlinks
直接修改文件时跟随软链接
-i[SUFFIX], --in-place[=SUFFIX]
edit files in place (makes backup if SUFFIX supplied)
-c, --copy
use copy instead of rename when shuffling files in -i mode
-b, --binary
does nothing; for compatibility with WIN32/CYGWIN/MSDOS/EMX (
open files in binary mode (CR+LFs are not treated specially))
-l N, --line-length=N
指定“l”命令的换行期望长度
--posix
关闭所有 GNU 扩展
-r, --regexp-extended
在脚本中使用扩展正则表达式
-s, --separate
将输入文件视为各个独立的文件而不是一个长的连续输入
-u, --unbuffered
从输入文件读取最少的数据,更频繁的刷新输出
-z, --null-data
separate lines by NUL characters
--help
display this help and exit
--version
output version information and exit
如果没有 -e, --expression, -f 或 --file 选项,那么第一个非选项参数被视为
sed脚本。其他非选项参数被视为输入文件,如果没有输入文件,那么程序将从标准
输入读取数据。
sed案例详解
sed对于VI命令性能优越,一次打开一行。 常用功能有增删改查(增加,删除,修改,查询),其中查询的功能中最常用的2大功能是过滤(过滤指定字符串),取行(取出指定行0
[root@c7_m8_s1 local]# cat >person.txt<<KOF
>101,chensiqi,CEO
>102,zhangyang,CTO
>103,Alex,COO
>104,yy,CFO
>105,feixue,CIO
> KOF
[root@c7_m8_s1 local]#
# 在 第二行后面插入一行。
[root@c7_m8_s1 local]# sed '2a 106,dandan,CSO' person.txt
101,chensiqi,CEO
102,zhangyang,CTO
106,dandan,CSO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
# 直接把内容插入到第三行。
[root@c7_m8_s1 local]# sed '3i 107,ztl,ufo' person.txt
101,chensiqi,CEO
102,zhangyang,CTO
107,ztl,ufo
103,Alex,COO
104,yy,CFO
105,feixue,CIO
# 多行插入,已n 分隔
[root@c7_m8_s1 local]# sed '4a 108,dandan,CSOn109,bingbing,CCO' person.txt
101,chensiqi,CEO
102,zhangyang,CTO
103,Alex,COO
104,yy,CFO
108,dandan,CSO
109,bingbing,CCO
105,feixue,CIO
# 删除 第二行内容,,默认:sed ‘d’ 不指定行数,是删除所有行。
[root@c7_m8_s1 local]# sed '2d' person.txt
101,chensiqi,CEO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
#删除第二行到第五行的内容。
[root@c7_m8_s1 local]# sed '2,5d' person.txt
101,chensiqi,CEO
# 正则匹配删除 名字叫zhangyang 的信息。
[root@c7_m8_s1 local]# sed '/zhangyang/d' person.txt
101,chensiqi,CEO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
#命令说明: 在sed软件中,使用正则的格式和awk一样,使用2个”/“包含指定的正则表达式,即“/正则表达式/”。
#当然也可以使用两个正则表达式,如下例所示
[root@c7_m8_s1 local]# sed '/chensiqi/,/Alex/d' person.txt
104,yy,CFO
105,feixue,CIO
命令说明:这是正则表达式形式的多行删除,也是以逗号分隔2个地址,最后结果是删除包含“chensiqi”的行到包含“Alex”的行
#删除第三行到最后一行
[root@c7_m8_s1 local]# sed '3,$d' person.txt
101,chensiqi,CEO
102,zhangyang,CTO
命令说明:学过正则表达式后我们知道“$”代表行尾,但是在sed中就有一些变化了,“$”在sed中代表文件的最后一行。因此本例子的含义是删除第3行到最后一行的文本,包含第3行和最后一行,因此剩下第1,2行的内容。
#从第2行开始循环,sed软件第一次遇到字母O(第三行)就认为循环结束
[root@c7_m8_s1 local]# sed '2,/O/d' person.txt
101,chensiqi,CEO
104,yy,CFO
105,feixue,CIO
# 处理等差数列
[root@c7_m8_s1 local]# seq 10 | sed -n '1~2p'
1
3
5
7
9
# 修改第二行
[root@c7_m8_s1 local]# cat person.txt
101,chensiqi,CEO
102,zhangyang,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@c7_m8_s1 local]# sed '2c 106,dandan,CSO' person.txt
101,chensiqi,CEO
106,dandan,CSO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
#修改文中内容,将zhangyang 修改成 dandan
[root@c7_m8_s1 local]# sed 's#zhangyang#dandan#g' person.txt
101,chensiqi,CEO
102,dandan,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
默认sed软件是对模式空间(内存中的数据)操作,而-i选项会更改磁盘上的文件内容。
[root@c7_m8_s1 local]# sed -i 's#zhangyang#dandan#g' person.txt
[root@c7_m8_s1 local]# cat person.txt
101,chensiqi,CEO
102,dandan,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
* 这里用到的sed命令,选项:
“s”:单独使用-->将每一行中第一处匹配的字符串进行替换==>sed命令
“g”:每一行进行全部替换-->sed命令s的替换标志之一(全局替换),非sed命令。
“-i”:修改文件内容-->sed软件的选项,注意和sed命令i区别。
#把第三行的 0 修改成9
[root@c7_m8_s1 local]# sed '3s#0#9#' person.txt
101,chensiqi,CEO
102,dandan,CTO
193,Alex,COO
104,yy,CFO
105,feixue,CIO
# 变量
sed s#$x#$y#g test.txt
#分组替换()和1的使用说明
[root@c7_m8_s1 local]# echo "I am chensiqi teacher." | sed 's#^.*am ([a-z]+) tea.*$#1#g'
chensiqi
[root@c7_m8_s1 local]# echo "I am chensiqi teacher." | sed -r 's#^.*am ([a-z]+) tea.*$#1#g'
chensiqi
[root@c7_m8_s1 local]# echo "I am chensiqi teacher." | sed -r 's#I (.*) (.*) teacher.#12#g'
amchensiqi
命令说明: sed如果不加-r后缀,那么默认不支持扩展正则表达式,需要符号进行转义。小括号的作用是将括号里的匹配内容进行分组以便在第2和第3个#号之间进行sed的反向引用,1代表引用第一组,2代表引用第二组
# 取IP
[root@c7_m8_s1 local]# ifconfig ens33 | sed -rn '2s#^.*inet(.*) netmask.*$#1#gp'
192.168.1.107
解释:ens33网卡名称。,用正则匹配出来的第二行内容中的ip地址,来替换第二行内容。-n取消默认的sed软件的输出,常与sed命令的p连用。*p:打印模式空间内容,通常p会与选项-n一起使用*
更简单的命令
[root@c7_m8_s1 local]# hostname -i
192.168.1.107
#特殊符号&代表被替换的内容
[root@c7_m8_s1 local]# sed -r 's#(.*),(.*),(.*)#& ----- 1 2 3#' person.txt
101,chensiqi,CEO ----- 101 chensiqi CEO
102,dandan,CTO ----- 102 dandan CTO
103,Alex,COO ----- 103 Alex COO
104,yy,CFO ----- 104 yy CFO
105,feixue,CIO ----- 105 feixue CIO
命令说明: 1,这里将分组替换和&符号放在一起对比 2,命令中的分组替换使用了3个小括号,每个小括号分别代表每一行以逗号作为分隔符的每一列。 3,上面命令的&符号代表每一行,即模型中‘s#目标内容#替换内容#g’的目标内容。
#查找到后缀名包含_finished的图片之后进行改名,把包含的内容去掉。涉及到find 、sed、mv bash
[root@c7_m8_s1 test]# ls
stu_102999_1_finished.jpg
[root@c7_m8_s1 test]# find ./ -name "*_finished.jpg" | sed -r 's#^(.*)_finished(.*)#mv & 12#g' |bash
[root@c7_m8_s1 test]# ls
stu_102999_1.jpg
find ./ -name "*_finished.jpg" | sed -r 's#^(.*)_finished(.*)#mv & 12#g' |bash
#按行查询,加选项n。字母p 和n 连用。
[root@c7_m8_s1 local]# sed '2p' person.txt
101,chensiqi,CEO
102,dandan,CTO
102,dandan,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
#把第二行取出来
[root@c7_m8_s1 local]# sed -n '2p' person.txt
102,dandan,CTO
#查询第二行到第三行的内容,不指定地址范围:'p',默认打印全部内容。
[root@c7_m8_s1 local]# sed -n '2,3p' person.txt
102,dandan,CTO
103,Alex,COO
#一直查询从第二行开始,步长为2的内容。之道结束。
[root@c7_m8_s1 local]# sed -n '2~2p' person.txt
102,dandan,CTO
104,yy,CFO
#按字符串查询
[root@c7_m8_s1 local]# sed -n '/CTO/p' person.txt
102,dandan,CTO
#查询从CTO 到CFO的所有内容
[root@c7_m8_s1 local]# sed -n '/CTO/,/CFO/p' person.txt
102,dandan,CTO
103,Alex,COO
104,yy,CFO
#查询从第二行到包含CFO的行
[root@c7_m8_s1 local]# sed -n '2,/CFO/p' person.txt
102,dandan,CTO
103,Alex,COO
104,yy,CFO
#过滤查询多个字符串匹配
[root@c7_m8_s1 local]# sed -rn '/chensiqi|yy/p' person.txt
101,chensiqi,CEO
104,yy,CFO
#sed修改文件的同时进行备份
[root@c7_m8_s1 local]# sed -i.bak 's#dandan#NB#g' person.txt
[root@c7_m8_s1 local]# cat person.txt
101,chensiqi,CEO
102,NB,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
#查看文件获取行号
[root@c7_m8_s1 local]# sed '=' person.txt
1
101,chensiqi,CEO
2
102,NB,CTO
3
103,Alex,COO
4
104,yy,CFO
5
命令说明:使用特殊符号“=”就可以获取文件的行号,这是特殊用法,记住即可。从上面的命令结果我们也发现了一个不好的地方:行号和行不在一行。
#查询不连续的行
[root@c7_m8_s1 local]# sed -n '1p;3p;5p' person.txt
101,chensiqi,CEO
103,Alex,COO
105,feixue,CIO
awk命令选项
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
POSIX options: GNU long options: (standard)
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
Short options: GNU long options: (extensions)
-b --characters-as-bytes
-c --traditional
-C --copyright
-d[file] --dump-variables[=file]
-e 'program-text' --source='program-text'
-E file --exec=file
-g --gen-pot
-h --help
-L [fatal] --lint[=fatal]
-n --non-decimal-data
-N --use-lc-numeric
-O --optimize
-p[file] --profile[=file]
-P --posix
-r --re-interval
-S --sandbox
-t --lint-old
-V --version
locate选项
-A, --all only print entries that match all patterns
-b, --basename match only the base name of path names
-c, --count only print number of found entries
-d, --database DBPATH use DBPATH instead of default database (which is
/var/lib/mlocate/mlocate.db)
-e, --existing only print entries for currently existing files
-L, --follow follow trailing symbolic links when checking file
existence (default)
-h, --help print this help
-i, --ignore-case ignore case distinctions when matching patterns
-l, --limit, -n LIMIT limit output (or counting) to LIMIT entries
-m, --mmap ignored, for backward compatibility
-P, --nofollow, -H don't follow trailing symbolic links when checking file
existence
-0, --null separate entries with NUL on output
-S, --statistics don't search for entries, print statistics about each
used database
-q, --quiet report no error messages about reading databases
-r, --regexp REGEXP search for basic regexp REGEXP instead of patterns
--regex patterns are extended regexps
-s, --stdio ignored, for backward compatibility
-V, --version print version information
-w, --wholename match whole path name (default)
grep选项
-a 不要忽略二进制数据。
-A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c 计算符合范本样式的列数。
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
find 选项命令
-amin<分钟>:查找在指定时间曾被存取过的文件或目录,单位以分钟计算;
-anewer<参考文件或目录>:查找其存取时间较指定文件或目录的存取时间更接近现在的文件或目录;
-atime<24小时数>:查找在指定时间曾被存取过的文件或目录,单位以24小时计算;
-cmin<分钟>:查找在指定时间之时被更改过的文件或目录;
-cnewer<参考文件或目录>查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录;
-ctime<24小时数>:查找在指定时间之时被更改的文件或目录,单位以24小时计算;
-daystart:从本日开始计算时间;
-depth:从指定目录下最深层的子目录开始查找;
-expty:寻找文件大小为0 Byte的文件,或目录下没有任何子目录或文件的空目录;
-exec<执行指令>:假设find指令的回传值为True,就执行该指令;
-false:将find指令的回传值皆设为False;
-fls<列表文件>:此参数的效果和指定“-ls”参数类似,但会把结果保存为指定的列表文件;
-follow:排除符号连接;
-fprint<列表文件>:此参数的效果和指定“-print”参数类似,但会把结果保存成指定的列表文件;
-fprint0<列表文件>:此参数的效果和指定“-print0”参数类似,但会把结果保存成指定的列表文件;
-fprintf<列表文件><输出格式>:此参数的效果和指定“-printf”参数类似,但会把结果保存成指定的列表文件;
-fstype<文件系统类型>:只寻找该文件系统类型下的文件或目录;
-gid<群组识别码>:查找符合指定之群组识别码的文件或目录;
-group<群组名称>:查找符合指定之群组名称的文件或目录;
-help或——help:在线帮助;
-ilname<范本样式>:此参数的效果和指定“-lname”参数类似,但忽略字符大小写的差别;
-iname<范本样式>:此参数的效果和指定“-name”参数类似,但忽略字符大小写的差别;
-inum<inode编号>:查找符合指定的inode编号的文件或目录;
-ipath<范本样式>:此参数的效果和指定“-path”参数类似,但忽略字符大小写的差别;
-iregex<范本样式>:此参数的效果和指定“-regexe”参数类似,但忽略字符大小写的差别;
-links<连接数目>:查找符合指定的硬连接数目的文件或目录;
-iname<范本样式>:指定字符串作为寻找符号连接的范本样式;
-ls:假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出;
-maxdepth<目录层级>:设置最大目录层级;
-mindepth<目录层级>:设置最小目录层级;
-mmin<分钟>:查找在指定时间曾被更改过的文件或目录,单位以分钟计算;
-mount:此参数的效果和指定“-xdev”相同;
-mtime<24小时数>:查找在指定时间曾被更改过的文件或目录,单位以24小时计算;
-name<范本样式>:指定字符串作为寻找文件或目录的范本样式;
-newer<参考文件或目录>:查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录;
-nogroup:找出不属于本地主机群组识别码的文件或目录;
-noleaf:不去考虑目录至少需拥有两个硬连接存在;
-nouser:找出不属于本地主机用户识别码的文件或目录;
-ok<执行指令>:此参数的效果和指定“-exec”类似,但在执行指令之前会先询问用户,若回答“y”或“Y”,则放弃执行命令;
-path<范本样式>:指定字符串作为寻找目录的范本样式;
-perm<权限数值>:查找符合指定的权限数值的文件或目录;
-print:假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式为每列一个名称,每个名称前皆有“./”字符串;
-print0:假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式为全部的名称皆在同一行;
-printf<输出格式>:假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式可以自行指定;
-prune:不寻找字符串作为寻找文件或目录的范本样式;
-regex<范本样式>:指定字符串作为寻找文件或目录的范本样式;
-size<文件大小>:查找符合指定的文件大小的文件;
-true:将find指令的回传值皆设为True;
-typ<文件类型>:只寻找符合指定的文件类型的文件;
-uid<用户识别码>:查找符合指定的用户识别码的文件或目录;
-used<日数>:查找文件或目录被更改之后在指定时间曾被存取过的文件或目录,单位以日计算;
-user<拥有者名称>:查找符和指定的拥有者名称的文件或目录;
-version或——version:显示版本信息;
-xdev:将范围局限在先行的文件系统中;
-xtype<文件类型>:此参数的效果和指定“-type”参数类似,差别在于它针对符号连接检查。
总结:如果可以在awk中完成工作,不要在C中编写代码,如果sed可以处理此工作,则绝不要在awk中执行操作,如果tr可以 完成此工作,则绝不要使用sed。
如果cat 能胜任此工作,绝对不要用tr。尽可能避免使用cat。
六、监视系统资源
|
1、uptime
|
显示计算机的持续运行时间
|
|
2、ps aux
|
查看正在运行的所有进程
|
|
3、ps axjf
|
查看进程树
|
|
4、ps U mysql
|
查看mysql用户所拥有的进程
|
|
5、 kill 743
|
743 为某进程的pid。意思杀掉某个进程
|
|
6、killall vim
|
centos最小安装的话,需要单独安装:yum install psmisc
|
|
7、top
|
查看运行中进程更新的动态列表
|
|
8、lsof
|
列出打开的文件 |
|
9、lsof -u root
|
列出某个用户打开的文件列表
|
|
10、lsof filename
|
查看特定文件的使用信息,有哪些用户使用等
|
|
11、lsof -c ssd
|
列出与ssh服务相关联的文件。
|
|
12、free -m
|
显示系统 内存使用信息。
|
|
13、df -h
|
显示文件系统的磁盘使用情况
|
|
14、du -h
|
报告目录使用的文件空间
|
|
15、du -s
|
只报告目录使用的总空间,
|
PS选项命令
a:显示所有终端机下执行的程序,除了阶段作业领导者之外。
a:显示现行终端机下的所有程序,包括其他用户的程序。
-A:显示所有程序。
-c:显示CLS和PRI栏位。
c:列出程序时,显示每个程序真正的指令名称,而不包含路径,选项或常驻服务的标示。
-C<指令名称>:指定执行指令的名称,并列出该指令的程序的状况。
-d:显示所有程序,但不包括阶段作业领导者的程序。
-e:此选项的效果和指定"A"选项相同。
e:列出程序时,显示每个程序所使用的环境变量。
-f:显示UID,PPIP,C与STIME栏位。
f:用ASCII字符显示树状结构,表达程序间的相互关系。
-g<群组名称>:此选项的效果和指定"-G"选项相同,当亦能使用阶段作业领导者的名称来指定。
g:显示现行终端机下的所有程序,包括群组领导者的程序。
-G<群组识别码>:列出属于该群组的程序的状况,也可使用群组名称来指定。
h:不显示标题列。
-H:显示树状结构,表示程序间的相互关系。
-j或j:采用工作控制的格式显示程序状况。
-l或l:采用详细的格式来显示程序状况。
L:列出栏位的相关信息。
-m或m:显示所有的执行绪。
n:以数字来表示USER和WCHAN栏位。
-N:显示所有的程序,除了执行ps指令终端机下的程序之外。
-p<程序识别码>:指定程序识别码,并列出该程序的状况。
p<程序识别码>:此选项的效果和指定"-p"选项相同,只在列表格式方面稍有差异。
r:只列出现行终端机正在执行中的程序。
-s<阶段作业>:指定阶段作业的程序识别码,并列出隶属该阶段作业的程序的状况。
s:采用程序信号的格式显示程序状况。
S:列出程序时,包括已中断的子程序资料。
-t<终端机编号>:指定终端机编号,并列出属于该终端机的程序的状况。
t<终端机编号>:此选项的效果和指定"-t"选项相同,只在列表格式方面稍有差异。
-T:显示现行终端机下的所有程序。
-u<用户识别码>:此选项的效果和指定"-U"选项相同。
u:以用户为主的格式来显示程序状况。
-U<用户识别码>:列出属于该用户的程序的状况,也可使用用户名称来指定。
U<用户名称>:列出属于该用户的程序的状况。
v:采用虚拟内存的格式显示程序状况。
-V或V:显示版本信息。
-w或w:采用宽阔的格式来显示程序状况。
x:显示所有程序,不以终端机来区分。
X:采用旧式的Linux i386登陆格式显示程序状况。
-y:配合选项"-l"使用时,不显示F(flag)栏位,并以RSS栏位取代ADDR栏位 。
-<程序识别码>:此选项的效果和指定"p"选项相同。
--cols<每列字符数>:设置每列的最大字符数。
--columns<每列字符数>:此选项的效果和指定"--cols"选项相同。
--cumulative:此选项的效果和指定"S"选项相同。
--deselect:此选项的效果和指定"-N"选项相同。
--forest:此选项的效果和指定"f"选项相同。
--headers:重复显示标题列。
--help:在线帮助。
--info:显示排错信息。
--lines<显示列数>:设置显示画面的列数。
--no-headers:此选项的效果和指定"h"选项相同,只在列表格式方面稍有差异。
--group<群组名称>:此选项的效果和指定"-G"选项相同。
--Group<群组识别码>:此选项的效果和指定"-G"选项相同。
--pid<程序识别码>:此选项的效果和指定"-p"选项相同。
--rows<显示列数>:此选项的效果和指定"--lines"选项相同。
--sid<阶段作业>:此选项的效果和指定"-s"选项相同。
--tty<终端机编号>:此选项的效果和指定"-t"选项相同。
--user<用户名称>:此选项的效果和指定"-U"选项相同。
--User<用户识别码>:此选项的效果和指定"-U"选项相同。
--version:此选项的效果和指定"-V"选项相同。
--widty<每列字符数>:此选项的效果和指定"-cols"选项相同。
七、rsync 远程文件同步
-v, --verbose 详细模式输出。
-q, --quiet 精简输出模式。
-c, --checksum 打开校验开关,强制对文件传输进行校验。
-a, --archive 归档模式,表示以递归方式传输文件,并保持所有文件属性,等于-rlptgoD。
-r, --recursive 对子目录以递归模式处理。
-R, --relative 使用相对路径信息。
-b, --backup 创建备份,也就是对于目的已经存在有同样的文件名时,将老的文件重新命名为~filename。可以使用--suffix选项来指定不同的备份文件前缀。
--backup-dir 将备份文件(如~filename)存放在在目录下。
-suffix=SUFFIX 定义备份文件前缀。
-u, --update 仅仅进行更新,也就是跳过所有已经存在于DST,并且文件时间晚于要备份的文件,不覆盖更新的文件。
-l, --links 保留软链结。
-L, --copy-links 想对待常规文件一样处理软链结。
--copy-unsafe-links 仅仅拷贝指向SRC路径目录树以外的链结。
--safe-links 忽略指向SRC路径目录树以外的链结。
-H, --hard-links 保留硬链结。
-p, --perms 保持文件权限。
-o, --owner 保持文件属主信息。
-g, --group 保持文件属组信息。
-D, --devices 保持设备文件信息。
-t, --times 保持文件时间信息。
-S, --sparse 对稀疏文件进行特殊处理以节省DST的空间。
-n, --dry-run现实哪些文件将被传输。
-w, --whole-file 拷贝文件,不进行增量检测。
-x, --one-file-system 不要跨越文件系统边界。
-B, --block-size=SIZE 检验算法使用的块尺寸,默认是700字节。
-e, --rsh=command 指定使用rsh、ssh方式进行数据同步。
--rsync-path=PATH 指定远程服务器上的rsync命令所在路径信息。
-C, --cvs-exclude 使用和CVS一样的方法自动忽略文件,用来排除那些不希望传输的文件。
--existing 仅仅更新那些已经存在于DST的文件,而不备份那些新创建的文件。
--delete 删除那些DST中SRC没有的文件。
--delete-excluded 同样删除接收端那些被该选项指定排除的文件。
--delete-after 传输结束以后再删除。
--ignore-errors 及时出现IO错误也进行删除。
--max-delete=NUM 最多删除NUM个文件。
--partial 保留那些因故没有完全传输的文件,以是加快随后的再次传输。
--force 强制删除目录,即使不为空。
--numeric-ids 不将数字的用户和组id匹配为用户名和组名。
--timeout=time ip超时时间,单位为秒。
-I, --ignore-times 不跳过那些有同样的时间和长度的文件。
--size-only 当决定是否要备份文件时,仅仅察看文件大小而不考虑文件时间。
--modify-window=NUM 决定文件是否时间相同时使用的时间戳窗口,默认为0。
-T --temp-dir=DIR 在DIR中创建临时文件。
--compare-dest=DIR 同样比较DIR中的文件来决定是否需要备份。
-P 等同于 --partial。
--progress 显示备份过程。
-z, --compress 对备份的文件在传输时进行压缩处理。
--exclude=PATTERN 指定排除不需要传输的文件模式。
--include=PATTERN 指定不排除而需要传输的文件模式。
--exclude-from=FILE 排除FILE中指定模式的文件。
--include-from=FILE 不排除FILE指定模式匹配的文件。
--version 打印版本信息。
--address 绑定到特定的地址。
--config=FILE 指定其他的配置文件,不使用默认的rsyncd.conf文件。
--port=PORT 指定其他的rsync服务端口。
--blocking-io 对远程shell使用阻塞IO。
-stats 给出某些文件的传输状态。
--progress 在传输时现实传输过程。
--log-format=formAT 指定日志文件格式。
--password-file=FILE 从FILE中得到密码。
--bwlimit=KBPS 限制I/O带宽,KBytes per second。
-h, --help 显示帮助信息。
rsync六种工作模式
除此上述几个参数之外,我们还注意到上图中rsync的七个命令格式:如下:
1)rsync [OPTION]... SRC [SRC]... DEST
2)rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST
3)rsync [OPTION]... SRC [SRC]... [USER@]HOST::DEST
4)rsync [OPTION]... SRC [SRC]... rsync://[USER@]HOST[:PORT]/DEST
5)rsync [OPTION]... [USER@]HOST:SRC [DEST]
6)rsync [OPTION]... [USER@]HOST::SRC [DEST]
7)rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
这七个命令格式就是代表rsync六种不同的工作模式,其中第四种和第七种模式没有多大的区别。在这几种模式中第三种和第六种模式是我们经常使用的,特别是第三种模式。
这六种模式总体上可以用两个词进行区分:推送、拉取。
推送就是在客户端上执行rsync命令,目的是把客户端需要同步的文件推送到服务器上。
拉取也是在客户端上执行rsync命令,目的是把服务器上的文件拉取到本地。
注意:无论是推送和拉取,rsync命令都是在客户端执行,只是命令的格式不同而已。
1) rsync [OPTION]... SRC [SRC]... DEST
同步本地文件,从一个目录同步到另外一个目录。如:rsync -avz /data /backup,表示把本地/data目录下的文件同步到本地/backup目录下。
2) rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST
使用一个远程shell程序(如rsh、ssh)来实现把本地的文件同步到远程机器上。此种方式属于推送方式。如:rsync -avz /data test@192.168.199.247:/backup,表示把本地/data目录下的文件同步到服务器192.168.199.247的/backup目录下。
3) rsync [OPTION]... SRC [SRC]... [USER@]HOST::DEST
把本地的文件同步到远程服务器上,其中DEST表示的是rsync服务器的认证模块名。此种方式属于推送方式。如:rsync -avz /data test@192.168.199.247::backup --password-file=/etc/rsyncd.password,表示把本地/data目录下的文件同步到服务器192.168.199.247的backup模块下path路径下。
4) rsync [OPTION]... SRC [SRC]... rsync://[USER@]HOST[:PORT]/DEST
列出远程机器的文件列表。这类似于ls命令,不过只要在命令中省略掉本地机信息即可。如:rsync -v rsync://test@192.168.199.247/backup,表示在本机列出服务器192.168.199.247的/backup目录下的内容,如下:
5) rsync [OPTION]... [USER@]HOST:SRC [DEST]
把远程机器的文件同步到本地,此种方式属于拉取方式。如:rsync -avz test@192.168.199.247:/backup /data,表示把192.168.199.247的/backup目录下文件同步到本地/data目录下。
6) rsync [OPTION]... [USER@]HOST::SRC [DEST]
把远程机器的文件同步到本地,此种方式属于拉取方式。如:rsync -avz test@192.168.199.247::backup --password-file=/etc/rsyncd.password /data,表示把192.168.199.247的backup模块path路径下的文件同步到本地/data目录下。
不含空格字符总数:31953
------------------写不动了----------------------
参考:
linux 命令速查手册(第二版本)

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~





