一、TiDB 简介
TiDB 具备如下 NewSQL 核心特性:
- SQL支持 (TiDB 是 MySQL 兼容的)
- 水平线性弹性扩展
- 分布式事务
- 跨数据中心数据强一致性保证
- 故障自恢复的高可用
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景。
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
二、开源
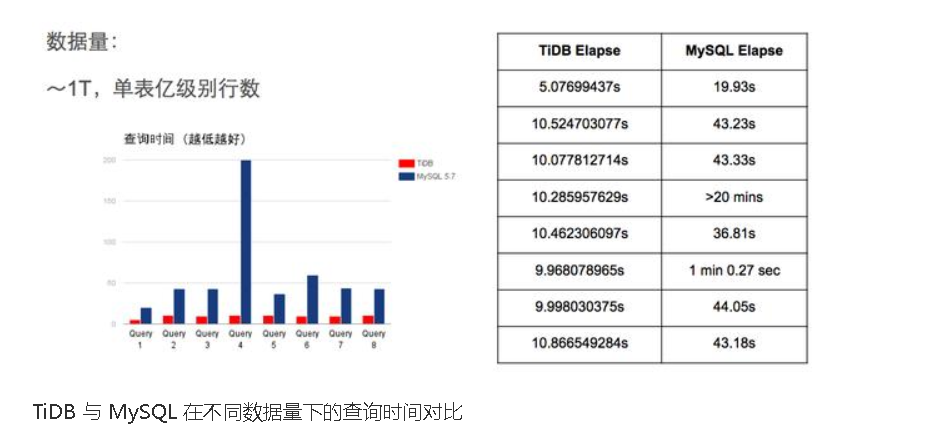
三、与 MySQL 兼容性对比
不支持的特性
-
- 但是不做任何事情(pass through)。
- 不支持对enum类型的列进行修改
- 存储过程
- 视图
- 触发器
- 自定义函数
- 外键约束
- 全文索引
- 空间索引
- 非 UTF8 字符集
TiDB 支持常用的 MySQL 内建函数,但是不是所有的函数都已经支持,具体请参考语法文档。
DDL
TiDB 实现了 F1 的异步 Schema 变更算法,DDL 执行过程中不会阻塞线上的 DML 操作。目前已经支持的 DDL 包括:
-
-
- Create Database
- Drop Database
- Create Table
- Drop Table
- Add Index
- Drop Index
- Add Column
- Drop Column
- Alter Column
- Change Column
- Modify Column
- Truncate Table
- Rename Table
- Create Table Like
-
以上语句还有一些支持不完善的地方,具体包括如下:
-
- Add/Drop primary key 操作目前不支持。
- Add Index/Column 操作不支持同时创建多个索引或列。
- Drop Column 操作不支持删除的列为主键列或索引列。
- Add Column 操作不支持同时将新添加的列设为主键或唯一索引,也不支持将此列设成 auto_increment 属性。
- Change/Modify Column 操作目前支持部分语法,细节如下:
- 在修改类型方面,只支持整数类型之间修改,字符串类型之间修改和 Blob 类型之间的修改,且只能使原类型长度变长。此外,不能改变列的 unsigned/charset/collate 属性。这里的类型分类如下:
- 具体支持的整型类型有:TinyInt,SmallInt,MediumInt,Int,BigInt。
- 具体支持的字符串类型有:Char,Varchar,Text,TinyText,MediumText,LongText。
- 具体支持的 Blob 类型有:Blob,TinyBlob,MediumBlob,LongBlob。
- 在修改类型定义方面,支持的包括 default value,comment,null,not null 和 OnUpdate,但是不支持从 null 到 not null 的修改。
- 支持 LOCK [=] {DEFAULT|NONE|SHARED|EXCLUSIVE} 语法,
- 在修改类型方面,只支持整数类型之间修改,字符串类型之间修改和 Blob 类型之间的修改,且只能使原类型长度变长。此外,不能改变列的 unsigned/charset/collate 属性。这里的类型分类如下:
四、事务
TiDB 使用乐观事务模型,在执行 Update、Insert、Delete 等语句时,只有在提交过程中才会检查写写冲突,而不是像 MySQL 一样使用行锁来避免写写冲突。所以业务端在执行 SQL 语句后,需要注意检查 commit 的返回值,即使执行时没有出错,commit的时候也可能会出错。
Load data
- 语法:
LOAD DATA LOCAL INFILE 'file_name' INTO TABLE table_name
{FIELDS | COLUMNS} TERMINATED BY 'string' ENCLOSED BY 'char' ESCAPED BY 'char'
LINES STARTING BY 'string' TERMINATED BY 'string'
(col_name ...);其中 ESCAPED BY 目前只支持 ‘//‘。
- 事务的处理:
TiDB 在执行 load data 时,默认每 2 万行记录作为一个事务进行持久化存储。如果一次 load data 操作插入的数据超过 2 万行,那么会分为多个事务进行提交。如果某个事务出错,这个事务会提交失败,但它前面的事务仍然会提交成功,在这种情况下一次 load data 操作会有部分数据插入成功,部分数据插入失败。而 MySQL 中会将一次 load data 操作视为一个事务,如果其中发生失败情况,将会导致整个 load data 操作失败。
五、高级功能
功能说明
TiDB 实现了通过标准 SQL 接口读取历史数据功能,无需特殊的 client 或者 driver。当数据被更新、删除后,依然可以通过 SQL 接口将更新/删除前的数据读取出来。
另外即使在更新数据之后,表结构发生了变化,TiDB 依旧能用旧的表结构将数据读取出来。
六、案例
1、摩拜
摩拜每天产生的骑行数据超过30TB,在全球拥有最为全面的骑行大数据,飞速增长的业务下也面临着数据库扩展与运维的巨大挑战。中间件方案对业务过强的侵入性、不支持跨分片的分布式事务、无法保证强一致性事务的特性都使我们望而却步。2017年初,摩拜单车开始使用TiDB,从最早的RC3、RC4、PreGA、到现在的1.0正式版,一步步见证了TiDB的成熟和稳定。
2、易果生鲜
在评估初期,Greenplum、Kudu、TiDB 都进入了我们的视野,对于新的实时系统,我们有主要考虑点:
- 首先,系统既要满足 OLAP 还要满足 OLTP 的基本需求;
- 其次,新系统要尽量降低业务的使用要求;
- 最后,新系统最好能够与现有的 Hadoop 体系相结合。
最后,TiSpark 是建立在 Spark 引擎之上,Spark 在机器学习领域里有诸如 Mllib 等诸多成熟的项目,对比 GP 和 Kudu,算法工程师们使用 TiSpark 去操作 TiDB 的门槛非常低,同时也会大大提升算法工程师们的效率。
经过综合的考虑,我们最终决定使用 TiDB 作为新的实时系统。同时,目前 TiDB 的社区活跃度非常好,这也是我们考虑的一个很重要的方面。
3、360金融
在评估阶段,我们考虑了几种方案,各有利弊。首先被淘汰的是使用 MySQL 的解决方案。使用关系型数据库的优势是在查询方面的便捷性。在开发效率上,SQL 是开发人员和数据分析人员的必备技能,能够较快的在功能上实现需求。但是在数据存储和计算层面,MySQL 的表现则差强人意。在面对大数据量时,MySQL 能采取的水平扩展策略无非是分库分表,这样的后果就是查询逻辑变的非常复杂,不易维护,且性能下降的较为严重
。
另一个方案是把 HBase 作为数据存储的解决方案。它的优点很明显,可以水平扩展,数据量不再是瓶颈。但是它的缺点也同样明显,即对开发人员不友好,查询的 API 功能性较差。
在对 TiDB 有了实际的认识和应用经验后,我们计划使用 TiDB 来取代 HBase,存储用户风险模型的相关数据。同时尝试在 TiDB 中慢慢迁入 Neo4j 的数据,最终回到关系模型的架构下,只是我们手中不再是日渐老去的 MySQL,而是新一代的分布式数据库 TiDB。
4、猿辅导
猿辅导的业务决定了其后台系统具有以下特点:
- 数据体量大,增速快,存储系统需要能够灵活的水平扩展;
- 有复杂查询,BI 方面的需求,可以根据索引,例如城市、渠道等,进行实时统计;
- 数据存储要具备高可用、高可运维性,实现自动故障转移。
最终,猿辅导的后台开发同学决定寻求一个彻底的分布式存储解决方案。通过对社区方案的调研,猿辅导发现分布式关系型数据库 TiDB 项目。
猿辅导研发副总裁郭常圳看来:“TiDB 是一个很有野心的项目,从无到有的解决了 MySQL 过去遇到的扩展性问题,在很多场合下也有 OLAP 的能力,省去了很多数据仓库搭建成本和学习成本。这在业务层是非常受欢迎的。”对于接下来的计划,猿辅导预计在其他分库分表业务中,通过 syncer 同步,进行合并,然后进行统计分析。
5、去哪网
传统的关系型数据库不能很好的满足业务需求,主要是在两个维度:一是随着数据量爆炸式增长,性能急剧下降,而且很难在单机内存储;二是一些场景下业务对响应速度要求较高,数据库无法及时返回结果,而传统的 memcached 缓存又存在无法持久化数据,存储容量受限于内存等问题。针对这两个问题,去哪儿的DBA团队分别调研了 TiDB 和 InnoDB memcached 以满足业务需求,为用户提供更多的选择方案。
目前业界最流行的分布式数据库有两类,一个是以 Google Spanner 为代表,一个是以 AWS Auraro 为代表。
目前业界最流行的分布式数据库有两类,一个是以 Google Spanner 为代表,一个是以 AWS Auraro 为代表。
Spanner 是 shared nothing 的架构,内部维护了自动分片、分布式事务、弹性扩展能力,数据存储还是需要 sharding,plan 计算也需要涉及多台机器,也就涉及了分布式计算和分布式事务。主要产品代表为 TiDB、CockroachDB、OceanBase 等。
Auraro 主要思想是计算和存储分离架构,使用共享存储技术,这样就提高了容灾和总容量的扩展。但是在协议层,只要是不涉及到存储的部分,本质还是单机实例的 MySQL,不涉及分布式存储和分布式计算,这样就和 MySQL 兼容性非常高。主要产品代表为 PolarDB。
去哪儿数据存储方案现状
在去哪儿的 DBA 团队,主要有三种数据存储方案,分别是 MySQL、Redis 和 HBase。
MySQL 是去哪儿的最主要的数据存储方案,绝大部分核心的数据都存储在 MySQL 中。MySQL 的优点不用多说,缺点是没法做到水平扩展。MySQL 要想能做到水平扩展,唯一的方法就业务层的分库分表或者使用中间件等方案
此处省略原文作者对Hbase的吐槽!
综上所述,为了解决现有数据存储方案所遇到的问题,去哪儿 DBA 团队从 2017 年上半年开始调研分布式数据库,在分布式数据库的产品选择上,综合各个方面因素考虑,最终选择了 TiDB,具体原因不在这里细说了,下面开始具体聊聊 TiDB。
硬件选型和部署:
因 TiDB 和 PD 对磁盘 IO 要求不高,所以只需要普通磁盘即可。
TiKV 对磁盘 IO 要求较高。TiKV 硬盘大小建议不超过 500G,以防止硬盘损害时,数据恢复耗时过长。综合内存和硬盘考虑,我们采用了 4 块 600G 的 SAS 盘,每个 TiKV 机器起 4 个 Tikv 实例,给节点配置 labels 并且通过在 PD 上配置 location-labels 来指明哪些 label 是位置标识,保证同一个机器上的 4 个 TiKV 具有相同的位置标识,同一台机器是多个实例也只会保留一个 Replica。有条件的最好使用 SSD,这样可以提供更好的性能。强烈推荐万兆网卡。
部署工具使用了 TiDB-Ansible,TiDB-Ansible 是 PingCap 基于 Ansible playbook 功能编写了一个集群部署工具叫 TiDB-Ansible。使用该工具可以快速部署一个完整的 TiDB 集群(包括 PD、TiDB、TiKV 和集群监控模块),一键完成以下各项运维工作:
• 初始化操作系统,包括创建部署用户、设置 hostname 等
• 部署组件
• 滚动升级,滚动升级时支持模块存活检测
• 数据清理
• 环境清理
• 配置监控模块
6、盖娅广告
盖娅广告匹配系统(GaeaAD)用于支撑盖娅互娱全平台实时广告投放系统,需要将广告数据和游戏 SDK 上报的信息进行近实时匹配。
初期的MysQL存储 :MySQL RDS 存储方案
当时的匹配逻辑主要通过 SQL 语句来实现,包含了很多联表查询和聚合操作。当数据量在千万级别左右,系统运行良好,基本响应还在一分钟内。
娅广告系统系统接收数据很快突破千万/日。
第二个方案就是采用 NoSQL,因为此系统需要接收业务端并发的实时写入和实时查询,所以使用类似 Greenplum,Hive 或者 SparkSQL 这样的系统不太合适,因为这几个系统并不是针对实时写入设计的, MongoDB 的问题是文档型的查询访问接口对业务的修改太大,而且 MongoDB 是否能满足在这么大数据量下高效的聚合分析可能是一个问题。
所以很明显,我们当时的诉求就是能有一款数据库既能像 MySQL 一样便于使用,最好能让业务几乎不用做任何修改,又能满足分布式的存储需求,还要保证很高的复杂查询性能。
当时调研了一下社区的分布式数据库解决方案,找到了 TiDB 这个项目,因为协议层兼容 MySQL,而且对于复杂查询的支持不错,业务代码完全不用修改直接就能使用,使迁移使用成本降到极低。
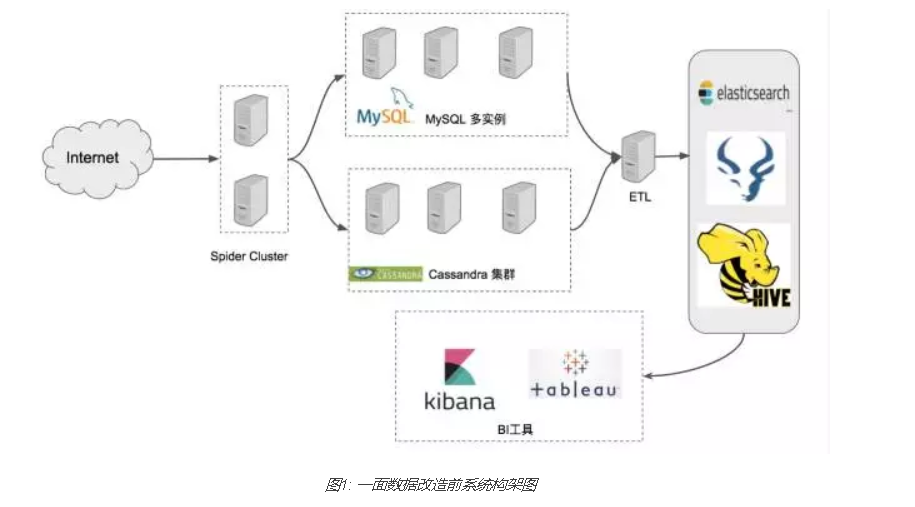
7、一面数据
期初架构
改造后架构
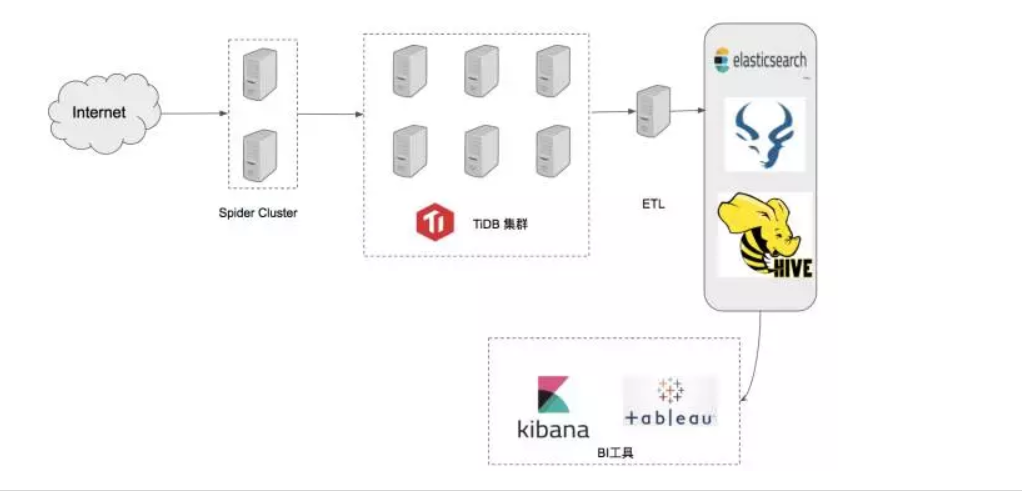
完成迁移以后,系统不再需要维护多个 MySQL 实例以及 Cassandra 集群,运维成本大幅缩减,监控使用 Prometheus/Grafana,并且可以通过 Prometheus 的 AlertManager 定制规则复杂的报警规则。这些改变都让一面数据的爬虫存储侧的工作便利许多,可以让一面数据的研发把精力更多放在业务研发而不是运维多个不同技术栈的复杂集群。
未来的架构规划
目前 TiDB 新增了 TiSpark 组件,并且在 TiKV 层实现了 Spark 的下推算子,使得可以直接在 TiDB 集群上跑 Spark 程序,这样可以省去 ETL 的步骤。后续一面数据也考虑深入使用 TiSpark 组件,让一面数据的整个系统增加一定的实时复杂查询的能力。长远来看,可以把现在 ElasticSearch,Impala,Hive 的业务都迁移到 Spark 集群上,这样一方面统一了分析侧的技术栈,另一方面连接了 Spark 丰富庞大的生态。
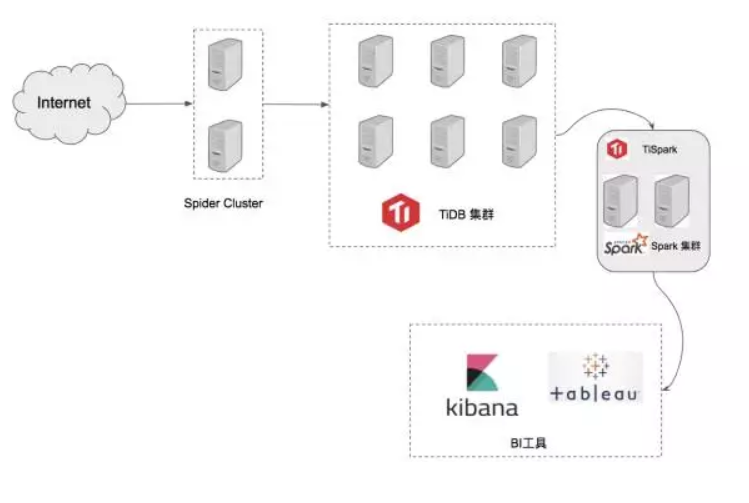
8、万达网络
万达网络科技集团的技术团队,建设和维护着一套实时风控平台。这套实时风控平台,承担着各种关键交易的在线风控数据的写入和查询服务。实时风控平台后端的数据库系统在高性能,可靠性,可扩展性上有很高的要求,并且需要满足如下核心功能和业务要求:
- 风控相关业务数据实时入库
- 实时风控规则计算
- 通过 BI 工具分析风控历史数据
- ETL 入库到 Hadoop 数据仓库
- 应用开发侧需要兼容 MySQL,降低应用改造门槛
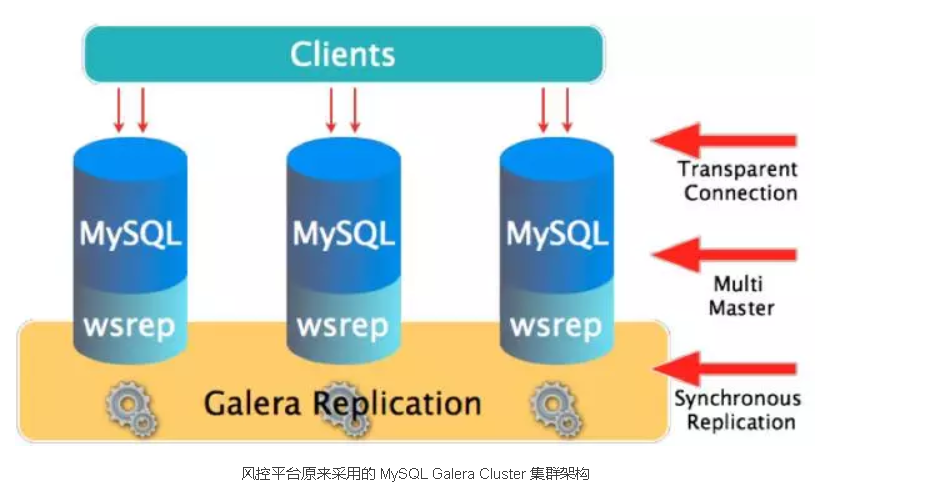
- 基于 MySQL 主从复制方式的高可用方案,容易出现诸如接入层脑裂和数据不一致的风险。
- 基于 MySQL Proxy 中间件的方案,缺少对分库分表后的跨库跨表的分布式事务支持以及对复杂JOIN 的良好支持,因此也无法满足业务上风控规则实时计算和复杂查询的需求以及对业务团队的 BI 需求的支持。
- 基于 MySQL Proxy 中间件的方案需要业务代码的开发妥协,需要显式设计和指定分库分表的切分规则和路由配置,开发改造和运维成本显著增高。
- 在实时风控平台的高并发高性能的对外服务过程中,在线灵活扩容的相关工作在 MySQL Proxy 中间件架构中无法高效和可靠的实施。
最终万达的技术团队,通过评估验证,选择了 TiDB 帮助他们实现一个高性能,高可靠性和高扩展能力的实时风控平台后台数据库系统。
TiDB 产品和技术方案对业务需求的支持和助力效果,集中表现在:
- 借助 TiDB 的分布式计算和存储引擎,集群对外服务的处理能力大大增强,高并发实时的风控规则计算能够轻松的处理完,相比较原来的 MySQL Galera Cluster 方案,单位处理性能提升了数倍。并且数据库集群获得了线性提升和扩展的能力。
- 集群整体 QPS(万级起)和 Latency (毫秒级) 对风控的实时性要求做出了技术保证。
- 无需考虑分库分表,对业务应用透明无侵入,应用开发和维护变得直观且简单。业务相关数据量规模和请求即便高速增长,也无需担心应用的复杂调整和运维的风险。
- TiDB 针对分布式事务和强一致性的完善设计以及对各种 JOIN 模式的支持,使得实时风控类和 BI 分析类的业务应用能够高效运行。
参考来源(微信公众号): CSDN技术头条 作者:丁宬杰,胡明
InfoQ 作者:罗瑞星
AI前线 作者:作者|金中浩
PingCAP 陈新江
Qunar技术沙龙 作者:蒲聪
高效开发运维 作者:刘玄

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

