随着Scrapy等框架的流行,用Python等语言写爬虫已然成为一种时尚。但是今天,我们并不谈如何写爬虫,而是说说不要写代码就能写出来的爬虫。
爬虫新时代
在早期互联网世界,写爬虫是一项技术含量非常高的活,往大的方向说,爬虫技术是搜索引擎的重要组成部分。
随着互联网技术的发展,写爬虫不再是门槛非常高的技术了,一些编程语言甚至直接提供爬虫框架,例如python的Scrapy框架,它们让写爬虫走入“寻常百姓家”。
在知乎的热门话题“能利用爬虫技术做到哪些很酷很有趣很有用的事情?”下,很多用户用爬虫实现了很多有趣的事情:
有人用爬虫爬取了12万知乎用户的头像,并根据点击数据训练出来了一个机器人,可以自动识别美女;
有人用爬虫爬取了上海各大房产网站的数据,分析并总结出过去几年上海房价的深度报告;
有人用爬虫爬取了一千多万用户的400亿条tweet,对twitter进行数据挖掘。
写爬虫几乎没有门槛
我们已经发现,写爬虫是一件炫酷的事情。但即使是这样,学习爬虫仍然有一定的技术门槛,比如说要使用Scrapy框架,你至少得会python编程语言。
想象一个场景:你是一个房地产销售人员,你需要联系很多潜在客户,这时候如果靠在搜索引擎或者在相关网页上查看信息,就会非常地费时费力。于是就有朋友说了,学习一下怎么写爬虫,然后抓取销售数据就可以了,一次学习终生受用。
这样的说法,很难说的上是个好主意,对于房地产销售从业者来说,学习写爬虫的代价实在是过于高昂了,一来没有编程基础,二来如果真的能写好爬虫,恐怕就直接转行写带代码了。
在这样的形势下,一些可视化的爬虫工具诞生了!这些工具通过一些策略来爬取特定的数据,虽然没有自己写爬虫操作精准,但是学习成本低很多,下面就来介绍几款可视化的爬虫工具。
集搜客GooSeeker
使用集搜客不需要编程语言的基础,将要抓取的特定字段映射到工作台,建立好采集的规则,就能轻松将数据采集成功,整个过程简单明了。
集搜客的特色是爬虫群功能,功能非常强大,可以直接在会员中心控制采集数量,控制采集时间,同时可以用多个爬虫采集同一网址,防止采集过于频繁IP被封,又能保证采集的速度,同时采集的数据可以直接入库,并导出,关键是集搜客还不限制采集的深度和广度,想多少采集多少。
八爪鱼
八爪鱼有个优点,可以下载现成的采集规则,如果不会写规则,就直接用别人写的规则就好了,进一步降低了使用爬虫的门槛。
网络矿工
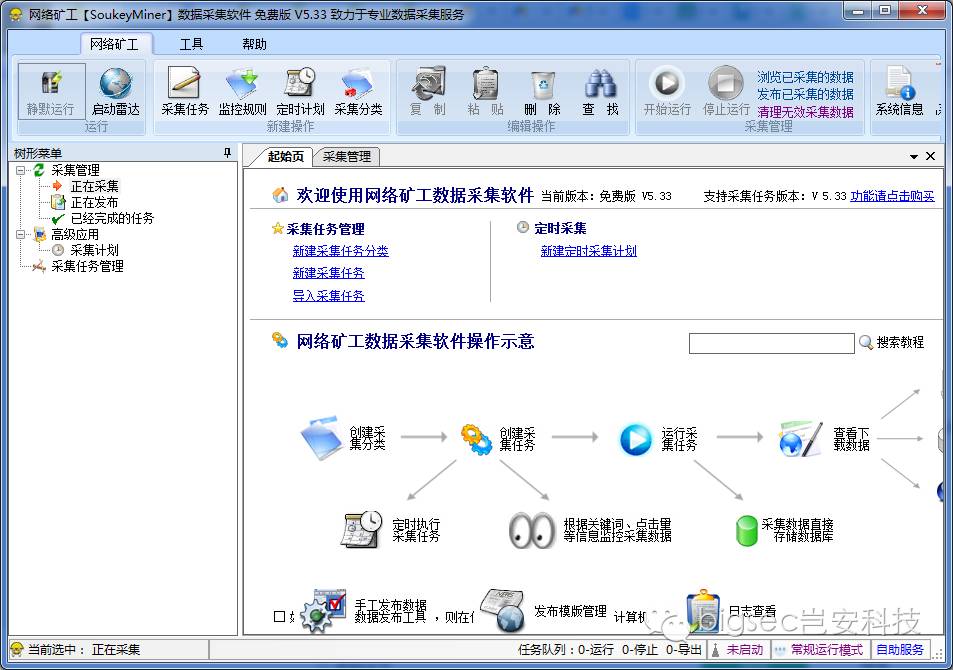
网络矿工是一款基于C#开源的网络爬虫工具,注意,是开源。网络矿工遵循BSD开源协议,具备完整的UI交互、线程管理、采集匹配等,用户可以基于此扩展属于自己的采集器,而不受任何限制。
火车头

火车头采集器界面比较清爽,并且内置了好几款皮肤,视觉效果不错。采集器内置了一些常用网站的采集规则,内容以门户网站为主,感觉用处不是太大。
采集规则流程倒是蛮清晰的,自动获取地址链接也足够方便,缺点是一些结构复杂的页面无法获取到信息。
神箭手平台
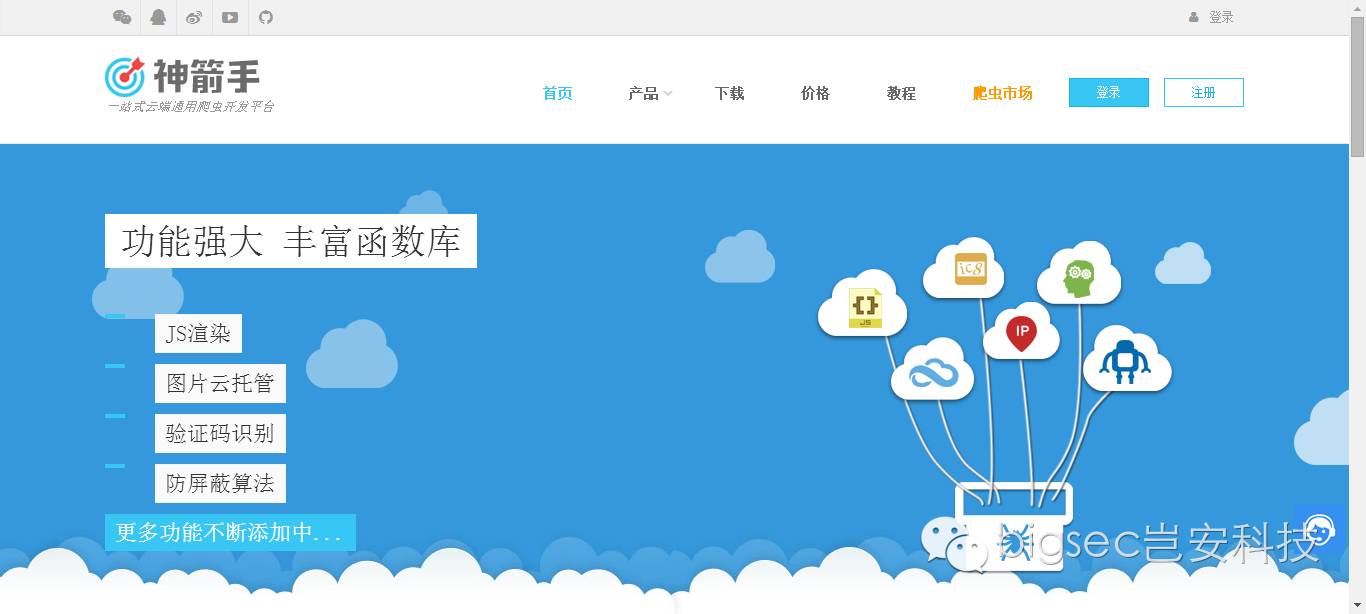
神箭手平台和以上工具都不太一样,它是一个开发爬虫的平台,你可以自己开发爬虫并将爬虫托管到云端。
神箭手的一些特性非常符合潮流,比如防屏蔽、开放的接口、图标分析功能,换句话说这其实已经是个开发工具了。
更重要的是,它是一个爬虫市场,你可以出售自己的爬虫,或者在平台上购买需要的爬虫,这对于广大爬虫爱好者来说,多了一个交流和变现的途径。
爬虫与反爬虫
可视化爬虫工具的出现,让大量原本并不会写爬虫的人也能爬取数据,这就至少能造成两个后果,一是网站的数据丢失的概率更大,如果是商业数据的话,被竞争对手利用从而导致经济损失;二是越来越多的爬虫会对网站负载造成压力,严重者甚至会宕机。
当然,对于普通用户来说,无论是学习写爬虫还是学习使用可视化爬虫工具,都对自己的工作与生活有益。
互联网的发展重新定义了很多规则,而爬虫的存在使得一些看起来非常困难的事情也变得容易起来,也让一些原本简单的事情变得复杂。
* 本文作者:岂安科技(企业帐号),转载请注明来自FreeBuf黑客与极客(FreeBuf.COM)

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~






