前言
用scrapy的CrawlSpider爬取某某招聘网站的数据,并提取关键指标。
此家招聘网站做了反扒机制,比较难搞,并且以访问,和爬取频率来封IP~来减轻爬虫的爬取~
创建表模型,
备注:(因此招聘网站数据类型较多,为了快速进行迭代开发,我们都用varchar进行处理!)

CrawlSpider详解:
pip install -i https://pypi.douban.com/simple/ fake_useragent
爬取结果,逻辑很简单,通过定义itemloader,提取规则即可!

被此招聘检测出是爬虫,就给我停掉了,也会限制我的IP,so制定爬取策略!
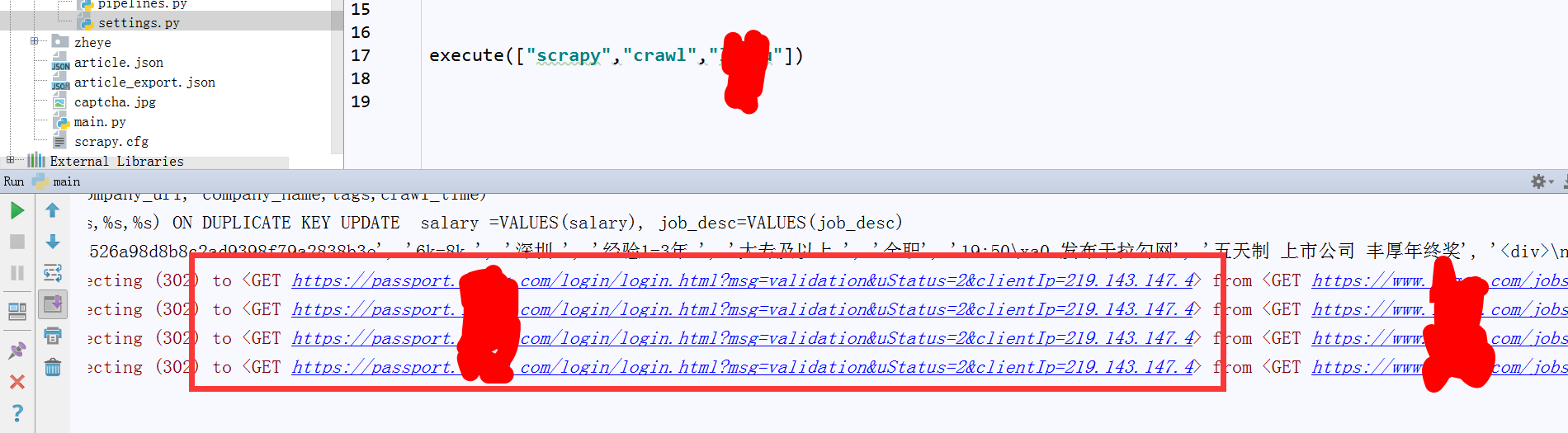
这里爬取策略,就是尽量降低爬取速度,实现用高逆的代理IP池和动态的userAgent。作为程序猿,刚开始还是尽量不买中间件好,中间件智能实现动态代理,稳定高效,但是得花钱啊!
小编很穷,只能找找教程,来实现自定义动态代理的IP池的代码编写!
# 自定义useragent
class RandomUserAgentMiddleware(object):
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.per_proxy = crawler.settings.get('RANDOM_UA_PER_PROXY', False)
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE', 'random')
self.proxy2ua = {}
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
def get_ua():
'''Gets random UA based on the type setting (random, firefox…)'''
return getattr(self.ua, self.ua_type)
if self.per_proxy:
proxy = request.meta.get('proxy')
if proxy not in self.proxy2ua:
self.proxy2ua[proxy] = get_ua()
logging.debug('Assign User-Agent %s to Proxy %s'
% (self.proxy2ua[proxy], proxy))
request.headers.setdefault('User-Agent', self.proxy2ua[proxy])
else:
ua = get_ua()
request.headers.setdefault('User-Agent', get_ua())
ip池实现,通过爬虫爬取免费ip池的代理商,进行提取动态IP
鼓秋了一晚上,可能我的是小宽带商,链接到代理IP,都失败了!我擦就酱紫吧~
保护好自己的IP很重要~,本机的是爬取的最快的~

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~






