前言
爬取知乎的问题,回答,点赞数,评论数,创建日期,格式化进行入库操作
爬取知乎表结构设计
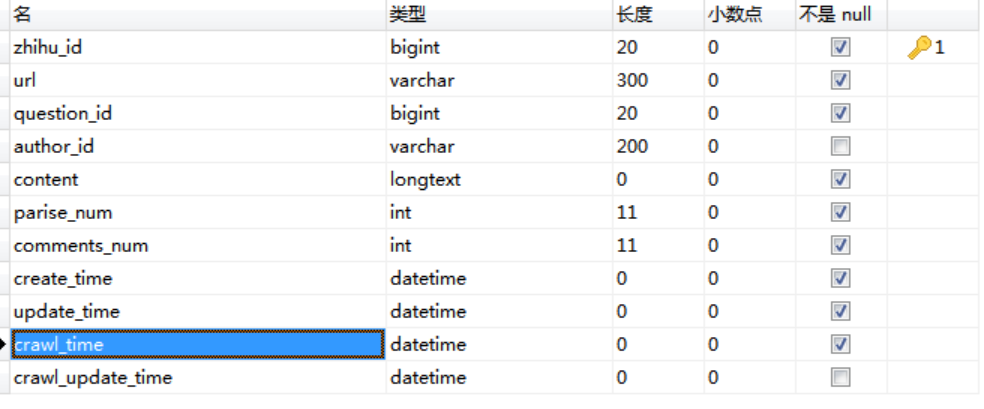
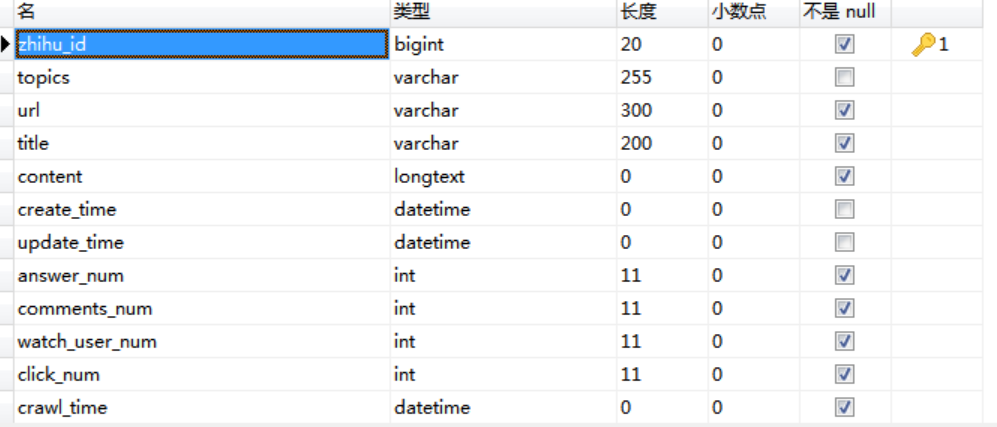
每个问题id对应多个回答ID. SO,设计两张表。一对多的关系~
问题表(zhihu_question ),回答表(zhihu_answer )
zhihu_question.zhihu_id == zhihu_answer.question_id
zhihu_answer
zhihu_question
业务逻辑代码
# -*- coding: utf-8 -*-
import scrapy
import re
import json
import datetime
try:
import urlparse as parse
except:
from urllib import parse
from scrapy.loader import ItemLoader
from BoleOnline.items import ZhihuQuestionItem, ZhihuAnswerItem
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
headers = {
"HOST": "www.zhihu.com",
"Referer": "https://www.zhizhu.com",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.87 Safari/537.36"
}
# question的第一页answer的请求url
start_answer_url = "https://www.zhihu.com/api/v4/questions/{0}/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit={1}&offset={2}"
def parse(self, response):
"""
提取出html页面中的所有url 并跟踪这些url进行一步爬取
如果提取的url中格式为 /question/xxx 就下载之后直接进入解析函数
"""
all_urls = response.css("a::attr(href)").extract()
all_urls = [parse.urljoin(response.url, url) for url in all_urls]
# 只存放https开头的链接,进行初步的过滤
all_urls = filter(lambda x: True if x.startswith("https") else False, all_urls)
for url in all_urls:
match_obj = re.match("(.*zhihu.com/question/(d+))(/|$).*", url)
if match_obj:
# 如果提取到question相关的页面则下载后交由提取函数进行提取
request_url = match_obj.group(1)
yield scrapy.Request(request_url, headers=self.headers, callback=self.parse_question)
else:
# 如果不是question页面则直接进一步跟踪
yield scrapy.Request(url, headers=self.headers, callback=self.parse)
def parse_question(self, response):
if "QuestionHeader-title" in response.text:
# 处理新版本
match_obj = re.match("(.*zhihu.com/question/(d+))(/|$).*", response.url)
if match_obj:
question_id = int(match_obj.group(2))
item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response)
item_loader.add_css("title", "h1.QuestionHeader-title::text")
item_loader.add_css("content", ".QuestionHeader-detail")
item_loader.add_value("url", response.url)
item_loader.add_value("zhihu_id", question_id)
item_loader.add_css("answer_num", ".List-headerText span::text")
item_loader.add_css("comments_num", ".QuestionHeader-Comment button::text")
item_loader.add_css("watch_user_num", ".NumberBoard-value::text")
item_loader.add_css("topics", ".QuestionHeader-topics .Popover div::text")
question_item = item_loader.load_item()
else:
# 处理老版本页面的item提取
match_obj = re.match("(.*zhihu.com/question/(d+))(/|$).*", response.url)
if match_obj:
question_id = int(match_obj.group(2))
item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response)
# item_loader.add_css("title", ".zh-question-title h2 a::text")
item_loader.add_xpath("title",
"//*[@id='zh-question-title']/h2/a/text()|//*[@id='zh-question-title']/h2/span/text()")
item_loader.add_css("content", "#zh-question-detail")
item_loader.add_value("url", response.url)
item_loader.add_value("zhihu_id", question_id)
item_loader.add_css("answer_num", "#zh-question-answer-num::text")
item_loader.add_css("comments_num", "#zh-question-meta-wrap a[name='addcomment']::text")
# item_loader.add_css("watch_user_num", "#zh-question-side-header-wrap::text")
item_loader.add_xpath("watch_user_num",
"//*[@id='zh-question-side-header-wrap']/text()|//*[@class='zh-question-followers-sidebar']/div/a/strong/text()")
item_loader.add_css("topics", ".zm-tag-editor-labels a::text")
question_item = item_loader.load_item()
yield scrapy.Request(self.start_answer_url.format(question_id, 20, 0), headers=self.headers,
callback=self.parse_answer)
yield question_item
def parse_answer(self, reponse):
# 处理question的answer
ans_json = json.loads(reponse.text)
is_end = ans_json["paging"]["is_end"]
next_url = ans_json["paging"]["next"]
# 提取answer的具体字段
for answer in ans_json["data"]:
answer_item = ZhihuAnswerItem()
answer_item["zhihu_id"] = answer["id"]
answer_item["url"] = answer["url"]
answer_item["question_id"] = answer["question"]["id"]
answer_item["author_id"] = answer["author"]["id"] if "id" in answer["author"] else None
answer_item["content"] = answer["content"] if "content" in answer else None
answer_item["parise_num"] = answer["voteup_count"]
answer_item["comments_num"] = answer["comment_count"]
answer_item["create_time"] = answer["created_time"]
answer_item["update_time"] = answer["updated_time"]
answer_item["crawl_time"] = datetime.datetime.now()
yield answer_item
if not is_end:
yield scrapy.Request(next_url, headers=self.headers, callback=self.parse_answer)
def start_requests(self):
return [scrapy.Request('https://www.zhihu.com/#signin', headers=self.headers, callback=self.login)]
def login(self, response):
response_text = response.text
match_obj = re.match('.*name="_xsrf" value="(.*?)"', response_text, re.DOTALL)
xsrf = ''
if match_obj:
xsrf = (match_obj.group(1))
if xsrf:
post_url = "https://www.zhihu.com/login/phone_num"
post_data = {
"_xsrf": xsrf,
"phone_num": "15811006613",
"password": "zhangtongle",
"captcha": ""
}
import time
t = str(int(time.time() * 1000))
# captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login".format(t)
captcha_url_cn = "https://www.zhihu.com/captcha.gif?r={0}&type=login&lang=cn".format(t)
# yield scrapy.Request(captcha_url, headers=self.headers,meta={"post_data":post_data},callback=self.login_after_captcha)
yield scrapy.Request(captcha_url_cn, headers=self.headers,meta={"post_data":post_data},callback=self.login_after_captcha_cn)
def login_after_captcha_cn(self, response):
#验证知乎倒立汉字验证码
with open("captcha.jpg", "wb") as f:
f.write(response.body)
f.close()
from zheye import zheye
z = zheye()
positions = z.Recognize('captcha.jpg')
pos_arr = []
if len(positions) == 2:
if positions[0][1] > positions[1][1]:
pos_arr.append([positions[1][1], positions[1][0]])
pos_arr.append([positions[0][1], positions[0][0]])
else:
pos_arr.append([positions[0][1], positions[0][0]])
pos_arr.append([positions[1][1], positions[1][0]])
else:
pos_arr.append([positions[0][1], positions[0][0]])
post_url = "https://www.zhihu.com/login/phone_num"
post_data = response.meta.get("post_data", {})
if len(positions) == 2:
post_data["captcha"] = '{"img_size": [200, 44], "input_points": [[%.2f, %f], [%.2f, %f]]}' % (
pos_arr[0][0] / 2, pos_arr[0][1] / 2, pos_arr[1][0] / 2, pos_arr[1][1] / 2)
else:
post_data["captcha"] = '{"img_size": [200, 44], "input_points": [%.2f, %f]}' % (
pos_arr[0][0] / 2, pos_arr[0][1] / 2)
post_data["captcha_type"] = "cn"
return [scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login
)]
def login_after_captcha(self,response):
with open("captcha.jpg", "wb") as f:
f.write(response.body)
f.close()
from PIL import Image
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
pass
captcha = input("输入验证码n>")
post_url = "https://www.zhihu.com/login/phone_num"
post_data = response.meta.get("post_data", {})
post_data["captcha"] = captcha
return [scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login
)]
def check_login(self, response):
#验证服务器的返回数据判断是否成功
text_json = json.loads(response.text)
if "msg" in text_json and text_json["msg"] == "登录成功":
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True, headers=self.headers)
传输类代码(IO)
class MySQLTwisted_Zhihu_Pipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host=settings["MYSQL_HOST"],
db=settings["MYSQL_DBNAME"],
user=settings["MYSQL_USER"],
passwd=settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
# 使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) # 处理异常
def handle_error(self, failure, item, spider):
# 处理异步插入的异常
print(failure)
def do_insert(self, cursor, item):
# 执行具体的插入
# 根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql, params = item.get_insert_sql()
print(insert_sql, params)
cursor.execute(insert_sql, params)
后台控制类代码
import scrapy
import datetime
import re
from scrapy.loader.processors import MapCompose,TakeFirst, Join
from scrapy.loader import ItemLoader
from BoleOnline.utils.common import extract_num
from BoleOnline.settings import SQL_DATETIME_FORMAT,SQL_DATE_FORMAT
class ZhihuQuestionItem(scrapy.Item):
#知乎的问题 item
zhihu_id = scrapy.Field()
topics = scrapy.Field()
url = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
answer_num = scrapy.Field()
comments_num = scrapy.Field()
watch_user_num = scrapy.Field()
click_num = scrapy.Field()
crawl_time = scrapy.Field()
def get_insert_sql(self):
# 插入知乎question表的sql语句
insert_sql = """
insert into zhihu_question(zhihu_id, topics, url, title, content, answer_num, comments_num,
watch_user_num, click_num, crawl_time
)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE content=VALUES(content), answer_num=VALUES(answer_num), comments_num=VALUES(comments_num),
watch_user_num=VALUES(watch_user_num), click_num=VALUES(click_num)
"""
zhihu_id = self["zhihu_id"][0]
topics = ",".join(self["topics"])
url = self["url"][0]
title = "".join(self["title"])
content = "".join(self["content"])
answer_num = extract_num("".join(self["answer_num"]))
comments_num = extract_num("".join(self["comments_num"]))
if len(self["watch_user_num"]) == 2:
watch_user_num = int(self["watch_user_num"][0])
click_num = int(self["watch_user_num"][1])
else:
watch_user_num = int(self["watch_user_num"][0])
click_num = 0
crawl_time = datetime.datetime.now().strftime(SQL_DATETIME_FORMAT)
params = (zhihu_id, topics, url, title, content, answer_num, comments_num,
watch_user_num, click_num, crawl_time)
return insert_sql, params
class ZhihuAnswerItem(scrapy.Item):
#知乎的问题回答item
zhihu_id = scrapy.Field()
url = scrapy.Field()
question_id = scrapy.Field()
author_id = scrapy.Field()
content = scrapy.Field()
parise_num = scrapy.Field()
comments_num = scrapy.Field()
create_time = scrapy.Field()
update_time = scrapy.Field()
crawl_time = scrapy.Field()
def get_insert_sql(self):
# 插入知乎question表的sql语句
insert_sql = """
insert into zhihu_answer(zhihu_id, url, question_id, author_id, content, parise_num, comments_num,
create_time, update_time, crawl_time
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE content=VALUES(content), comments_num=VALUES(comments_num), parise_num=VALUES(parise_num),
update_time=VALUES(update_time)
"""
create_time = datetime.datetime.fromtimestamp(self["create_time"]).strftime(SQL_DATETIME_FORMAT)
update_time = datetime.datetime.fromtimestamp(self["update_time"]).strftime(SQL_DATETIME_FORMAT)
params = (
self["zhihu_id"], self["url"], self["question_id"],
self["author_id"], self["content"], self["parise_num"],
self["comments_num"], create_time, update_time,
self["crawl_time"].strftime(SQL_DATETIME_FORMAT),
)
return insert_sql, params
设置类代码
ITEM_PIPELINES = {
# 'BoleOnline.pipelines.JsonExporterPipeline': 2,
# # 'scrapy.pipelines.images.ImagesPipeline':1,
#
# 'BoleOnline.pipelines.ArticleImagePipeline': 1,
# 'BoleOnline.pipelines.MySQLTwistedPipeline' :1,
'BoleOnline.pipelines.MySQLTwisted_Zhihu_Pipeline': 1,
}
MYSQL_HOST = "192.168.1.3"
MYSQL_DBNAME = "mydb3"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"
SQL_DATETIME_FORMAT = "%Y-%m-%d %H:%M:%S"
SQL_DATE_FORMAT = "%Y-%m-%d"
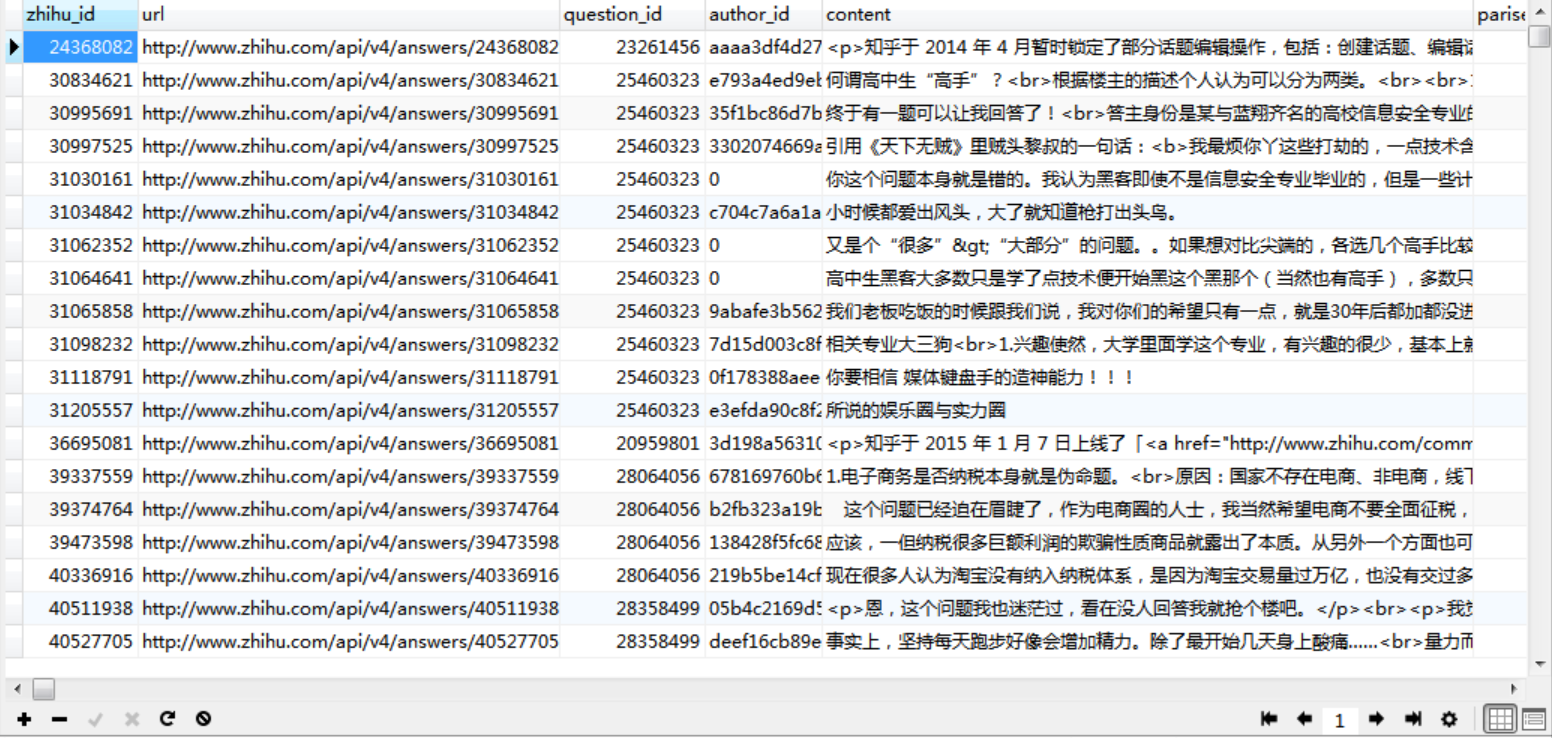
运行结果


 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~






