一、登陆知乎
1、首先建立知乎的爬虫,就直接在之前项目下建立。
scrapy genspider zhihu www.zhihu.com
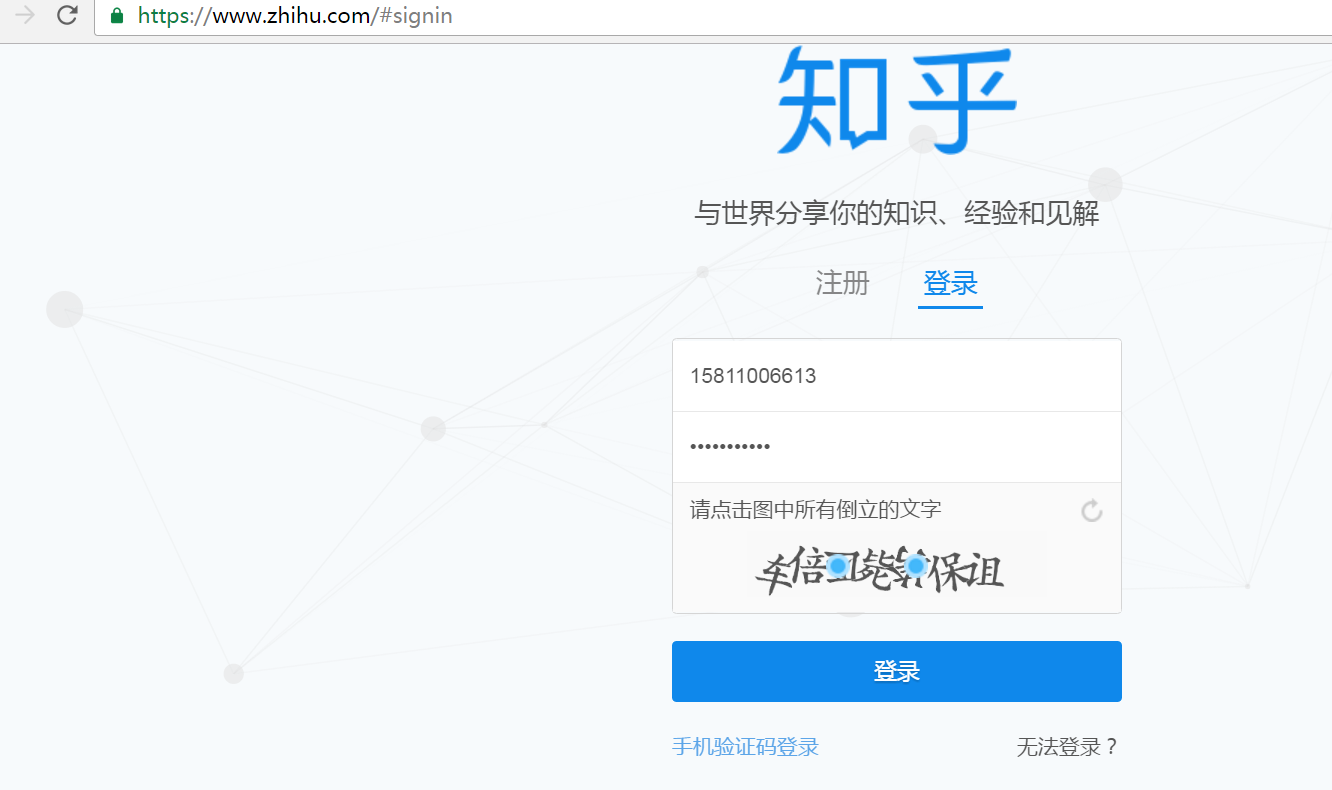
2、直接卡在知乎倒立的验证码识别上
知乎是越来越难爬取了,因为可恶的验证码,还整个倒立的,万幸的是有大神用AI破解了,哈哈!
安装过程,我只想用四个拼接字符来来形容 “F ”+,"U"+"C" ,+"K"!!!
https://github.com/muchrooms/zheye 因为网站只有几个G的空间,有兴趣的童鞋,还是自己下去吧~
然后把zheye的库copy到自己的项目当中去!
这个库包安装指南:
pip install -i https://pypi.douban.com/simple/ Keras==2.0.1 (出错)
有个依赖出错了,需要单独安装:
pip install scipy-0.19.1-cp35-cp35m-win_amd64.whl
然后重新执行:pip install -i https://pypi.douban.com/simple/ Keras==2.0.1 (成功)
pip install -i https://pypi.douban.com/simple/ tensorflow==1.0.1 (成功)
pip install -i https://pypi.douban.com/simple/ h5py==2.6.0(出错)
单独安装
pip install h5py-2.7.1-cp35-cp35m-win_amd64.whl
单独安装的俄库文件在这里下载:
http://www.lfd.uci.edu/~gohlke/pythonlibs/
Keras==2.0.1
Pillow==3.4.2 (跳过,因为系统有最新版本)
#jupyter==1.0.0
#matplotlib==1.5.3
numpy==1.12.1
scikit-learn==0.18.1
tensorflow==1.0.1
h5py==2.6.0
突破知乎中文倒立验证码:
# -*- coding: utf-8 -*-
import scrapy
import re
import json
import datetime
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
headers = {
"HOST": "www.zhihu.com",
"Referer": "https://www.zhizhu.com",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.87 Safari/537.36"
}
def parse(self, response):
pass
def start_requests(self):
return [scrapy.Request('https://www.zhihu.com/#signin', headers=self.headers, callback=self.login)]
def login(self, response):
response_text = response.text
match_obj = re.match('.*name="_xsrf" value="(.*?)"', response_text, re.DOTALL)
xsrf = ''
if match_obj:
xsrf = (match_obj.group(1))
if xsrf:
post_url = "https://www.zhihu.com/login/phone_num"
post_data = {
"_xsrf": xsrf,
"phone_num": "15811006613",
"password": "xxxxxxx",
"captcha": ""
}
import time
t = str(int(time.time() * 1000))
captcha_url_cn = "https://www.zhihu.com/captcha.gif?r={0}&type=login&lang=cn".format(t)
yield scrapy.Request(captcha_url_cn, headers=self.headers,meta={"post_data":post_data},callback=self.login_after_captcha_cn)
def login_after_captcha_cn(self, response):
#验证知乎倒立汉字验证码
with open("captcha.jpg", "wb") as f:
f.write(response.body)
f.close()
from zheye import zheye
z = zheye()
positions = z.Recognize('captcha.jpg')
pos_arr = []
if len(positions) == 2:
if positions[0][1] > positions[1][1]:
pos_arr.append([positions[1][1], positions[1][0]])
pos_arr.append([positions[0][1], positions[0][0]])
else:
pos_arr.append([positions[0][1], positions[0][0]])
pos_arr.append([positions[1][1], positions[1][0]])
else:
pos_arr.append([positions[0][1], positions[0][0]])
post_url = "https://www.zhihu.com/login/phone_num"
post_data = response.meta.get("post_data", {})
if len(positions) == 2:
post_data["captcha"] = '{"img_size": [200, 44], "input_points": [[%.2f, %f], [%.2f, %f]]}' % (
pos_arr[0][0] / 2, pos_arr[0][1] / 2, pos_arr[1][0] / 2, pos_arr[1][1] / 2)
else:
post_data["captcha"] = '{"img_size": [200, 44], "input_points": [%.2f, %f]}' % (
pos_arr[0][0] / 2, pos_arr[0][1] / 2)
post_data["captcha_type"] = "cn"
return [scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login
)]
def check_login(self, response):
#验证服务器的返回数据判断是否成功
text_json = json.loads(response.text)
if "msg" in text_json and text_json["msg"] == "登录成功":
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True, headers=self.headers)
验证:


 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~






