前言
爬取伯乐在线,所有最新文章页的标题,主题、创建时间、评论数、分享、点赞的数量,正文内容、图片等,存入到MySQL当中!
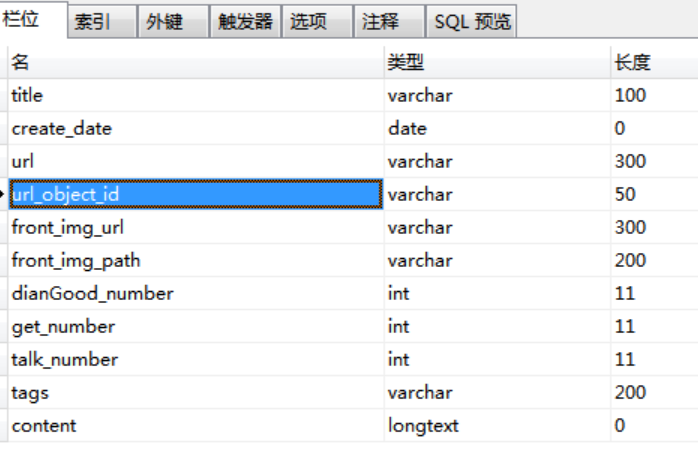
一、定义表结构
二、需要安装的类库
pip install -i https://pypi.douban.com/simple/ pillow
pip install -i https://pypi.douban.com/simple/ mysqlclient
三、main.py(运行类)
from scrapy.cmdline import execute
import sys
import os
# print(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy","crawl","jobbole"])
四、items.py(结构类,模型类)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BoleonlineItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#
pass
class JobBoleArticleItem(scrapy.Item):
# 标题
re_title = scrapy.Field()
# 文章创建日期
re_create_date = scrapy.Field()
# 文章链接
url = scrapy.Field()
# 文章鏈接md5加密
url_object_id = scrapy.Field()
# 文章封面图
front_img_url = scrapy.Field()
# 封面图路径
front_img_path = scrapy.Field()
# 文章点赞数
re_dianGood_number = scrapy.Field()
# 文章收藏数
re_get_number = scrapy.Field()
# 文章评论数
re_talk_number = scrapy.Field()
# 文章主题标签
tags = scrapy.Field()
# 文章内容
re_content = scrapy.Field()
pass
五、settings.py(设置类)
ITEM_PIPELINES = {
# 'BoleOnline.pipelines.JsonExporterPipeline': 2,
# # 'scrapy.pipelines.images.ImagesPipeline':1,
#
# 'BoleOnline.pipelines.ArticleImagePipeline': 1,
'BoleOnline.pipelines.MySQLTwistedPipeline' :1,
}
IMAGES_URLS_FIELD = "front_img_url"
project_dir = os.path.abspath(os.path.dirname(__file__))
IMAGES_STORE = os.path.join(project_dir,"images")
MYSQL_HOST = "192.168.1.3"
MYSQL_DBNAME = "mydb3"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"
六、piplines.py(管道,传输类)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
import codecs
import json
from scrapy.exporters import JsonItemExporter
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class BoleonlinePipeline(object):
def process_item(self, item, spider):
return item
#爬取的内容保存到json文件里
class JsonWithEncodingPipeline(object):
# 自定義json文件的導出
def __init__(self):
self.file = codecs.open('article.json', 'w', encoding="utf-8")
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "n"
self.file.write(lines)
return item
def spider_closed(self,spider):
self.file.close()
#爬取的内容保存到json文件里
class JsonExporterPipeline(object):
# 調用scrapy 提供好的json export導出json文件
def __init__(self):
self.file = codecs.open('article_export.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding="utf-8",ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self,spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self,item,spider):
self.exporter.export_item(item)
return item
#正常同步到MySQL当中,如解析速度过快,很容易引起MySQL插入堵塞
class MySQLPipeline(object):
def __init__(self):
self.conn = MySQLdb.connect('192.168.1.3','root','root','mydb3',charset="utf8",use_unicode="true")
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
insert into jobbole_article(title,create_date,url,dianGood_number) VALUES (%s,%s,%s,%s)
"""
self.cursor.execute(insert_sql,(item["re_title"], item["re_create_date"], item["url"], item["re_dianGood_number"]))
self.conn.commit()
#异步的不会影响MySQL插入堵塞等问题
class MySQLTwistedPipeline(object):
def __init__(self,dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls,settings):
dbparms=dict(
host=settings["MYSQL_HOST"],
db=settings["MYSQL_DBNAME"],
user=settings["MYSQL_USER"],
passwd=settings["MYSQL_PASSWORD"],
charset="utf8",
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool("MySQLdb",**dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted將mysql插入變成異步執行
query = self.dbpool.runInteraction(self.do_insert,item)
# 處理異常
query.addErrback(self.handle__error)
def handle__error(self,failure):
# 處理異步插入的異常
print(failure)
def do_insert(self,cursor,item):
insert_sql = """
insert into jobbole_article(title,create_date,url,dianGood_number) VALUES (%s,%s,%s,%s)
"""
cursor.execute(insert_sql,(item["re_title"], item["re_create_date"], item["url"], item["re_dianGood_number"]))
#保存爬取的图片到指定路径
class ArticleImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
for ok,value in results:
image_file_path = value["path"]
item["front_img_path"] = image_file_path
return item
七、spider.py(爬取类)
import scrapy
import re
import datetime
from scrapy.http import Request
from urllib import parse
from BoleOnline.items import JobBoleArticleItem
from BoleOnline.utils.common import get_md5
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
# 获取 下一页面的url并交给scrapy进行下载
post_nodes = response.css("#archive .floated-thumb .post-thumb") # a selector, 可以在这个基础上继续做 selector
for post_node in post_nodes:
post_url = post_node.css("a::attr(href)").extract_first("")
img_url = post_node.css("a img::attr(src)").extract_first("")
yield Request(url=parse.urljoin(response.url, post_url),
meta={"front-image-url": img_url}, callback=self.parse_detail)
# 必须考虑到有前一页,当前页和下一页链接的影响,使用如下所示的方法
next_url = response.css(".next.page-numbers::attr(href)").extract_first("")
if next_url:
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def parse_detail(self, response):
article_item = JobBoleArticleItem()
# 文章封面图
front_img_url = response.meta.get("front-image-url", "")
# 获取文章的标题
re_title = response.xpath("/html//div[@class='entry-header']/h1/text()").extract_first("")
# 获取文章的创建日期
re_create_date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract_first("").strip().replace(" ·","").strip()
# 获取点赞数
re_dianGood_number = response.xpath('//span[contains(@class,"vote-post-up")]/h10/text()').extract_first("")
# 利用正则表达式,过滤掉不要的字符
re_math = re.match(".*?(d+).*", re_dianGood_number)
if re_math:
re_dianGood_number = re_math.group(1)
else:
re_dianGood_number = 0
# 使用contains方法获取收藏数
re_get_number = response.xpath("//span[contains(@class,'bookmark-btn')] /text() ").extract_first("")
# 利用正则表达式,过滤掉不要的字符
re_math = re.match(".*?(d+).*",re_get_number)
if re_math:
re_get_number = re_math.group(1)
else:
re_get_number = 0
# 使用contains方法获取评论数
re_talk_number = response.xpath("//a[contains(@href,'#article-comment')]/span/text() ").extract_first("")
# 利用正则表达式,过滤掉不要的字符
re_math = re.match(".*?(d+).*", re_talk_number)
if re_math:
re_talk_number = re_math.group(1)
else:
re_talk_number = 0
# 获取正文内容
re_content = response.xpath("//div[@class='entry']") .extract_first("")
# 获取文章头标签
re_tag = response.xpath("//p[@class='entry-meta-hide-on-mobile']/a/text()").extract()
# 过滤掉评论
re_tag = [element for element in re_tag if not element.strip().endswith("评论")]
tags =",".join(re_tag)
#保存到Scrapy的Item中,可以进行格式化处理
article_item["url_object_id"] = get_md5(response.url)
article_item["re_title"] = re_title
try:
re_create_date = datetime.datetime.strptime(re_create_date, "%Y/%m/%d").date()
except Exception as e:
re_create_date = datetime.datetime.now().date()
article_item["re_create_date"] = re_create_date
article_item["url"] = response.url
article_item["front_img_url"] = [front_img_url]
article_item["re_dianGood_number"] = re_dianGood_number
article_item["re_get_number"] = re_get_number
article_item["re_talk_number"] = re_talk_number
article_item["tags"] = tags
article_item["re_content"] = re_content
yield article_item
pass

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~






