一、基础篇
1、回顾正则表达式
2、深度优先,广度优先算法的理解
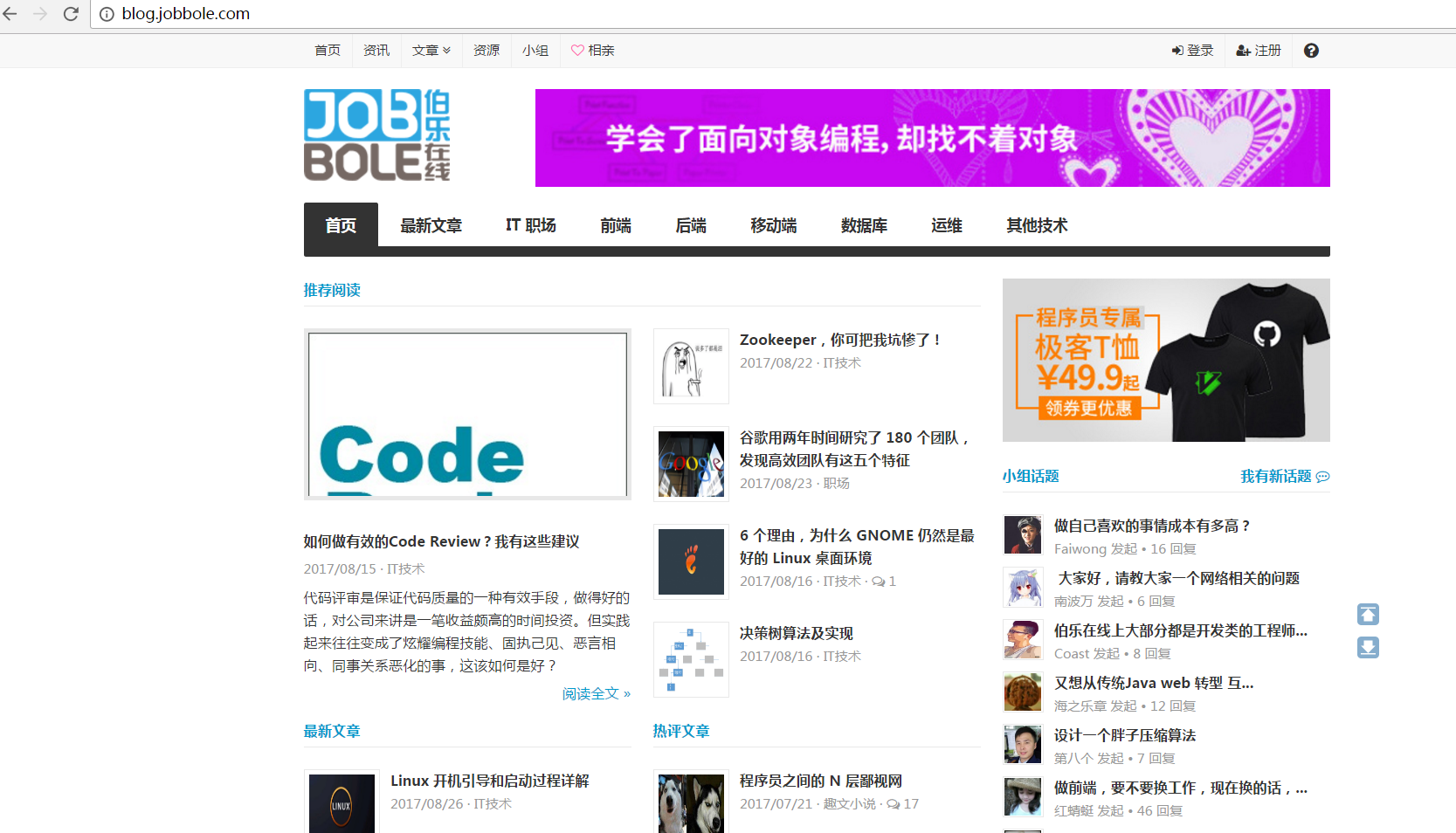
3、明确爬取网站的内容
伯乐在线 :http://www.jobbole.com/ 中的技术文章,在二级域名下:http://blog.jobbole.com/

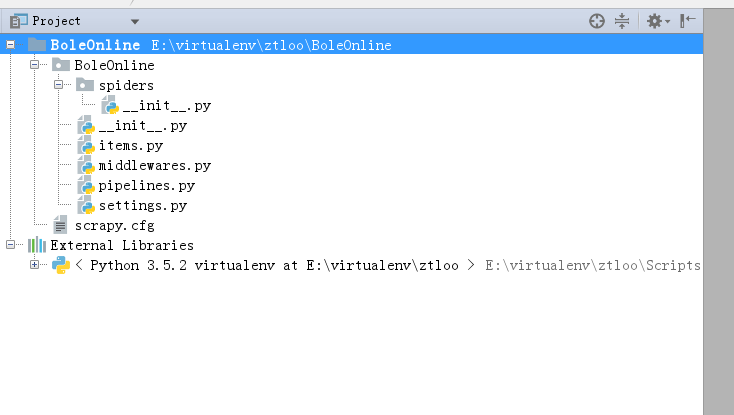
4、 建立scrapy项目
因pycharm 没提供直接新建Scrapy项目的方式,所以我们要手动新建,然后在引入到Pycharm里面
去看相对应的版本的Scrapy 官方手册,看人家怎么建立的:
scrapy startproject BoleOnline

导入到Pycharm中
scrapy genspider jobbole blog.jobbole.com

执行爬取操作:scrapy crawl jobbole
报错,因为在windows上少了个组件需要安装:pip install -i https://pypi.douban.com/simple/ pypiwin32

因使用命令行,比较麻烦,所以我们这里自己写执行命令到Pycharm里面来代替手工的cmd命令~
# -*- coding: utf-8 -*-
from scrapy.cmdline import execute
import sys
import os
# print(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy","crawl","jobbole"])
XPath详解
http://funhacks.net/2016/05/08/使用XPath解析HTML文档/
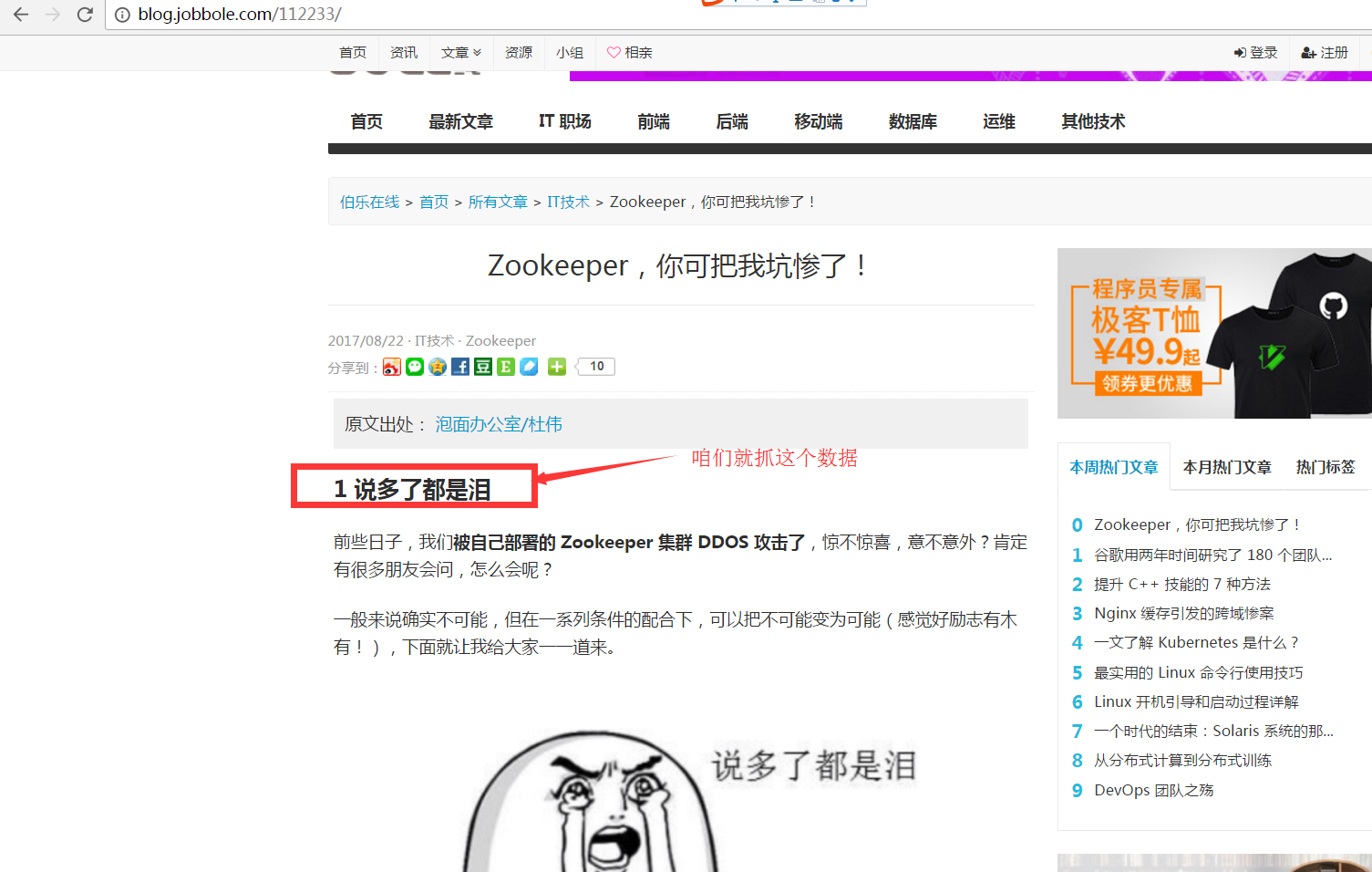
Scrapy 小案例
咱们就抓已给目标页面的H3上的标题。
#-*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/112233/']
def parse(self, response):
# 测试
re_selector = response.xpath("//*[@id='post-112233']/div[3]/h3[1]/text()").extract()[0]
# 获取文章的标题
re_title = response.xpath("//*[@id='post-112233']/div[1]/h1/text()").extract()[0]
# 获取文章的创建日期
re_create_date = response.xpath("//*[ @ id = 'post-112233']/div[2]/p/text()")
.extract()[0]
.strip()
.replace(" ·","")
.strip()
# 获取点赞数
re_dianGood_number = response.xpath(" // *[ @ id = '112233votetotal']/text() ").extract()[0]
# 使用contains方法获取收藏数
re_get_number = response.xpath("//span[contains(@class,'bookmark-btn')] /text() ").extract()[0]
# 利用正则表达式,过滤掉不要的字符
re_math = re.match(".*(d+).*",re_get_number)
if re_math:
re_get_number = re_math.group(1)
# 使用contains方法获取评论数
re_talk_number = response.xpath("//a[contains(@href,'#article-comment')]/span/text() ").extract()[0]
# 利用正则表达式,过滤掉不要的字符
re_math = re.match(".*(d+).*", re_talk_number)
if re_math:
re_talk_number = re_math.group(1)
# 获取正文内容
re_content = response.xpath("//div[@class='entry']") .extract()[0]
# 获取文章头标签
re_tag = response.xpath("//p[@class='entry-meta-hide-on-mobile']/a/text()") .extract()
# 过滤掉评论
re_tag = [element for element in re_tag if not element.strip().endswith("评论")]
tags =",".join(re_tag);
# 测试输出
print(re_selector)
# 输出文章标题
print(re_title)
# 输出文章创建日期
print(re_create_date)
# 输出点赞数
print(re_dianGood_number)
# 输出收藏数
print(re_get_number)
# 输出评论数
print(re_talk_number)
# 输出文章主题标签
print(tags)
# 输出正文内容
print(re_content)
pass
运行结果


 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~






