前言
跑了几天Tensorflow ,苦不堪言,网上的demo,不是tame,软件版本不匹配跑不起来,再不就是程序写的可能2B,跑起来相当慢了,也查了Tensorflow慢的原因,官方表示正在解决。想了一下,为了兼具现在大部分企业的传统java web项目,先玩玩java的AI的框架:DeepLearning4J。这样的话环境和读代码理解起来相对比较容易些!
这是官网自己介绍Dl4j这款AI框架,有多么嚎,自吹自擂,反正小编不怎么喜欢这种风格,但是对于java程序猿和java企业级项目,确实是一款快速实施的一款AI工具!
具体介绍:
我们先参考这篇文章(http://blog.csdn.net/a398942089/article/details/51970691),先把环境搭建起来,跑起来个案例玩玩~,结果却发现,此人带领我们走了无数的坑!
坑列表:
1、他只提供了代码片段。
2、fnlp包,maven项目不支持!只能搞本地。
3、代码运行的逻辑思维,文件加载顺序没有说清楚!对小白来说很容易导致报错!
怎么小编也是一名java极客!还难不倒小编,经过稍微那么调试,完美跑通success!
大致步骤如下:
1. 准备开发环境和原始数据 (用小编提供的普通javaweb项目,import导入到eclipse或者myeclipse即可!)
链接:http://pan.baidu.com/s/1dEWhwTr 密码:tqyj
2. 分词,格式转换
执行TestFC.java:要修改的地方:File outfile = new File("E:/javaproject/myeclipse2017/dl4j/resources/tlbb_t.txt");
这个outfile输出的分词结果 ,把 E:/javaproject/myeclipse2017/ 换成你项目的地址即可!
3. 构建Word2Vector模型并训练
执行 :ZhWord2Vector.java
4. 测试并输出
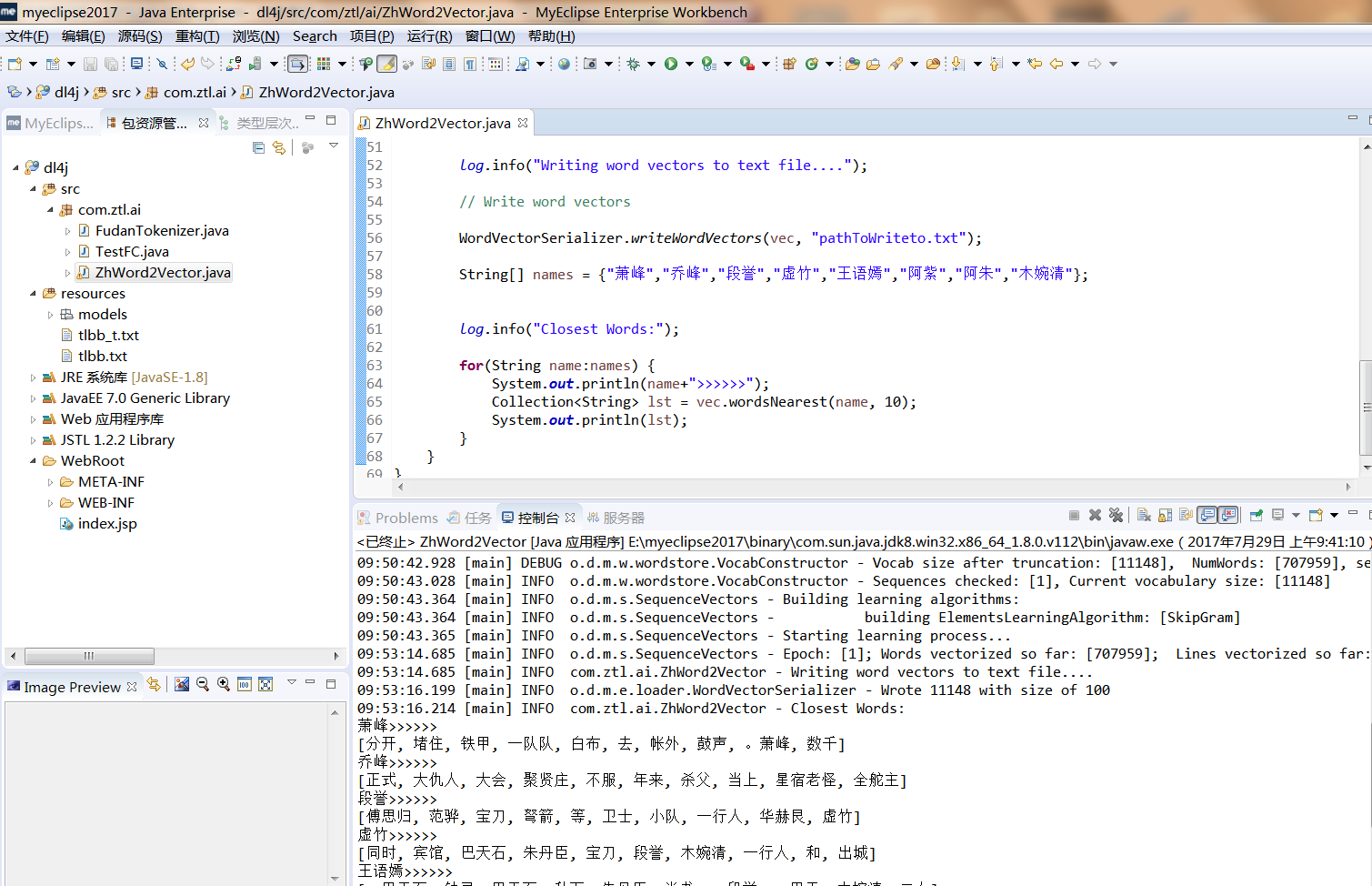
这就是计算机阅读天龙八部的结果,因小说文本分词结果不够好!导致计算机读出来的结果稍微有那么丢丢偏差!
我也看了下分词结果,百分之70以上的分词还可以,有些4个字的俗语,和成语,就没有分好!
所以:WORD2VEC训练和匹配等,并没有那么精确,还需要不断调整和训练!
萧峰>>>>>>
[分开, 堵住, 铁甲, 一队队, 白布, 去, 帐外, 鼓声, 。萧峰, 数千]
乔峰>>>>>>
[正式, 大仇人, 大会, 聚贤庄, 不服, 年来, 杀父, 当上, 星宿老怪, 全舵主]
段誉>>>>>>
[傅思归, 范骅, 宝刀, 弩箭, 等, 卫士, 小队, 一行人, 华赫艮, 虚竹]
虚竹>>>>>>
[同时, 宾馆, 巴天石, 朱丹臣, 宝刀, 段誉, 木婉清, 一行人, 和, 出城]
王语嫣>>>>>>
[。巴天石, 钟灵, 巴天石, 私下, 朱丹臣, 尚书, 。段誉, 。巴天, 木婉清, 二女]
阿紫>>>>>>
[萧大, 马前, 眼眶, 来, 只听, 卫士, 黄袍, 北门, 牵过, 帐外]
阿朱>>>>>>
[恩情, 变心, 心甘情愿, 那样, 欢喜, 送给, 宠爱, 夫妻, 欢心, 喜爱]
木婉清>>>>>>
[。巴天石, 范骅, 秦红棉, 钟灵, 巴天石, 刀白凤, 朱丹臣, 甘宝宝, 一行人, 二女]
运行过程,跟个人机器jvm性能又那么一丢丢关系,我运行一般3分钟左右,如果机子差一点的话,运行个10多分钟,也是很正常的!

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


