1 一元线性回归
最小二乘法:如上图中屏幕上那么多红点表示为一堆X、Y值,即为{(Xi,Yi)}(i=0,1,…,m),就是要找到一条直线,最好的表达这些点的冥冥中的方向。数学上就用点到线距离的平方和累计最小来算。
这个直线的函数就称为最小二乘解,求解这个函数的解法称为最小二乘法。

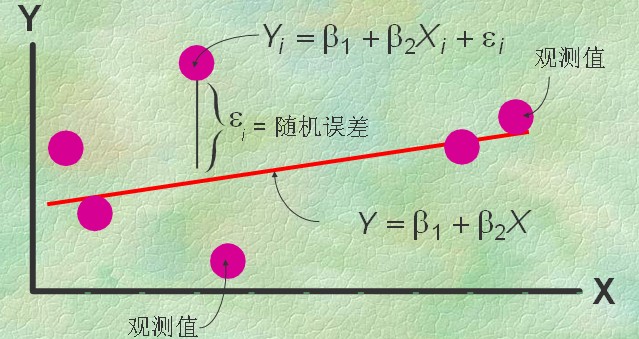
样本回归模型:

残差平方和

通过导数求极值
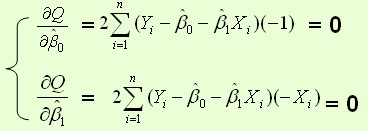
即为结果:
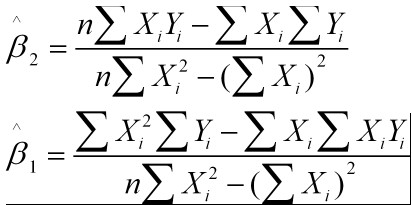
举例说明:
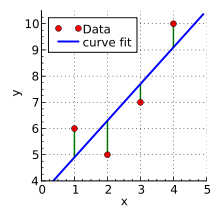
题干:有4个点(x,y):{(1,6),(2,5),(3,7),(4,10)},我们想找一条最能表达这4个点的趋势的直线y=b1+b2*x,即找出在某种“最佳情况”下能够大致符合如下超定线性方程组的b1和b2:
b1+1*b2=6
b1+2*b2=5
b1+3*b2=7
b1+4*b2=10
最小二乘法采用的手段是尽量使得等号两边的方差最小,也就是找出这个函数的最小值:
S(b1,b2)=[6-(b1-1*b2)]^2+[5-(b1-2*b2)]^2+[7-(b1-3*b2)]^2+[10-(b1-4*b2)]^2
最小值可以通过对S(b1,b2)分别求b1和b2的偏导数,然后使它们等于零得到。
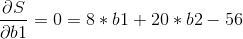

这个方程组只有两个未知数,容易解得:b1=3.5
b2=1.4
所以直线y=3.5+1.4x是最佳的。
方法:
人们对于某一变量t或者多个变量t1、t2、t3构成的相关变量y感兴趣。

用q个独立变量或者p个系数去拟和(翻译成中文真是2B啊,拟和谁能明白是啥意思,不就是像开发的时候,虽然你不知道啥方法好,但也要试着去完成目标嘛,有的时候是假数据,有的时候是对付的,就为老板来视察那天能过关)。
线性函数模型:最简单的线性式子是
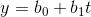 ,矩阵式子如下:
,矩阵式子如下: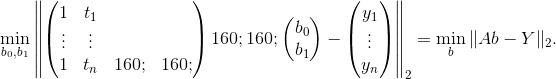
其中
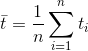 为t值得算数平均值,也可以解得为如下形式:
为t值得算数平均值,也可以解得为如下形式: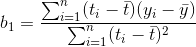
线性回归问题的处理流程:
1、两个变量有关系吗?(画出散点图,直观判断)
2、这些关系可以套数学模型不?(比如
 或者
或者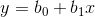 ).
).3、建立回归模型
4、对模型中参数进行估计,最小二乘法是其中一种方法。
5、讨论模型的效果咋样。
最小二乘的几何意义:
高维空间的一个向量在低维空间的投影
杂记:最小二乘估计是唯一方差最小的无偏估计。
参考文献:
一元线性回归模型与最小二乘法及其C++实现
最小二乘法的维基百科
- 一是这些理论其实是在实践中总结的,没有基础的机器学习方法是不能明白理论的;
- 二是这些理论需要的数学很高,您那高等数学啥的就别提了,这些理论至少也得有泛函分析的一般知识、优化理论的一般知识、矩阵理论的一般知识、高等概率论、随机分析等等的数学基础。
- 三是这些理论对于大部分只是想用一下机器学习方法的人,我觉得毫无意义;您要只是想用一下机器学习,这些理论对您估计看过全当娱乐。
(机器学习主要方法)
第二部分,机器学习方法:这部分才是初学者应该学的,也是必须学的。
(按照数据形式,给了大体情况)他按照对数据处理可以分成如下几个部分:
1.监督学习:也就是你的数据都已经处理的很好了,哪些数据是哪种情况都分清楚了。
2.非监督学习:你的数据太原始了,全是一堆数,都不知道哪个是哪个情况。
3.半监督学习:因为监督学习效果好,但是数据要求太高;非监督学习效果不咋地呀,但对数据要求低;那么我们折中一下,先标注一部分数据,然后用监督学习对其他未标注数据进行标注,如果算法产生的准确率在某个参数以下,则将这个数据给人来标准。
4.迁移学习:比如我们现在有种方法,用在了图书之间的相似分析上,那么这个方法可不可以用在人人网上用户的相关分析上呢?这就是迁移学习。
5.强化学习:根据环境反馈进行学习。
6.“各种乱入学习”:其实,还有很多奇葩的学习方法不是以上五种比较常见的学习方法,他们大体上都是各种奇葩的想法,加上各种有爱的数学理论推导而成。因为还不是十分的成熟,所以初学者也不必太纠结这部分。
(我们一般处理的数据,都是啥样的呢?)
我们处理的数据,一般来说是表状的,说白了,就是——每一条数据就是一个向量(前几天看到有个孩子说向量是有方向的,我觉得特无语,= =!,现在就连物理学里面的向量你都想象不出他的方向了,虽然向量可以想象成几何形体,这是分析的基础,但是不要拘泥于几何) 。既然每一条数据是一个向量,那么很显然所有数据构成了一个向量空间。这个向量空间一定要有一定的抽象想象能力,不光是欧式空间,还可能是拓扑空间。。。马上你就会知道为啥了。
那知道了如上内容。我们看看机器学习最基础最核心的有哪些方法,当然如果你看的书里面超出这个,请不要惊讶,我只是列举了非常非常常用而常见的方法。
(最常见的机器学习方法 = 基础方法 * 拓展方法 * 应用领域)
(基础方法)
1.关联分析:现在数据是一条条的销售记录,我们要找出其中哪些商品经常被一起买,这个到时候会有两个主要方法:Apriori方法,主要就是剪枝,和他相识的有AIS和STEM,其中STEM是针对SQL语言使用的关联分析算法;FP-growth,主要是建立一个树,通过这个结构加速算法;还有垂直关联挖掘、数组方法。
2.决策树:有一个叫读心术的应用,他不断让你提供你心中所想的人的信息,进行不断的推演最终找到你所想的人。这个应用看似神奇,其实说白了用决策树就可以大概做一个。决策树就是一颗树,树的每个边上都有条件,根节点是起始节点,叶节点是结果节点;从根节点,不断的依据边上的信息移动到相应的树节点上,直到叶节点,给出结果。这就是决策树。决策树是一大类算法,主要有ID3、C4.5等等。
3.感知器:还记得我刚才说的向量空间么?每一个向量都可以表示为空间中的一个点,那如果我们可以找到一条直线把所有点分为两部分,一部分都是A类,另一部分都是B类。那么我们以后还有一个点,我们只要看他在直线的哪边就可以直接判定他的类别。感知器是一大类算法,算法太多了,不一一枚举。
4.支持向量机:感知器的升级版。如果学过泛函的同学,都知道完备的内积空间就是Hilbert空间,核方法可以在Hilbert空间上进行。支持向量机就是使用了间隔最大原则和核方法来对感知器进行改进,从而得到相对好的效果。支持向量机,是一大类算法。
5.反馈神经网络:感知器的升级版。感知器是一个线性函数,如果多个线性函数互相嵌套,而且使用非线性动力提供复杂的向量空间曲面描述,我们会得到比感知器更好的效果。= =!提问支持向量机和反馈神经网络杂合是啥?
6.神经网络:其实神经网络包括反馈神经网络。之所以把反馈神经网络单独提出来,是因为用的太多,而且他是继承感知器的。但是神经网络本身可是一个非常非常非常非常丰富的一大大大类算法,而且错综复杂。我尝试分个类吧,主要有层次网络、时延神经网络、耦合神经网络、自组织神经网络、递归神经网络(和时延神经网络有点像,但是在连续和离散量上有些许的不同,连续可用模拟电路实现)、径向基函数网络(这个其实是正则化的网络,一般用的RBF网络就是反馈神经网络T-正则化)、集成神经网络、模糊神经网络、玻尔兹曼机(使用退火算法的一种网络)、概率神经网络等等等等等等。当然还有神经场理论,需要微分几何的知识,属于机器学习的基础理论,初学者可以无视。当然还有人试图设计神经网络计算机,初学者也可以无视。当然神经网络可是很神奇的,他连PCA、ICA、LDA(线性判别分析)、LDA(隐藏地理特来分布)啥的都可以用神经网络学习。
7. 统计判决方法:是依据统计理论设计的统计判决理论。其实,统计判决是很实用的理论,而且其中包含的很多方法都在各个机器学习领域应用,比如最小化最大损失、贯序判决、参数估计等等。朴素贝叶斯就是其中的一个。这也是一大类算法。
8.贝叶斯网络:推理和规划理论支持的一个理论。
9.序列分析方法:就是分析一个序列的学习。语言就是一个文字的序列,所以诸如隐马尔科夫方法啥的。
10.逻辑回归:如果你学习过生态学,你对逻辑方程和逻辑回归就毫不陌生,其实这个和感知器是一个尿性的东西。他和隐马尔科夫模型的学习可以用到一个叫最大熵原则。其实最大熵原则是可以在信息论下被用变分法中的柯西-拉格朗日方程推出来的,这也是Duda的《模式分类》后的一道习题。
11.聚类方法:我们有一堆数据,我们想知道他们自己之间的哪些是一类。也是一大类方法,常用的有:k-均值、层次聚类、密度分布聚类、模型聚类、图聚类算法(包括蚁群聚类)。
12.数据处理方法:比如主成分分析(PCA)、线性判决LDA、独立分析ICA等等。
13.其他:抱歉,我虽然写了一些,但觉得基础中的基础,貌似好像还不止这些,归纳起来貌似有些困难。不过其实主要的应该就是如上了吧。欢迎补充。
(拓展方法)
1.在线化:因为我们知道,现在的数据都是不断的来,不断的更新。但由于数据巨大,我们不能每更新一次,我们就重新计算一次,所以让算法对增量有办法的方法叫在线化。基础方法都可以查到他们的在线化方法。
2.分布式和并行化:这个还是针对大数据,提供以上所有基础方法的分布式和并行化方法。
3.修正过拟合方法:由于以上基础方法中大部分都存在过拟合问题,说白了就是对数据中的噪声进行了拟合,使得学习效果变差,本来应该得到的信息是y=x+1 , 而现在得到的信息是y=(x^100+1)/(x^99+1)+1。。显然后一种得到的太过于精密,反而效果不好了。以上大部分基础方法都可以用修正过拟合的方法来修正。其中正则化就是一个比较好的方法。
4.各种数学乱入的方法:没错,你没看错,各种数学乱入呀。比如模糊数学乱入,产生一堆新方法:模糊SVM、模糊神经网络啥的。再比如比较综合的数学乱入,商空间和粒运算啥的。再比如李群:李群机器学习。再比如微分几何乱入,有什么流形学习。这些我觉得,看过全当娱乐吧。
(应用领域)
1.应用到图,摇身一变为图挖掘。
2.应用到数据库和数据仓库中,摇身一变为数据挖掘。
3.应用到社交网络中,摇身一变为网络科学。
4.应用到自然语言处理中,摇身一变为统计自然语言处理(多有错误,全当娱乐)。
5.应该到你的领域。。。。摇身一变。。。。 。。
其实,我觉得,你要是真的能对机器学习有个大体脉络的了解,书单也无所谓。你照着上面的东西,百度出一些博客看看,可能更适合你。或者你去找一些论文,也行。
其实,我觉得,你在亚马逊检索机器学习,第一页的书我应该是全看了,第二页的书大部分都看了,第三页亦然。。。。。你也可以这么做。。。
如果你非要推荐的话:
1.Duda的《模式分类》。其实我个人更喜欢《现代模式识别》这本书,但是由于国人的崇洋媚外情绪实在太严重,确实国内很多书抄袭现象严重、基本上出书目的就是为了出书,根本不是给人看到。但也不能否认国内也很多好书!
2.《现代模式识别》(第二版),真心是好书,在我个人看法,完胜Duda那本无疑。
3.Mitchell的《机器学习》。
4.第一本和第二本,数学都需要很多,买书或者借书,请务必看清前面序言中的关于数学知识部分的说明,否则您就只有一个劲的补数学了。第三本其实数学需要的不多,但内容太少,而且涉及一些浅显的机器学习理论,也比较麻烦。这倒不如《机器学习引论》(An Introduce To Machine Learning),这本可以说用了最少的数学知识,讲了一些内容,也很薄,很好看。
其实,够了。为啥呢?因为问我看哪方面书的人挺多的(因为我觉得我成天就看书、看论文啥的)。
但他们反复的问,貌似你推荐他们几本,他们看了看或者没看,就又要你推荐。。。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


