Per Harald Borgen 将和我们分享他如何在一年内掌握机器学习知识的经历,并在工作中完成了第一个机器学习项目,包括使用各种各样的机器学习和自然语言处理技术,使 Xeneta 的潜在客户达到合格标准。在 Per Harald Borgen看来,他并不认为只有获得博士或硕士学位的人才能在机器学习方面更加专业。“研究机器学习并不需要你数学学得很好,也不需要你一定要取得什么样的学位。”*
如果你对机器学习抱有好奇又心存敬畏,不妨看看这篇文章。
入门:Hacker News (黑客新闻)和 Udacity (优达学城)
我对机器学习的兴趣开始于 2014 年。那时候我刚开始在 Hacker News 上阅读有关它的一些文章。然后我就发现通过检测数据来教会机器做一些事情,这种想法十分有趣。当时的我甚至连一个专业的开发员都不算,只能算是一个业余编码员,但我还是想试一试。所以我就开始看 Udacity 的监督学习课程的前几章,并同时开始阅读有关这方面的所有文章。

尽管没有掌握到实践技能,但我还是对机器学习的概念有了一定的认识。但由于我很少听大规模在线开放课程,所以并没有听完。
“成功”挂掉Coursera 机器学习课程
2015 年 1 月,我参加了伦敦的“创始人和程序员”训练营地(FAC bootcamp),想成为一名程序员。几周过后,我想学习如何码机器学习算法,于是我就和几个同伴成立了一个学习小组。每周二晚上,我们都会在 Coursera 上观看机器学习课程。

这个课程很棒,我也学到了很多。但是对于一个初学者来说,课程内容太难,因此我必须要一遍遍反复观看才能掌握要点。与此同时, Octave 编码任务也同样十分具有挑战性,尤其是如果你不了解 Octave 的话。后来,因为难度太大,小伙伴们一个个都放弃了,再后来,我自己也最终放弃了。
事后,我意识到,我应该找一个适合我的课程来听。要么是用机器学习图书馆来进行编码任务,而不是从头创建算法,又或者至少是用我了解的编程语言。对于新手来说,学习一门新的语言,并同时编码机器学习算法,实在是太难了。
如果我及时发现的话,我会选择 Udacity 的《机器学习介绍》这门课程,因为它更加简单并且采用 Python 和 Scikit 学法。用这种方法,我们可以尽快上手,获得自信,同时也更加有趣。
习得:从简单和实际的东西开始学,而不是困难和理论性的。
为期一周的机器学习
我在 FAC 最后进行的努力就是每周的机器学习汇演。我的目标是在此次训练周即将结束的时候,能够运用机器学习来解决一些实际问题。最终我成功了。在这一周时间内我做了下列这些事情:
逐步了解 Scikit 学习
在真实的全球数据集上尝试了机器学习
从头编码了一个线性回归算法(用 Python )
做了一点点自然语言处理
这是到目前为止我所经历过的最曲折的机器学习的学习曲线了。如果你想了解更多详细情况的话,就请继续读这篇文章吧。
习得:用一周的时间让自己完全沉浸于一个新的项目当中,这是极为有效的。
神经网络?我也挂了
在结束了伦敦的 FAC 训练营地之后,我又回到了挪威。我试图复制之前在机器学习周所取得的成功,将其用于神经网络,结果失败了。因为有太多的事情来分散我的精力,因此我无法每天花 10 个小时的时间来编码和学习。我这才发现环境的重要性,因为之前在 FAC 训练营地的时候,周围都是机器学习的爱好者。
习得:在做这类学习的时候,让自己处在一个积极向上的环境之中。
但是,至少我开始着手从事了神经网络的研究,并且也慢慢掌握了要领。终于到了 7 月 1 日,我成功编写了我的第一条网络。它可能没有什么价值,并且于我而言也没什么可炫耀的,但这至少证明我了解了反向传播和梯度下降的概念。
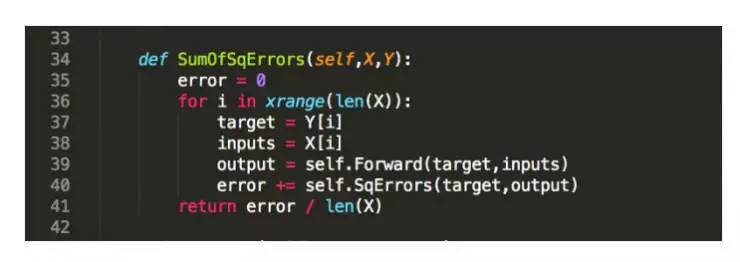
在后半年,由于我找了新的工作,因此项目进展开始缓慢下来。这一时期最重要的收获就是从神经网络非向量化到向量化实施的重大飞跃,这其中包括从大学就一直重复的线性代数。在年底的时候,我写了一篇文章来对我的学习进行总结。
测验 Kaggle 竞赛
在 2015 年圣诞假期的时候,我再一次鼓起勇气,决定试验 Kaggle 。因此我花了相当一段时间来试验各种算法,用于测试 Kaggle 的住宅报价转换,奥托集团产品分类,以及自行车共享需求竞赛。
通过试验各种算法和数据,使结果得到不断改善,这是我在这次尝试中最大的收获。
我学会了要在做机器学习时相信自己的逻辑。此外,倘若调整一个参数或者设计一个新的特征在逻辑上看来行得通的话,那么它在实际应用当中也可能会有所帮助。
在工作中安排日常学习
2016 年 1 月,假期结束之后我又重新回归工作,我想要继续圣诞假期的研究,因此我就问我的经理是否可以让我在上班时间花一些时间来学习。他欣然同意了。在对神经网络有了一个基本的了解之后,我想继续进行深入学习。
Udacity 的深度学习
我首先尝试的是 Udacity 的深度学习课程,但结果令我十分失望。课程的内容很好,但是对我来说太短太浅显了。除此之外, IPython Notebook 任务的结果也十分令人沮丧。我花了大多数的时间来调试代码缺陷,结果在连续工作数周之后,当初的热情逐渐退却,到最后我基本上就放弃了。对于我来说,谈到 IPython Notebooks ,我完全是个新手。所以比起我,你们的结果或许并不会像我一样这么坏。可能是我还没有准备听这个课程吧。
斯坦福的深度学习自然语言处理
幸运的是,我后来又发现了斯坦福的 CS224D ,然后就决定试一试。这个课程很棒。尽管很难,但是在做问题设置的时候,我从没放弃过调试。其次,它们也确实给了你解决方案的代码。我在遇到困难时常常会看一下这些代码,以便能让自己的工作倒回去,重新去搞清楚达成解决方案所需的步骤。
尽管我还没有完成,但这已经大大提升了我在自然语言处理和神经网络方面的知识。
然而这一过程真的十分艰辛。我一度认为自己需要一个比我好的人来帮助我,于是我找到了一个博士在读学生,给他每小时 40 美元的报酬,他欣然接受。他帮助我解决问题设置和整体认识上的问题,而他的帮助对我来说是至关重要的,因为他发现了我很多知识上的黑洞。
习得:以每小时 50 美元的报酬就有可能找到一个很好的机器学习领域的老师。如果你付得起的话,这绝对值得。
提升 Xeneta 的销售额
在做了以上所有工作之后,我觉得自己已经准备好在工作中做一项机器学习项目了。该项目旨在训练出一套算法,利用该算法,通过阅读企业描述来使 Xeneta 的潜在客户达到合格标准。这对于销售部门的员工来说,将节省大量的时间。
走到这一步确实是一个漫长的旅程。但其实也很快。在我开始第一周的项目时,我完全没想过自己能在一年的时间内熟练使用机器学习。但是这是完全有可能的。如果我能做,那么其他人也一定可以。
2016 年底,Google DeepMind 开源了它们的机器学习平台 — DeepMind Lab。尽管像霍金教授这样的专家曾就人工智能技术发出过警告,谷歌仍决定向其他开发人员开源其软件,这也是它们进一步发展机器学习能力的一部分。
他们不是唯一一家这样做的科技公司,Facebook 去年开源了其深度学习的软件,Elon Musk 的非营利组织 OpenAI 也发布了 Universe,这是一个可用于训练 AI 系统的开放软件平台。所以,为什么谷歌、OpenAI,以及其他的公司或机构都选择开源了它们的平台,这将会对机器学习的采用产生怎样的影响?
为什么开源机器学习?
上面所提到的例子给了我们美好的愿景,其实如果仔细观察,会留意到机器学习一直是开源的,而且开放的研发是机器学习有如今这样关注度的根本原因。
通过向公众提供自己学习平台,Google 已经验证了其 AI 研究的意识越来越高。这样做其实有很多优点,例如可为 Alphabet 发掘到新的人才和有能力的创业公司。同时,开发者能访问 DeepMind Lab 将有助于解决他们研究机器学习的一个关键问题 —— 缺乏训练环境。OpenAI 为 AI 推出了一个新的虚拟学校,它使用游戏和网站来训练 AI 系统。
目前非常需要向公众提供机器学习平台这样的举动。
5 个开源机器学习项目的优势
重现科学的结果和公平的比较算法:在机器学习中,经常使用数值模拟来提供实验验证和方法比较。这种方法之间的比较是基于严格的理论分析的。开源工具和技术提供了一个机会,可以使用公开的源代码彻底地进行研究,而不依赖于提供方。
快速查找和修复 bug:当你使用开源软件执行机器学习项目时,易于检测和解决软件中的 bug。
以低成本、重用的方法加快科学研究的发展:众所周知,科学的进步总是以现有的方法和发现为基础,机器学习领域也不例外。机器学习中开源技术的可用性可很好地将大量现有资源投入研究和项目。
长期的可用性和支持:无论是个人研究者、开发者,还是数据科学家,开源可能都可以作为一种媒介,以确保每个人都可以在改变工作后使用他/她的研究或发现。因此,通过在开源许可证下发布代码可增加获得长期支持的机会。
各行业更快地采用机器学习技术:开源软件有显著的典范,它支持着创建数十亿美元的机器学习公司和行业。研究人员和开发者采用机器学习的主要原因是有免费提供高质量的开源实现。
加快开源机器学习的采用曲线
开源机器学习的进步将使得人工智能的采用曲线更加陡峭,从而促使开发者和创业公司努力使 AI 更智能。软件平台的可用性正在改变企业开发 AI 的方式,促使他们跟随 Google,Facebook 和 OpenAI 的脚步进行更透彻的研究。
开放机器学习平台的转变是确保 AI 可为每个人所用而不是只被掌握在少数技术巨头手中的重要阶段。
个人认为,科技巨头发布开源机器学习项目有三个原因:
雇佣已经与开源社区接触并通过开源项目建立了对机器学习的认识的工程师
控制一个机器学习平台,使它们为自己更广泛的 SDK 或云平台策略更好地工作
发展整个市场,因为他们的市场份额已经达到了饱和点
当一家创业公司发布一个开源项目时,它会引起注意,其中一些会被转化为付费客户和招聘。根据创业公司自己的定义,他们是尝试在特定市场上立足,而不是扩大现有市场。开源是无摩擦的,为另一个用户提供服务并使组织能够解决实际问题不会花费任何东西,从而使代码具有更大影响。
开源打破了建立专利技术的公司的限制。其中一个连锁效应可能是关注价值所在的转变,随着整个 AI 技术的商业化,关注点已从核心机器学习技术转向构建最佳模型,这需要大量的数据和领域专家来创建和训练模型。对于这点,具有网络影响力的大型企业具有天然优势。
开源机器学习中的最佳框架
现在有大量的开源机器学习框架,使机器学习工程师能够:
- 构建、实施和维护机器学习系统
- 生成新项目
- 创建新的有影响力的机器学习系统
一些重要的框架包括:
- Apache Singa 是一个通用、分布式、深度学习的平台,用于在大型数据集上训练大型深度学习模型。它被设计有基于层次抽象的本能编程模型。支持各种流行的深度学习模型,包括卷积神经网络(CNN),受限玻尔兹曼机(RBM),以及循环神经网络(RNN)等能量模型。为用户提供了许多内置图层。
- Shogun 是历史最悠久,也是最受尊敬的机器学习库之一。Shogun 于 1999 年创建,采用 C++ 编写,但不只限于在 C++ 中使用。感谢 SWIG 库,Shogun 可用于以下编程语言和环境:
- Java
- Python
- C#
- Ruby
- R
- Lua
- Octave
- Matlab
Shogun 旨在面向广泛的特性类型和学习环境进行统一的大规模学习,如分类、回归、降维、聚类等。它包含了几项独有的最先进的算法,如丰富的高效 SVM 实现,多内核学习,内核假设检验,以及 Krylov 方法等。
- TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。TensorFlow 使用数据流图进行数值计算,通过节点(Nodes)和线(edges)的有向图来阐述数学计算。节点在图中表示数学操作,也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。图中的线则表示在节点间相互联系的多维数据数组,这些数据 “线” 可以输运 “size 可动态调整” 的多维数据数组,即 “张量”(tensor)
- Scikit-Learn 通过构建在数个现有的 Python 包(NumPy,SciPy 和 matplotlib)之上,用于数学和科学工作,充分利用了 Python 的广度。生成的库可以用于交互式 “工作台” 应用程序,也可以嵌入到其他软件中并重用。该套件在 BSD 许可证之下发布,因此它完全是开源和可重用的。Scikit-learn 包括许多用于标准机器学习任务(如聚类,分类,回归等)的工具。由于 scikit-learn 是由一大群开发者和机器学习专家开发的,所以新技术有希望会很快被引入。
- MLlib (Spark) 是 Apache Spark 的机器学习库。其目标是使实用的机器学习具有更好的可扩展性和易于使用。它由常见的学习算法和实用程序组成,包括分类、回归、聚类、协同过滤、降维,以及较底层的优化原语和高层的管道 API。Spark MLlib 被认为是在 Spark Core 之上的分布式机器学习框架,主要由于其分布式的基于内存的 Spark 架构,几乎是 Apache Mahout 使用的基于磁盘的实现的九倍。
- Amazon Machine Learning 是一项使任何技能水平的开发者都能轻松使用机器学习技术的服务。Amazon Machine Learning 提供了可视化工具和向导,指导你完成创建机器学习(ML)模型的过程,而无需学习复杂的 ML 算法和技术。它连接到存储在 Amazon S3,Redshift 或 RDS 中的数据,可以对所述的数据运行二进制分类,多类分类或回归,以创建一个模型。
- Apache Mahout 是 Apache 软件基金会的一个自由开源项目。目标是为协作过滤、聚类和分类等多个领域开发免费的分布式或可扩展的机器学习算法。Mahout 为各种数学运算提供了 Java 库和 Java 集合。Apache Mahout 是使用 MapReduce 范例在 Apache Hadoop 之上实现的。如果大数据存储在 Hadoop 分布式文件系统(HDFS)中,Mahout 提供的数据科学工具,可以在这些大数据集中自动找到有意义的模式,从而将这些大数据快速轻松地转化为 “大信息”。
最后要说的机器学习确实可以在开源工具的帮助下解决真正的科学技术问题。如果机器学习是为了解决真正的科学技术问题,社区需要建立在彼此的开源软件工具之上。我们认为,机器学习开源软件有一个紧急需求,它将满足多个角色,其中包括:
- 更好的方法来重现结果
- 为质量软件实施提供学术认可的机制
- 通过站在其他人的肩膀(不一定是技术巨头)上以加速研究过程

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


