2.6 识别和消除笛卡尔积
您希望在部门10中返回每个员工的姓名以及部门的位置。以下查询正在返回不正确的数据:
select e.ename, d.loc
from emp e, dept d
where e.deptno = 10
ENAME LOC
---------- -------------
CLARK NEW YORK
CLARK DALLAS
CLARK CHICAGO
CLARK BOSTON
KING NEW YORK
KING DALLAS
KING CHICAGO
KING BOSTON
MILLER NEW YORK
MILLER DALLAS
MILLER CHICAGO
MILLER BOSTON
正确的结果集如下:
ENAME LOC
---------- ---------
CLARK NEW YORK
KING NEW YORK
MILLER NEW YORK
解 :使用FROM子句中的表之间的连接来返回正确的结果集:
1 select e.ename, d.loc
2 from emp e, dept d
3 where e.deptno = 10
4 and d.deptno = e.deptno
讨论查看DEPT表中的数据:
select * from dept
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
您可以看到10号部门在纽约,因此您可以知道纽约以外的任何位置的退回雇员是不正确的。错误查询返回的行数是FROM子句中两个表的基数的乘积。在原始查询中,部门10的EMP上的过滤器将导致三行。因为DEPT没有过滤器,所以返回DEPT的所有四行。三乘四是十二,所以不正确的查询返回十二行。
一般来说,为避免使用笛卡儿乘积,您将应用n1规则,其中n表示FROM子句中的表数,n1表示避免笛卡尔乘积所需的最小连接数。根据表中的键和连接列,您可能需要超过n1个连接,但n1是编写查询时开始的好地方。
2.7、聚集和联接
您想要找到10部门员工的工资总和以及奖金的总和。一些员工有多个奖励,表EMP和表EMP_BONUS之间的加入导致由集合函数SUM返回的不正确的值。对于此问题,表EMP_BONUS包含以下数据:
select * from emp_bonus
EMPNO RECEIVED TYPE
----- ----------- ----------
7369 2015-03-14 23:26:43 1
7900 2015-03-24 23:27:10 2
7788 2015-03-21 23:27:30 3
7369 2015-03-21 23:27:30 1
现在,考虑以下查询,返回部门20中所有员工的工资和奖金。表BONUS.TYPE确定奖金的数额。 1类奖金是员工工资的10%,2类为20%,3类为30%。
select e.empno,
e.ename,
e.sal,
e.deptno,
e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 20
EMPNO ENAME SAL DEPTNO BONUS
7369 smith 800 20 80
7788 scott 3000 20 900
7369 smith 800 20 80
到现在为止还挺好。但是,当您尝试加入EMP_奖励表时,为了计算奖金数额,事情会出现错误:
select deptno,
sum(sal) as total_sal,
sum(bonus) as total_bonus
from (
select e.empno,
e.ename,
e.sal,
e.deptno,
e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 20
) x
group by deptno
DEPTNO TOTAL_SAL TOTAL_BONUS
------ ----------- -----------
20 4600.00 1060.000
当TOTAL_BONUS正确时,TOTAL_SAL不正确。第20部门的所有工资总和为10875.00,如下所示:
select sum(sal) from emp where deptno=20
SUM(SAL)
----------
10875.00
为什么TOTAL_SAL不正确?原因是连接创建的SAL列中的重复行。考虑以下查询,它连接表EMP和EMP_ BONUS:
因为emp_bonus 中有重复的员工号,导致重复,影响结果的准确。
select e.ename,
e.sal
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 20
ENAME SAL
---------- ----------
smith 800
scott 3000
smith 800
现在很容易看出为什么TOTAL_SAL的值不正确:smith 的工资是两次计数。你真正追求的最终结果是:
DEPTNO TOTAL_SAL TOTAL_BONUS
------ --------- -----------
20 10875 1060
执行只有DISTINCT工资的总和:
select deptno,
sum(distinct sal) as total_sal,
sum(bonus) as total_bonus
from (
select e.empno,
e.ename,
e.sal,
e.deptno,
e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 20
) x
group by deptno
该配方的“问题”部分中的第二个查询与表EMP和表EMP_BONUS相连,并为员工“MILLER”返回两行,这是导致EMP.SAL(的工资加上两次)的错误的原因。
解决方案是简单地求和查询返回的不同的EMP.SAL值。
以下查询是一种替代解决方案。
首先计算部门10中所有工资的总和,然后将该行连接到表EMP,然后将其连接到表EMP_BONUS。 以下查询适用于所有DBMS:
select d.deptno,
d.total_sal,
sum(e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3 end) as total_bonus
from emp e,
emp_bonus eb,
(
select deptno, sum(sal) as total_sal
from emp
where deptno = 20
group by deptno
) d
where e.deptno = d.deptno
and e.empno = eb.empno
group by d.deptno,d.total_sal
函数SUM OVER被称为两次,首先计算定义的分区或组的不同工资的总和。 在这种情况下,分区为DEPTNO 20,DEPTNO 20的不同工资的总和为10875.下一次调用SUM OVER计算相同定义分区的奖金总和。 最终结果集是通过取TOTAL_SAL,DEPTNO和TOTAL_BONUS的不同值来生成的。
2.8、在多个表返回丢失的数据。
在mysql中同时返回多个表容易丢失的数据,因为多个表中,使用联接查询,如果关联数据没有关联上,那么没有关联上的这部分数据就会丢失!
mysql中不支持full join ,这点很恶心,但是它有union关键字来联接结果集。只是稍微有些不灵活!
解决方案:
select d.deptno,d.dname,e.ename
from dept d right outer join emp e
on (d.deptno=e.deptno)
union
select d.deptno,d.dname,e.ename
from dept d left outer join emp e
on (d.deptno=e.deptno)
2.9、在运算和比较时,使用null值
查找EMP中所有员工的佣金(COMM)小于雇员“WARD”的佣金。 还应包括具有空佣金的雇员
select ename,comm
from emp
where coalesce(comm,0) < ( select comm
from emp
where ename = 'WARD' )
三、 日期运算
3.1、例如,使用HIREDATE为员工CLARK,您想返回六个不同的日期:CLARK之前和之后五天被雇用,CLARK被雇用前五个月,最后是CLARK之前和之后的五年。 CLARK被雇用于“09-Jun-1981”,因此您希望返回以下结果集:
select hiredate - interval 5 day as hd_minus_5D,
hiredate + interval 5 day as hd_plus_5D,
hiredate - interval 5 month as hd_minus_5M,
hiredate + interval 5 month as hd_plus_5M,
hiredate - interval 5 year as hd_minus_5Y,
hiredate + interval 5 year as hd_plus_5Y
from emp
where deptno=10
3.2、您希望找到雇员ALLEN和员工WARD的HIREDATE(聘用日期)之间的差异
select datediff(ward_hd,allen_hd)
from (
select hiredate as ward_hd
from emp
where ename = 'WARD'
) x,
(
select hiredate as allen_hd
from emp
where ename = 'ALLEN'
) y
3.3 确定两个日期之间有多少工作日。(排除周六、周日。)
查询员工BLAKE和员工JONES 差了多少工作日
直接给定两个日期,求出工作日数量:
SELECT
5 *(
DATEDIFF('2017-06-11',
'2017-06-01') DIV 7
) + MID(
'0123444401233334012222340111123400001234000123440',
7 * WEEKDAY('2017-06-01') + WEEKDAY('2017-06-11') + 1,
1
) +1 WorkingDays
FROM DUAL
1、创建索引表
create table t500(
id INT(3)
);
2、插入索引数据
delimiter //
create procedure myproc()
begin
declare num int;
set num=1;
while num < 501 do
insert into t500 (t500.id) values (num);
set num=num+1;
end while;
end//
call myproc();
3、查询方案
select sum(case when date_format(
date_add(jones_hd,
interval t500.id-1 DAY),'%a')
in ( 'Sat','Sun' )
then 0 else 1
end) as days
from (
select max(case when ename = 'BLAKE'
then hiredate
end) as blake_hd,
max(case when ename = 'JONES'
then hiredate
end) as jones_hd
from emp
where ename in ( 'BLAKE','JONES' )
) x,
t500
where t500.id <= datediff(blake_hd,jones_hd)+1
3.4、确定两个日期之间的月份数,年数
求第一个员工和最后一个员工聘用之间相差的月份数,并折合成年数
select mnth, mnth/12
from (
select (year(max_hd) - year(min_hd))*12 +
(month(max_hd) - month(min_hd)) as mnth
from (
select min(hiredate) as min_hd, max(hiredate) as max_hd
from emp
) x
) y
3.5 确定两个日期之间的秒、分 、小时数
例如,您希望以秒,分钟和小时的形式返回ALLEN和WARD的HIREDATE之间的差异。
select datediff(ward_hd,allen_hd)*24 hr,
datediff(ward_hd,allen_hd)*24*60 min,
datediff(ward_hd,allen_hd)*24*60*60 sec
from (
select max(case when ename = 'WARD'
then hiredate
end) as ward_hd,
max(case when ename = 'ALLEN'
then hiredate
end) as allen_hd
from emp
) x
3.6、 确定当前记录和下一条记录之间相差天数
例如,对于DEPTNO 10中的每个员工,确定聘用他们的日期及聘用下一个员工的日期之间相差的天数。
select x.*,
datediff(x.next_hd,x.hiredate) diff
from (
select e.deptno, e.ename, e.hiredate,
(select min(d.hiredate) from emp d
where d.hiredate > e.hiredate) next_hd
from emp e
where e.deptno = 10
) x
四、高级查找
4.1、查找同一组或分区中之间的差
您希望返回每个员工的DEPTNO,ENAME和SAL以及同一部门的员工之间的SAL差异(即DEPTNO具有相同的值)。 差异应在当前员工和立即雇用的员工之间(您想要查看“每个部门”之间是否存在资历和工资之间的相关性)。
对于在他的部门最后聘用的每个员工,返回“不适用”的差异。 结果集应如下所示:
DEPTNO ENAME SAL HIREDATE DIFF
------ ---------- ---------- ----------- ----------
10 CLARK 2450 09-JUN-1981 -2550
10 KING 5000 17-NOV-1981 3700
10 MILLER 1300 23-JAN-1982 N/A
20 SMITH 800 17-DEC-1980 -2175
20 JONES 2975 02-APR-1981 -25
20 FORD 3000 03-DEC-1981 0
20 SCOTT 3000 09-DEC-1982 1900
20 ADAMS 1100 12-JAN-1983 N/A
30 ALLEN 1600 20-FEB-1981 350
30 WARD 1250 22-FEB-1981 -1600
30 BLAKE 2850 01-MAY-1981 1350
30 TURNER 1500 08-SEP-1981 250
30 MARTIN 1250 28-SEP-1981 300
30 JAMES 950 03-DEC-1981 N/A
使用标量子查询来检索在每个员工之后立即雇用的员工的“HIRE DATE”。 然后使用另一个标量子查询来查找该员工的工资:
select deptno, ename, hiredate, sal,
coalesce(cast(sal-next_sal as char(10)), 'N/A') as diff
from (
select e.deptno,
e.ename,
e.hiredate,
e.sal,
(select min(sal) from emp d
where d.deptno=e.deptno
and d.hiredate =
(select min(hiredate) from emp d
where e.deptno=d.deptno
and d.hiredate > e.hiredate)) as next_sal
from emp e
) x
4.2、跳过表中N行
您希望查询返回表EMP中的所有其他员工; 你想要第一个雇员,第三个雇员,等等。 例如,从以下结果集:
ENAME
--------
ADAMS
ALLEN
BLAKE
CLARK
FORD
JAMES
JONES
KING
MARTIN
MILLER
SCOTT
SMITH
TURNER
WARD
你想返回
ENAME
----------
ADAMS
BLAKE
FORD
JONES
MARTIN
SCOTT
TURNER
查找方案:
select x.ename
from (
select a.ename,
(select count(*)
from emp b
where b.ename <= a.ename) as rn
from emp a
) x
where mod(x.rn,2) = 1
4.3、在外链接使用or逻辑
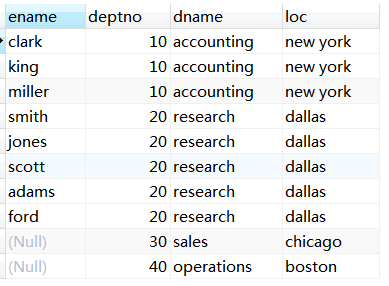
您想要向部门10和20返回所有员工的姓名和部门信息,以及部门30和40的部门信息(但不包括员工信息)。
select e.ename, d.deptno, d.dname, d.loc
from dept d left join emp e
on (d.deptno = e.deptno
and (e.deptno=10 or e.deptno=20))
order by 2
4.4、选择前N个记录
返回最高5档工资的员工姓名和工资
select ename,sal
from (
select (select count(distinct b.sal)
from emp b
where a.sal <= b.sal) as rnk,
a.sal,
a.ename
from emp a
) x
where rnk <= 5
4.5 找到包含最大值和最小值的记录
EMP表中找出最高和最低工资的员工。
select ename ,sal
from emp
where sal in ( (select min(sal) from emp),
(select max(sal) from emp) )
4.6 找到满足条件这样的员工,他的收入比在他后面聘用的员工要少。
select ename, sal, hiredate
from (
select a.ename, a.sal, a.hiredate,
(select min(hiredate) from emp b
where b.hiredate > a.hiredate
and b.sal > a.sal ) as next_sal_grtr,
(select min(hiredate) from emp b
where b.hiredate > a.hiredate) as next_hire
from emp a
) x
where next_sal_grtr = next_hire
解答:
使用子查询来确定每个员工的以下内容:
随后雇用的工资较高的第一人的日期
下一个被聘用的人的日期
当两个日期匹配时,您有您要查找的内容:

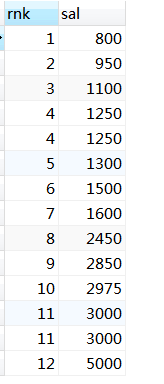
4.7 给结果分等级
给emp表中的工资分等级。
select (select count(distinct b.sal)
from emp b
where b.sal <= a.sal) as rnk,
a.sal
from emp a order by rnk
五、报表运算
5.1、将结果集转为一行。(列变行)
将每个部门的员工数量设置为一行显示:
select sum(case when deptno=10 then 1 else 0 end) as deptno_10,
sum(case when deptno=20 then 1 else 0 end) as deptno_20,
sum(case when deptno=30 then 1 else 0 end) as deptno_30
from emp

5.1、将结果集转为多方行。(列变多行)
正常结果:
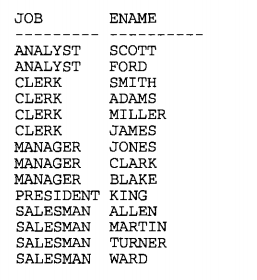
列变多行:
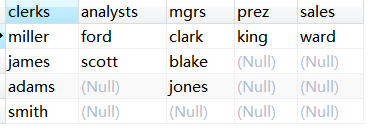
返回每个员工和他的职位
select max(case when job='CLERK'
then ename else null end) as clerks,
max(case when job='ANALYST'
then ename else null end) as analysts,
max(case when job='MANAGER'
then ename else null end) as mgrs,
max(case when job='PRESIDENT'
then ename else null end) as prez,
max(case when job='SALESMAN'
then ename else null end) as sales
from (
select e.job,
e.ename,
(select count(*) from emp d
where e.job=d.job and e.empno < d.empno) as rnk
from emp e
) x
group by rnk
5.2 反向装置结果集 (把5.1的结果进行倒置) (行变列)
select dept.deptno,
case dept.deptno
when 10 then emp_cnts.deptno_10
when 20 then emp_cnts.deptno_20
when 30 then emp_cnts.deptno_30
end as counts_by_dept
from (
select sum(case when deptno=10 then 1 else 0 end) as deptno_10,
sum(case when deptno=20 then 1 else 0 end) as deptno_20,
sum(case when deptno=30 then 1 else 0 end) as deptno_30
from emp
) emp_cnts,
(select deptno from dept where deptno <= 30) dept

5.3 简单的小计
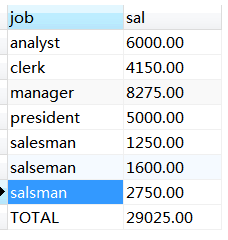
统计emp表中job的工资总和 。
select coalesce(job,'TOTAL') job,sum(sal) sal
from emp
group by job with rollup
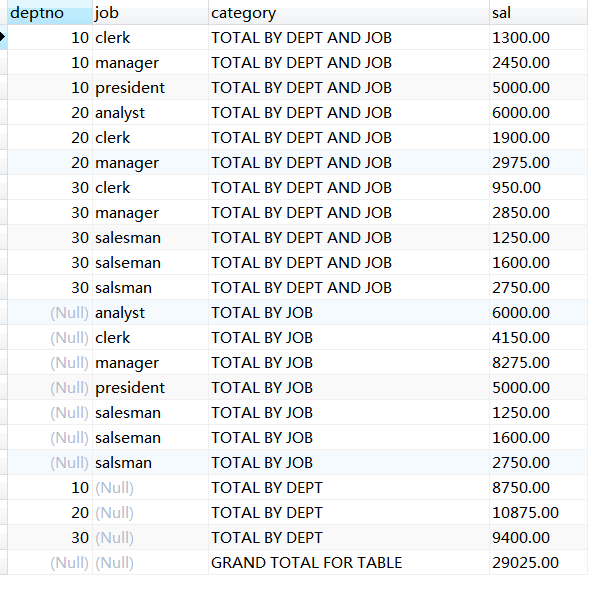
5.4 计算所有表达式的小计组合
select deptno, job,
'TOTAL BY DEPT AND JOB' as category,
sum(sal) as sal
from emp
group by deptno, job
union all
select null, job, 'TOTAL BY JOB', sum(sal)
from emp
group by job
union all
select deptno, null, 'TOTAL BY DEPT', sum(sal)
from emp
group by deptno
union all
select null,null,'GRAND TOTAL FOR TABLE', sum(sal)
from emp
5.5、对不同分组/分区,同时实现聚集
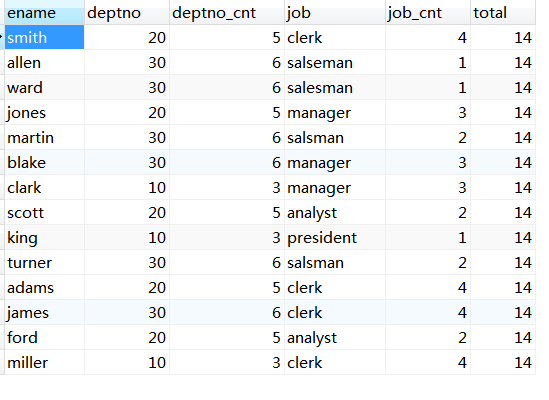
要求:列出每个员工的名字、他所在的部门、该部门的员工数(也包括他自己)与他同样职位的员工数,和EMP表中的员工总数。
select e.ename,
e.deptno,
(select count(*) from emp d
where d.deptno = e.deptno) as deptno_cnt,
job,
(select count(*) from emp d
where d.job = e.job) as job_cnt,
(select count(*) from emp) as total
from emp e

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

