前言
大家可以从MySQL模块的Day0~Day26 进行阅读,大部分要从MySQL流行架构,主从复制、基础语法、高级特性、开发以及运维等不同角度来基础描述MySQL。
但是我却忽悠了最重要的一点,监控和管理MySQL,这一章如果没有什么问题,我还是简单描述一些!
通过百度,谷歌,搜索了大量的监控方案,以及多个DBA的交流,本身运维开发底子薄,让他们去开发白自动,全自动xxx,监控。会有不小的难度,也会造成很多漏洞!业内也有不少DBA,和运维人员吐槽,他们想要一个好的平台。无非是想让公司买个好的监控平台了
来弥补自身的不足!
个人总结:我觉得在当下是个互联网公司,数据都是很宝贵甚至有的时候是致命的!
个人觉的如果没有超过预期成本,不说买个最好的数据库监控工具,也得要买个中上流比较靠谱的监控平台,全方位对自己的数据,和服务器保驾护航!
千万别听信DBA的鬼话,我们有开源平台,自己也可以写脚本,完全节省大笔开支!
真出紧急事故的时候,看你不忙的跟犊子shi的,并且数据没了,顶层领导脑袋都跟着冒冷汗有木有!
最近几年频频爆料某某互联网公司,数据没了,误操作了!如果大型线上业务,虽然你有备份,让你损失一小时的数据,你看你急不急~,直接影响到xxx领导直接到他该去的地方了!
数据丢失跟数据安全都不是一个级别的,你数据泄露的了,你可能屁事没有,你数据没了,赔钱不说!损失用户不说,有可能直接噼辣啪辣一大堆就不说了~
我就是换为思考一下,如果我是互联网公司顶层领导,mb这样人还要么,换掉!
再说了,有实力把脚本写成跟花钱的一样的东东,那样的DBA太贵了!养不起!
一、监控工具选型
监控系统:zabbix(选它的原因是,比Nagios更强的可视化以及绘图能力、照比Nagios配置简单灵活)
命令行工具:Percona Toolkit (日志分析、复制检测、数据同步、索引分析、查询建议、数据归档),这个是MySQL必会的工具,必须得选择会使用它!
Innotop 命令行监控(模拟UNIX中的top工具,非常强大,安装非常容易)
备注说明:不造top,和Nagios 工具是啥的小伙伴,自行百度哈~,这里不讲过多的Unix系统中的东东,偶们主要监控MySQL和影响MySQL的所有相关指标!
基础的监控Python脚本:实时的获取当前QPS 和TPS的值
MONyog 也够不错,只是花钱的~,可以帮你管理集群,报警,远程监控,给出优化建议等。
doDBA tools
来源自:微信公众号(老叶茶馆)老叶茶馆
一个用GOlang 写的脚本,集成了Mytop,sys监控,日志打印等,mysql参数监控,比较不错的一款tools工具!
操作系统及MySQL数据库的实时性能状态数据尤为重要,特别是在有性能抖动的时候,这些实时的性能数据可以快速帮助你定位系统或MySQL数据库的性能瓶颈,就像你在Linux系统上使用「top,sar,iostat」等命令工具一样,可以立刻定位OS的性能瓶颈是在IO还是CPU上,所以收集/展示这些性能数据就更为重要,那都有哪些重要的实时性能状态指标可以反应出系统和MySQL数据库的性能负载呢?

目前在Linux跑MySQL是大多数互联网公司的标配,以上图片的性能数据指标项是我认为在Linux,MySQL,InnoDB中较为重要的实时状态数据,然而在以上图片Doing一栏其实更为重要,之所以把它叫做Doing,是因为「processlist,engine innodb status,locks」等指标项才真正反映了MySQL此时正在做什么。
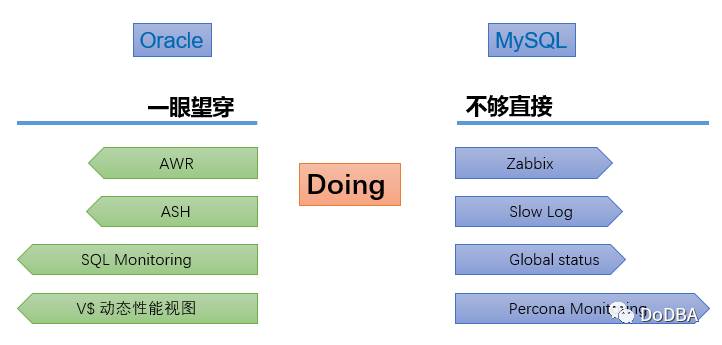
我们来对标Oracle数据库看一下,在Oracle数据库中提供了「AWR,ASH,SQL Monitor」等众多诊断工具,可以一眼望穿数据库正在做什么,甚至都可以知道在过去30天内任何一个时间区间的性能负载和当时数据库正在做什么。
在MySQL中虽然有像「zabbix,PMM」等优秀的监控工具,但它们只能反映数据库历史的一些性能数据曲线,例如,TPS高了,临时表使用多了,有InnoDB Deadlocks,但对于MySQL当时的Doing,我只能说不够直接。如果你在现场,你可以抓到MySQL正在做什么,但是,你总有不在现场的时候,如果问你昨天晚上数据库的性能抖动是什么原因?怎样快速重现现场找到引起抖动的原因呢?
答案是可以使用「doDBA tools」,这是一款免费的基于控制台监控工具。
doDBA tools是什么
doDBA tools是一个基于控制台的远程监控工具,它不需要在本地/远程系统上安装任何软件,它可以实时收集操作系统、MySQL、InnoDB的实时性能状态数据,并可以生成Doing日志文件,来帮助你快速了解/优化系统及MySQL数据库。
特点
-
基于golang语言开发
-
可收集Linux、MySQL相关性能数据
-
可本地或远程收集,可多台
-
mytop --Like Linux TOP
-
基于并发生成Doing日志,复现现场
-
可记录到日志文件
doDBA tools 工作原理
远程收集系统信息是通过ssh(用户名密码或建立信任)的方式连接到远程服务器上收集,收集的方法都是通过读取Linux的proc下的等meminfo,diskstats,uptime,net,vmstat ,cpuinfo ,loadavg等文件,这和pmm,zabbix收集方式一致。
远程收集MySQL信息是通过 MySQL tcp连接到MySQL数据库上收集,只需要授予连接用户PROCESS、SELECT权限即可。
系统信息和MySQL信息的收集可以分离,如果只想收集系统信息,只需要提供系统用户名密码即可,如果只收集MySQL可以只提供MySQL连接信息,如果是rds用户,可以使用-rds参数,在使用mytop时会自动忽略系统信息的收集。
如何使用
Github主页:
https://github.com/dblucyne/dodba_toolsDownload:
wget https://raw.githubusercontent.com/dblucyne/dodba_tools/master/doDBA --no-check-certificate
wget https://raw.githubusercontent.com/dblucyne/dodba_tools/master/doDBA.conf --no-check-certificate chmod +x doDBA
下载下来就可以直接使用,不依赖于任何环境。
使用帮助:
./doDBA -help -cstring configuration file.(default"doDBA.conf") -h string Connectto host/IP. -sys Print linux info. -myall Print linux and mysql info.-mysqlPrint mysql info. -innodb Print innodb info. -mytop Print mysql prcesslist,like top. -iduration refreshintervalin seconds.(1s) -tint doing on Threads_running.(50)-rds Ignore system info.-log Print tofilebyday. -nocolor Print to nocolor.
使用实例
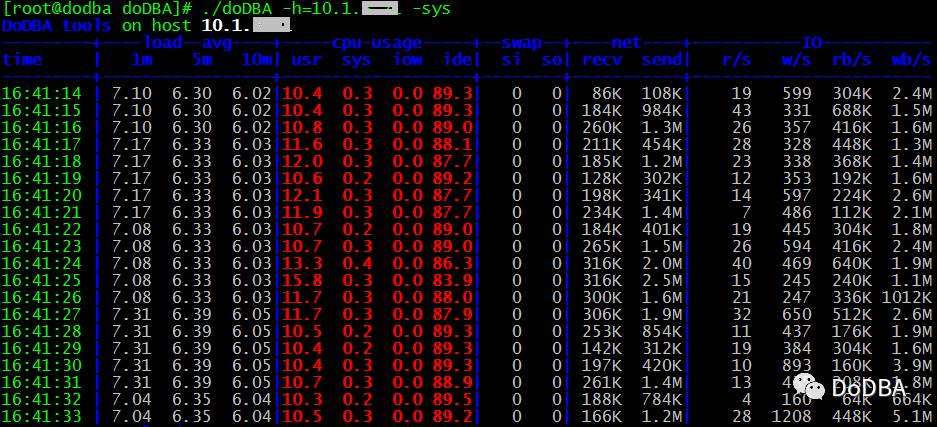
1. 收集Linux性能数据
./doDBA -h=10.1.x.xx -sys
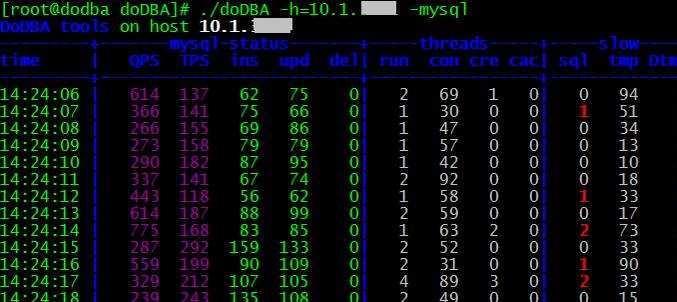
2. 收集MySQL性能数据
./doDBA -h=10.1.x.xx -mysql
3. 收集InnoDB性能数据
./doDBA -h=10.1.x.xx -innodb

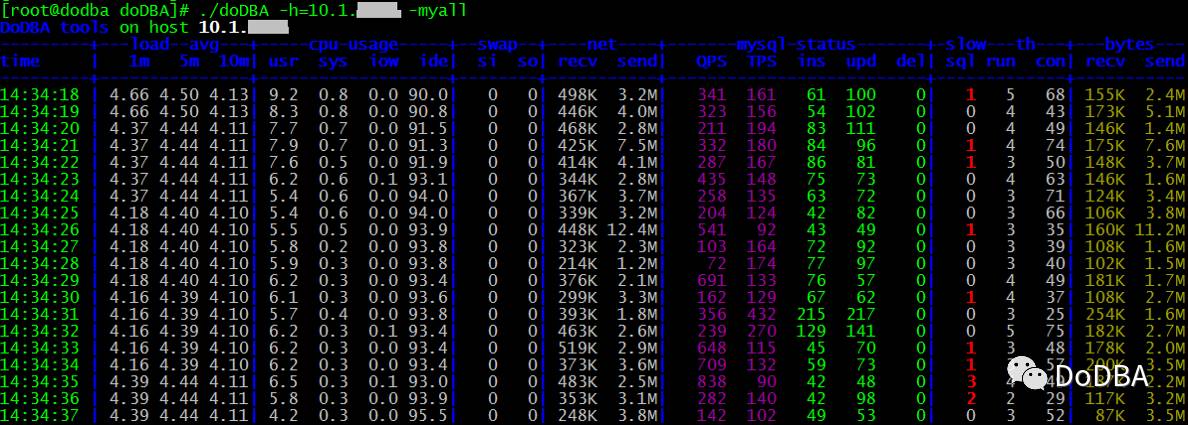
4. 收集MySQL及Linux性能数据
./doDBA -h=10.1.x.xx -myall
5. mytop --like linux top
./doDBA -h=10.1.x.xx -mytop

6. 借助Shell收集多台
cat ip.txt
10.1.x.x110.1.x.x2Shell
cat ip.txt | while read ip; do echo $ip; ./doDBA -h=$ip -mysql -log </dev/null & done7. 收集到日志文件
./doDBA -h=10.1.x.xx -mysql -log
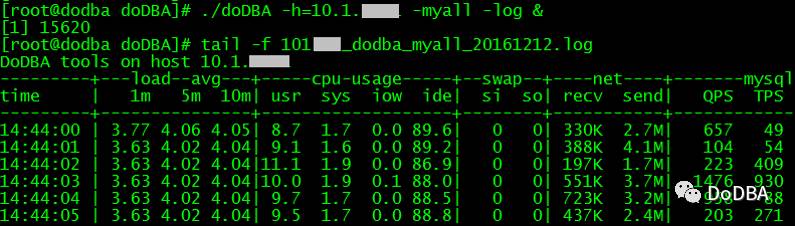
8. 开启Doing功能
使用【-t】参数可以基于Threads_running的数量设置阈值,设置后可记录「processlist,engine innodb status」信息到dodba.log日志中,--复现现场。
./doDBA -h=10.1.x.xx -myall -t=3
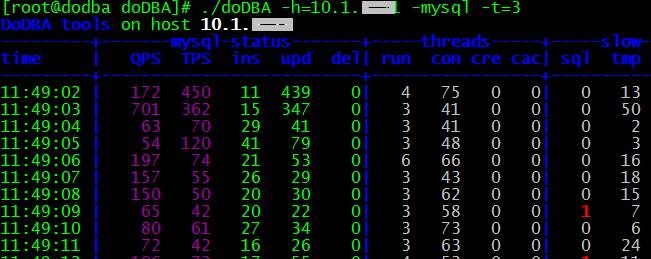
9. 查看Doing日志
tail -f dodba.log
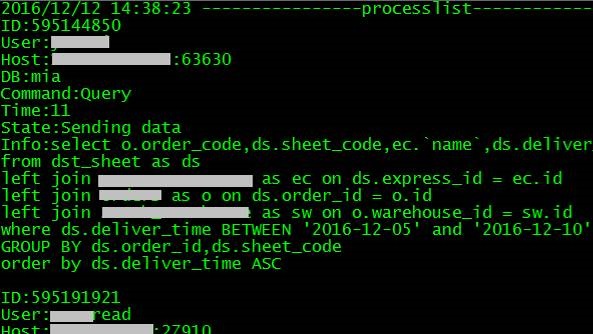
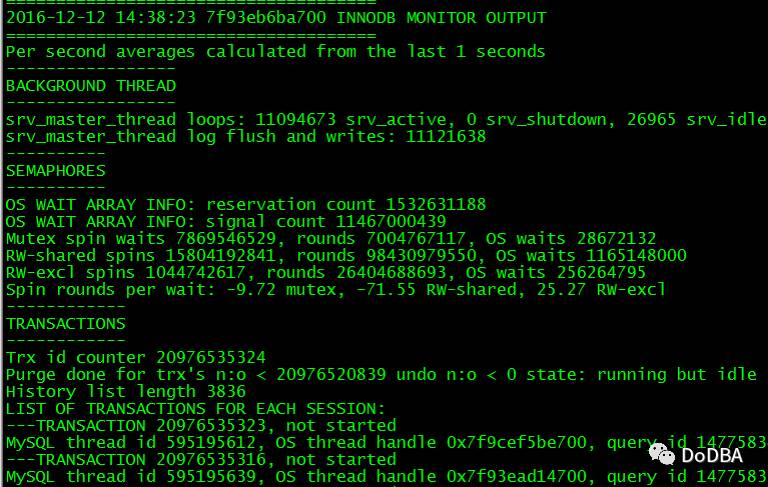
使用zabbix全方位监控MySQL
对MySQL的监控不够详细。本文继续探讨对MySQL的详细监控,包括MySQL实例,MySQL主从复制和MySQL存储引擎等。
本文使用的MySQL版本是5.5
本文使用的模板主要通过FROMDUAL提供的模板更改而成,FROMDUAL官方使用Perl语言编写采集脚本然后通过zabbix trapper的方式推送数据到zabbix server。我觉得FROMDUAL官方提供的配置方式繁琐,并且我对Perl语言又不熟悉,于是阅读官方的Perl脚本后,生出想要重新用Shell语言来实现的想法。模板中的item名称有变更,其他的大体和FROMDUAL官方的模板相同。
1.监控原理
show global status; 查看全局状态
show global variables; 查看全局变量设置
mysqladmin MySQL管理工具
show master status; 查看Master状态
show slave status; 查看Slave状态
show binary logs; 查看二进制日志文件
show engine innodb status\G 查看InnoDB存储引擎状态
show engine myisam status\G 查看MyISAM存储引擎状态
还有通过查看information_schema 这个数据库获取InnoDB存储引擎相关信息
2.添加MySQL监控账号
GRANT USAGE,PROCESS,SUPER,REPLICATION CLIENT,REPLICATION SLAVE ON *.* TO 'zabbixagent'@'localhost' IDENTIFIED BY 'zabbixagent';
flush privileges;
在/usr/local/zabbix/etc/目录下创建一个 .my.cnf 文件
|
1
2
3
4
5
6
|
[mysql]user=zabbixagentpassword=zabbixagent[mysqladmin]user=zabbixagentpassword=zabbixagent |
3.添加zabbix子配置文件mysql_status.conf
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
### MySQL DB InfomationUserParameter=mysql.status[*],echo "show global status where Variable_name='$1';"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|awk '{print $$2}'UserParameter=mysql.variables[*],echo "show global variables where Variable_name='$1';"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|awk '{print $$2}'UserParameter=mysql.ping,mysqladmin --defaults-file=/usr/local/zabbix/etc/.my.cnf ping|grep -c aliveUserParameter=mysql.version,echo "select version();"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N#### MySQL Master InformationUserParameter=mysql.master.Slave_count,echo "show slave hosts;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|wc -lUserParameter=mysql.master.Binlog_file,echo "show master status;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|awk '{print $1}'|awk -F. '{print $1}'UserParameter=mysql.master.Binlog_number,echo "show master status;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|awk '{print $1}'|awk -F. '{print $2}'UserParameter=mysql.master.Binlog_position,echo "show master status;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|awk '{print $2}'UserParameter=mysql.master.Binlog_count,echo "show binary logs;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|wc -lUserParameter=mysql.master.Binlog_total_size,echo "show binary logs;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|awk '{sum+=$NF}END{print sum}'#### MySQL Slave InformationUserParameter=mysql.slave.Seconds_Behind_Master,echo "show slave status\G"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf|grep "Seconds_Behind_Master"|awk '{print $2}'UserParameter=mysql.slave.Slave_IO_Running,echo "show slave status\G"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf|grep "Slave_IO_Running"|awk '{print $2}'UserParameter=mysql.slave.Slave_SQL_Running,echo "show slave status\G"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf|grep "Slave_SQL_Running"|awk '{print $2}'UserParameter=mysql.slave.Relay_Log_Pos,echo "show slave status\G"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf|grep "Relay_Log_Pos"|awk '{print $2}'UserParameter=mysql.slave.Exec_Master_Log_Pos,echo "show slave status\G"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf|grep "Exec_Master_Log_Pos"|awk '{print $2}'UserParameter=mysql.slave.Read_Master_Log_Pos,echo "show slave status\G"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf|grep "Read_Master_Log_Pos"|awk '{print $2}'#### MySQL InnoDB Information#UserParameter=mysql.innodb[*],/usr/local/zabbix/bin/mysql_innodb_status.sh $1####MySQL MyISAM Information# |
InnoDB相关的部分监控项目需要单独用脚本获取
mysql_innodb_status.sh
#!/bin/bash
#Get InnoDB Row Lock Details and InnoDB Transcation Lock Memory
#mysql> SELECT SUM(trx_rows_locked) AS rows_locked, SUM(trx_rows_modified) AS rows_modified, SUM(trx_lock_memory_bytes) AS lock_memory FROM information_schema.INNODB_TRX;
#+-------------+---------------+-------------+
#| rows_locked | rows_modified | lock_memory |
#+-------------+---------------+-------------+
#| NULL | NULL | NULL |
#+-------------+---------------+-------------+
#1 row in set (0.00 sec)
#+-------------+---------------+-------------+
#| rows_locked | rows_modified | lock_memory |
#+-------------+---------------+-------------+
#| 0 | 0 | 376 |
#+-------------+---------------+-------------+
#Get InnoDB Compression Time
#mysql> SELECT SUM(compress_time) AS compress_time, SUM(uncompress_time) AS uncompress_time FROM information_schema.INNODB_CMP;
#+---------------+-----------------+
#| compress_time | uncompress_time |
#+---------------+-----------------+
#| 0 | 0 |
#+---------------+-----------------+
#1 row in set (0.00 sec)
#Get InnoDB Transaction states
#TRX_STATE Transaction execution state. One of RUNNING, LOCK WAIT, ROLLING BACK or COMMITTING.
#mysql> SELECT LOWER(REPLACE(trx_state, " ", "_")) AS state, count(*) AS cnt from information_schema.INNODB_TRX GROUP BY state;
#+---------+-----+
#| state | cnt |
#+---------+-----+
#| running | 1 |
#+---------+-----+
#1 row in set (0.00 sec)
innodb_metric=$1
case $innodb_metric in
Innodb_rows_locked)
value=$(echo "SELECT SUM(trx_rows_locked) AS rows_locked, SUM(trx_rows_modified) AS rows_modified, SUM(trx_lock_memory_bytes) AS lock_memory FROM information_schema.INNODB_TRX;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N| awk '{print $1}')
if [ "$value" == "NULL" ];then
echo 0
else
echo $value
fi
;;
Innodb_rows_modified)
value=$(echo "SELECT SUM(trx_rows_locked) AS rows_locked, SUM(trx_rows_modified) AS rows_modified, SUM(trx_lock_memory_bytes) AS lock_memory FROM information_schema.INNODB_TRX;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N| awk '{print $2}')
if [ "$value" == "NULL" ];then
echo 0
else
echo $value
fi
;;
Innodb_trx_lock_memory)
value=$(echo "SELECT SUM(trx_rows_locked) AS rows_locked, SUM(trx_rows_modified) AS rows_modified, SUM(trx_lock_memory_bytes) AS lock_memory FROM information_schema.INNODB_TRX;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N| awk '{print $3}')
if [ "$value" == "NULL" ];then
echo 0
else
echo $value
fi
;;
Innodb_compress_time)
value=$(echo "SELECT SUM(compress_time) AS compress_time, SUM(uncompress_time) AS uncompress_time FROM information_schema.INNODB_CMP;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|awk '{print $1}')
echo $value
;;
Innodb_uncompress_time)
value=$(echo "SELECT SUM(compress_time) AS compress_time, SUM(uncompress_time) AS uncompress_time FROM information_schema.INNODB_CMP;"|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|awk '{print $2}')
echo $value
;;
Innodb_trx_running)
value=$(echo 'SELECT LOWER(REPLACE(trx_state, " ", "_")) AS state, count(*) AS cnt from information_schema.INNODB_TRX GROUP BY state;'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep running|awk '{print $2}')
if [ "$value" == "" ];then
echo 0
else
echo $value
fi
;;
Innodb_trx_lock_wait)
value=$(echo 'SELECT LOWER(REPLACE(trx_state, " ", "_")) AS state, count(*) AS cnt from information_schema.INNODB_TRX GROUP BY state;'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep lock_wait|awk '{print $2}')
if [ "$value" == "" ];then
echo 0
else
echo $value
fi
;;
Innodb_trx_rolling_back)
value=$(echo 'SELECT LOWER(REPLACE(trx_state, " ", "_")) AS state, count(*) AS cnt from information_schema.INNODB_TRX GROUP BY state;'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep rolling_back|awk '{print $2}')
if [ "$value" == "" ];then
echo 0
else
echo $value
fi
;;
Innodb_trx_committing)
value=$(echo 'SELECT LOWER(REPLACE(trx_state, " ", "_")) AS state, count(*) AS cnt from information_schema.INNODB_TRX GROUP BY state;'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep committing|awk '{print $2}')
if [ "$value" == "" ];then
echo 0
else
echo $value
fi
;;
Innodb_trx_history_list_length)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "History list length"|awk '{print $4}'
;;
Innodb_last_checkpoint_at)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "Last checkpoint at"|awk '{print $4}'
;;
Innodb_log_sequence_number)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "Log sequence number"|awk '{print $4}'
;;
Innodb_log_flushed_up_to)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "Log flushed up to"|awk '{print $5}'
;;
Innodb_open_read_views_inside_innodb)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "read views open inside InnoDB"|awk '{print $1}'
;;
Innodb_queries_inside_innodb)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "queries inside InnoDB"|awk '{print $1}'
;;
Innodb_queries_in_queue)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "queries in queue"|awk '{print $5}'
;;
Innodb_hash_seaches)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "hash searches"|awk '{print $1}'
;;
Innodb_non_hash_searches)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "non-hash searches/s"|awk '{print $4}'
;;
Innodb_node_heap_buffers)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "node heap"|awk '{print $8}'
;;
Innodb_mutex_os_waits)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "Mutex spin waits"|awk '{print $9}'
;;
Innodb_mutex_spin_rounds)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "Mutex spin waits"|awk '{print $6}'|tr -d ','
;;
Innodb_mutex_spin_waits)
echo 'show engine innodb status\G'|mysql --defaults-file=/usr/local/zabbix/etc/.my.cnf -N|grep "Mutex spin waits"|awk '{print $4}'|tr -d ','
;;
*)
echo "wrong parameter"
;;
esac
4.添加监控模板
附件中包含对MySQL实例,MySQL Master,MySQL Slave和MySQL InnoDB的监控

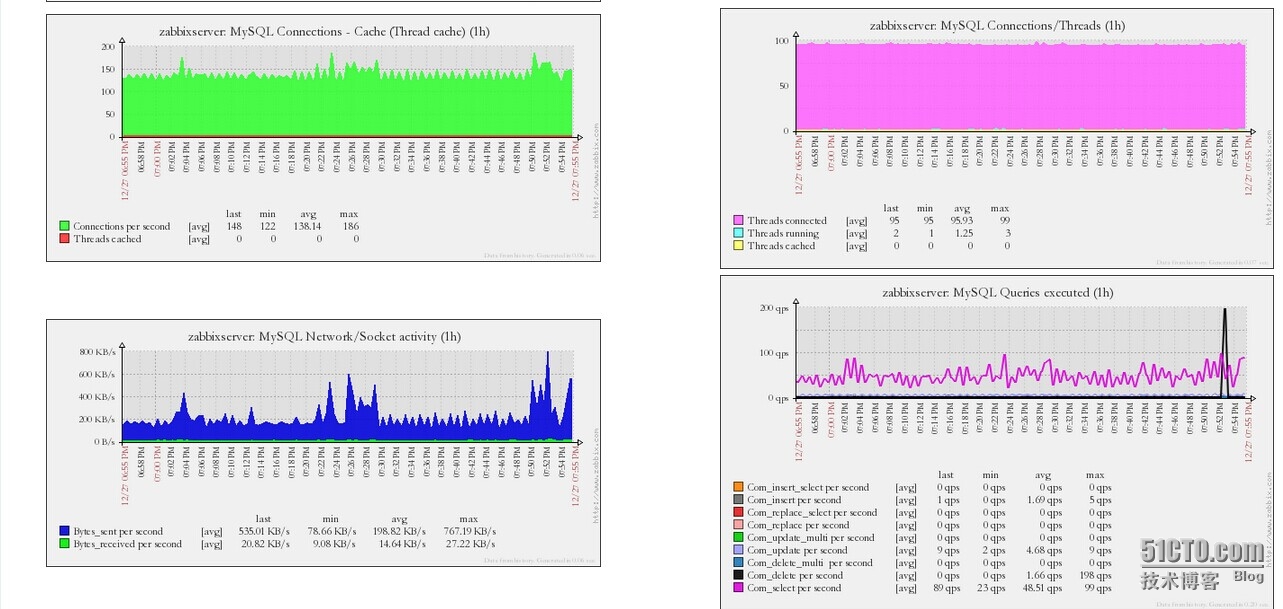
参考文章:
http://www.percona.com/doc/percona-monitoring-plugins/1.0/cacti/mysql-templates.html
http://hi.baidu.com/ytjwt/item/2bbd69a0869d1ef314329b6a
http://www.fromdual.com/mpm-installation-guide
http://www.fromdual.com/mysql-performance-monitor
http://dev.mysql.com/doc/refman/5.5/en/information-schema.html
FROMDUAL官方模板和脚本下载地址如下,感兴趣的可以看看
二、zabbix 使用percona mysql插件来监控mysql
略:自己实验即可,关键点在于配置文件中脚本的配置,其他都好说~
三、innotop使用简介
http://www.mamicode.com/info-detail-1749796.html
安装:
yum install -y innotop
使用帮助:
[root@master local]# innotop --help
Usage: innotop <options> <innodb-status-file>
--askpass Prompt for a password when connecting to MySQL
--[no]color -C Use terminal coloring (default)
--config -c Config file to read
--count Number of updates before exiting
--delay -d Delay between updates in seconds
--help Show this help message
--host -h Connect to host
--[no]inc -i Measure incremental differences
--mode -m Operating mode to start in
--nonint -n Non-interactive, output tab-separated fields
--password -p Password to use for connection
--port -P Port number to use for connection
--skipcentral -s Skip reading the central configuration file
--socket -S MySQL socket to use for connection
--spark Length of status sparkline (default 10)
--timestamp -t Print timestamp in -n mode (1: per iter; 2: per line)
--user -u User for login if not current user
--version Output version information and exit
--write -w Write running configuration into home directory if no config files were loaded
innotop is a MySQL and InnoDB transaction/status monitor, like 'top' for
MySQL. It displays queries, InnoDB transactions, lock waits, deadlocks,
foreign key errors, open tables, replication status, buffer information,
row operations, logs, I/O operations, load graph, and more. You can
monitor many servers at once with innotop.
四、一篇赶集网3年DBA的经历文
2012年初入职赶集,当时处在流量讯猛增长的阶段,3年DBA生涯收获坡多,其实坑更多(泪... 后来在做开发时,慢慢体会到 ”运维“ 和 “开发” 确实存在沟通问题:知识不对称。如何解决呢?先总结下这三年吧
DBA职责
市面上招聘 JD 一大堆,随变找几个,马上能找出共性
- 数据库系统的规划、设计、管理、迁移
- 数据库的日常维护、备份、优化及恢复
- Master-Slave架构搭建、维护
- 业务系统上线支持,数据库设计评审,提供架构方案
数据库不局限于 MySQL, Oracle, 如果分的不细,还会有 Redis, MongoDB 等一系列 NoSQL。工作内容都一样,首先是高可用稳定性,不能今天抖动明天宕机,涉及工作很多。第二个是数据安全,比如备份及恢复,14年赶集审计,移动端的活跃用户数就是从备份中恢复来的,可见备份的有效性是重中之重。最后一个当然是为业务服务,对接业务需求,不能因个人生活被打断就罢工,有一次刚看电影就被叫回去处理DB报警,骂娘的心都有了。
悲惨案例
先举一些悲惨案例,让看官们高兴一下~ 由于公司早就不在了,这里没有顾忌。
1. delete 删全表
二手车同学的锅,SQL 拼错不带 where 条件,编写线下脚本时出错... 最后DBA根据 row binlog 恢复。至少2次:(
反思:rd 新手一茬又一茬,规范讲再多也没用。最彻底的解决方式只有一个,接入 proxy, 限制一切非法 sql。另外 rd 上线验证也不到位,代码 review 肯定有缺失
2. 大卖家问题
房产在14年开通免费端口,短短几个月时间房产商业表爆涨到 100G,个别中介帐号发贴超过10W,导致数据库异常抖动,威哥临时清理过多发贴记录解决。最后耗时三个月对这张表进行瘦身,拆分 text 字段。
反思:DBA 对大表监控不足
3. 大量子查询打跨主库
主站主库有一次被子查询打跨,事后排查,由于 RD 大量子查询导致。此类问题不是个案,有很多 RD 把本本该读 slave 的请求写到 master 上,只不过没有引起事故而已
反思:赶集 DB 典型 1 主 N 从,没有 proxy 保护的怀况下,经常出现此类问题,只靠规范制度基本解决不了
4. 报表 olap 库问题
RP 库我和文武背锅,年底的绩效垫底。文武接手前的 RD 一个人开发中介商家报表系统,所有计算都是基于 DB,当免费端口开放后数据量爆涨,MyISAM 读写锁导致大量请求阻塞,听说公司因为报表连续问题赔商家300W。
反思:这个事故得站在高处去看,免费端口开放太突然,项目技术负责人考滤不全。报表系统没有经过设计,完全由一个新人RD去搞,也就大学毕设水平,回头再看,hadoop spark 完全搞定。最后 DBA 没有及时对大表进行跟踪,没有提前发现。
5. 50G的Redis
房产业务 Redis 眼看从 20G 爆涨到 50G,我离开后也一直没优化掉。后来某次故障,数据清空了?
我的工作
大部份时间和开发沟通感情聊人生,后来 automan 上线很少有人找我了~ 每个阶段都有成长,都有感谢的人和事,赶集让我有平台去做感兴趣的事,很开心。
刚到赶集时,SQL 上线还走的 jira,半自动化由运维开发同学做的,经常在技术大群里被艾特,很简单的建表或是DML 都要由 DBA 人工介入,很烦索。另外很多建表语句不规范,打回让 RD 修改,他们对此很有意见,认为无所谓的修改,这就在 RD和 DBA之间产生了沟通成本,诗展在的时候还会定期做数据库开发培训,然后就没有然后了。
14年中着手 automan 平台开发,从前台页面到后端消息队列,到 sql parser 解析,从无到有,在刘军先河同学的帮助下最终上线完成。由平台去审核开发的 SQL,经过 sim 模拟环境,再到线上自动执行备份,比人工高效的多。
这个系统原理和市面上其它工具差不多,扔有很大改进的地方。后来在数据库大会分享了一次,诚惶诚恐没有被喷。
DBA 心得
-
夯实基础:DB 的基础自然是稳定,稳定,再稳定。实例数一多,基本每天都会遇到各种故障。主挂了就用 MHA 切换(最新的有gtid),slave 挂掉就由 lvs 自动摘掉读流量。还有一个就是备份,全量增量,定期备份有效性检测,每一块都需要人力的投入。
-
硬件优先:DB扩容有 scale up 和 scale out 两种,一般优先堆硬件。buffer 不够加内存,128G 不够就 192G,磁盘阵列卡性能不行就上 SSD,再不行就上 flash 板卡。总之优先考滤硬件,争取架构优化的时间。
-
未雨绸缪:慢 SQL 优化,定期出报表让 RD 调优,一般出问题都是索引没加,99%的大SQL都是这样,少部份因为表设计不合理(没有自增主键,或是频烦修改)。大表监控,该瘦身的瘦身,字段该拆的拆,横竖两刀,过期数据定期归档,基本上就这些事。
-
结合业务:有些优化 DBA 累的半死,不如 RD 修改一行代码。DBA 也要多和业务接触,了解业务实现,不求给业务贡献多少,不背锅就好... 开玩笑。了解业务,就能站在更高的角度去思考,很有意义。
-
学会拒绝:这个拒绝不是罢工不干活,而是要分清哪些需求的合理性与紧急性,不合理也不紧急的直接干掉,紧急但不合理的可以临时通过,快速解决问题,事后再确掉也可以。比如 olap 跑在了线上库,count(*) 计数 SQL 完全可以异步走计数器,Redis 是好东西。
-
学会沟通:工作也有些年头了,这一点仍然在学习,也犯过不少错。沟通好权责,定下时间表。
-
踏实学习:回头看当年DBA做的不够好,有些原因在于没有开发能力,很多想法止步于此。运维人员一定要有开发功力,并且要比业务 RD 更精,才能做好运维。
运维RD的矛与盾
KPI 不同,关注点自然也不同,一线的同学经验也都有欠缺,特别是刚工作1~2年的,造成了信息与知识的不对称。解决这个问题也不难:
- 新人要有导师带,对新人放手不管最不负责。这方面感觉 nice 做的不错。该夸还是要夸的。
- 支撑团队要有足够的 wiki 业务文档说明。
- 自动化用技术来约束,而不是人工。同比业务接口强约束,现在服务化都用 thrift 了。
对赶集的记忆已经越来越模糊了,唯有...
总结写了一部份后,原同事都说遗漏了一些,那就一齐追加到后面,版权不归我:)
20170214 下面内容来自原同事: 李瑞
回忆下赶集的dba生活
总结下就是各种故障多,随时候命,需要处理,这些直到automan出来,强制rd通过平台上线后,稍微好点。
-
因为raid0的问题,至少遇到4-5次master硬盘的问题,需要紧急处理。
tg 遇到1次,ms 切过次,貌似也是磁盘的问题。
其他slave 备份机,硬盘出故障更是多,最多一周需要处理4起磁盘的问题。而赶集的mysqldb 普遍都大至少100G,数据报表库的磁盘有2.3T,没法通过备份的方式重架从库,我用了2-3周才搞定 -
im 的swap 问题
Im 的swap问题,肯定是sql的问题,主要的查询sql 是通过order by,count 来获取数据,这个问题,从我进去赶集到出来一直是无法解决。只能是手动lvs切流量,重启slave,再lvs回切流量 解决swap的问题。1周几乎需要1-2次。告诉过im同事几次im sql问题,希望对count查询可以自己做个计数器,不过最后也没下文了。关闭swap 又怕服务器会经常oom。 最后还是赵慎举同学来了后,开启了预热innodb_buffer_pool的参数后,可以直接重启slave,而不怕因为预热的问题load突增。其他赵慎举同学改了numa限制内存,不过im的swap是最后也没解决。 -
备份
备份的问题,1是磁盘空间的问题,1个还是raid0的问题。。
最后你们走后,有1个月我独立支撑,直到毕常奇来了,6台,还是7台备份机,硬盘坏的是此起彼伏。 Log库,emp,还有王绪峰组,我忘记了业务线的名称了,暴涨到800G的数据,备份机坏了,再加上空间不足。我索性停了备份,最后只保证了ms,hp,tg,tc一些大库的备份,这个58同事接手后估计会被他们鄙视坏了。
这个其实后来华为32T的备份机来了以后,备份机制应该变通的,怪我
还有异机备份,每2个月 4个2T盘就会保存满了,更换,挪盘,手动做raid挂盘,手动excle做记录。最后还真有次要用到这些盘查找数据。 -
磁盘问题
Hp 俩个大表,需要定期清理数据。Ms 磁盘每天10G的增长速度,而且ms需要用pcie卡,最后终于可以从800 扩到1200。可以消停几个月。Ms 有几个台机器,最后就差10G 左右就要满了。各种删日志,各种挪数据,东墙补西墙,(搞的我知道400G 的ssd 做xfs 要比ext4 能省20G 的空间,刚刚好够给ms用),而且磁盘的增长,伴随着备份机,磁盘空间不足,sim机(提供只读服务给开发的我忘记叫什么了)空间不足。还有report库,想申请磁盘,服务器,机柜没有位置了,就那样挺着单库跑了很久。 -
还有就是王绪峰组 和tc 的 通过框架生成的sql
生成多余的子表,varchar 类型的字段条件不加单引,再加上上线建表不加索引,定期需要检查sql,进行优化。 -
痛苦的hp,主库拆分。
历时1年多,没有分拆完整 。最后听毕常奇说,瓜子二手车从这些库里拆分。自上而下,强行拆分。1-2天拆分了。
-
php的短连接,连接数满
这个最后的最后,你们走了后,偶尔在分析hp全日志,发现hp每1-2次连接,伴随着一次空连接。Connect 什么都不做 quit。这个问题不知道什么有的,改了后,hp的连接数问题好了。
总结,在赶集,因为数据的暴涨,只是一味的应对,没有快刀斩乱麻,进行分拆。还有就是有个dba的平台真是很必要,管理监控,提交审核sql,这个直到后来在完美一天的时候我才能够模仿着automan勉强写了个

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

