MySQL HA方案之MySQL半复制+MHA+Keepalived+Atlas+LVS(上)
2016-11-24赵俊峰ACMUG
ACMUG征集原创技术文章。详情请点击上面ACMUG或者扫描文末二维码关注我们的微信公众号。
作者:赵俊峰
作者简介:小米研发,个人博客:hugnew.com。
个人博客的自我介绍:
        一个码农,一个文字的搬运工,一个骑行爱好者,一个伪摄影师,一个伪吉他手,一个资深养狗师。乔布斯的信徒,恪守乔布斯的名言:“Stay Hungry, Stay Foolish.
简介
目前Mysql高可用的方案有好多,比如MMM,heartbeat+drbd,Cluster等,还有percona的Galera Cluster等。这些高可用软件各有优劣。在进行高可用方案选择时,主要是看业务还有对数据一致性方面的要求。本文探讨的是MHA这种方案。
至于DAL层,也有很多方案,现在主流的一是在应用层写数据库路由,当然这个效率也是最快的,但是最大的缺陷就是运维难度大,技术难度也大,需要有强大的技术团队支持。第二个方案是proxy中间件,现在开源的中间件很多,比如TDDL、Cobar、Atlas、MyCat、Mysql Proxy、Oceanus等等,中间件的最大的好处是对数据层解耦,减轻了运维难度,当然在服务器层与数据库层加了一层proxy,使得效率明显不如直接访问数据库。按业务实际需求选择合适的方案,在本篇文章中,选的是360开源的DAL中间件Atlas,详细信息官方文档(https://github.com/Qihoo360/Atlas)以描述的很清楚,这里不做过多的描述。
现在继续讨论MHA,MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
我们自己使用其实也可以使用1主1从,但是master主机宕机后无法切换,以及无法补全binlog。master的mysqld进程crash后,还是可以切换成功,以及补全binlog的。
架构图
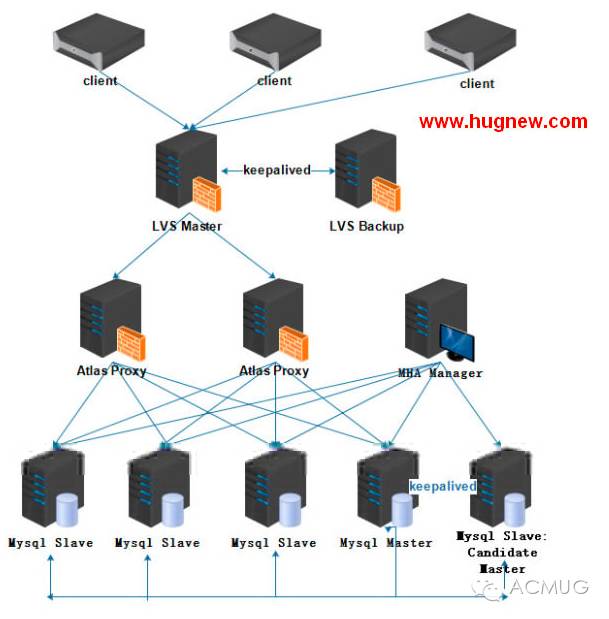
现在说下架构图的层级关系,最底层的是mysql主从,其中有从机作为备选的主机,备选主机与主机之间由keepalived维护着心跳。每个mysql server都是MHA node,由MHA Manager监控着Mysql的节点,当MHA Manager监控(keepalived的心跳检测)到主机出现问题,会切换到备选主机,并将备选主机提升为新主机,其他的从机成为新主机的从机,并且VIP也漂移到新主机,这样就实现了Mysql的HA。db上面的一层是Atlas Proxy,Atlas主要的功能是读写分离、从库的负载均衡、自动分表、自动摘除宕机的DB、DBA可平滑的上下线DB及IP过滤,其中读写分离及自动摘除宕机的DB是当初选择该中间件的最主要原因,自动摘除宕机的从机保障了整个架构系统持续性,而不影响业务的正常运行。后期根据数据量的增大可以切换到Mycat这个方案,支持分库分表、主从切换等等,并且社区活跃度也很高,感兴趣的可以查看下官方文档(https://github.com/MyCATApache)。回到正题,这里有两个Atlas做HA,上层的LVS做Atlas的负载均衡,两个LVS之间利用keepalived心跳实现热主备模式,防止出现单点故障。再上层的就是应用server,这里就不在讨论了。

MHA
1.MHA的基本原理
(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新的master;
(6)使其他的slave连接新的master进行复制;
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下。
Manager工具包主要包括以下几个工具:

Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:

注意:为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置MHA的同时建议配置成MySQL 5.5的半同步复制,关于半同步复制原理及安装流程下面会详细介绍。
2.部署MHA
接下来部署MHA,具体的搭建环境如下:
其中master对外提供写服务,slave提供相关的读服务,一旦master宕机,将会把备选master提升为新的master,slave指向新的master。
(1)在所有节点安装MHA node所需的perl模块(DBD:mysql),安装脚本如下:
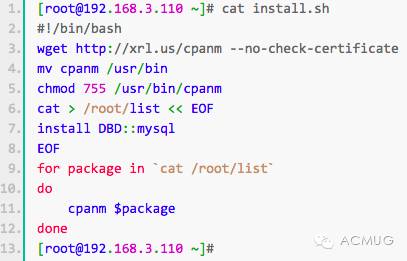
如果有安装epel源,也可以使用yum安装

(2)在所有的节点安装mha node:

安装完成后会在/usr/local/bin目录下生成以下脚本文件:

关于上面脚本的功能,上面已经介绍过了,这里不再重复了。
3.安装MHA Manager
MHA Manager中主要包括了几个管理员的命令行工具,例如master_manger,master_master_switch等。MHA Manger也依赖于perl模块,具体如下:
(1)安装MHA Node软件包之前需要安装依赖。我这里使用yum完成,没有epel源的可以使用上面提到的脚本(epel源安装也简单)。注意:在MHA Manager的主机也是需要安装MHA Node。

安装MHA Node软件包,和上面的方法一样,如下:
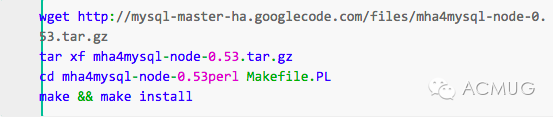
(2)安装MHA Manager。首先安装MHA Manger依赖的perl模块(我这里使用yum安装):

安装MHA Manager软件包:
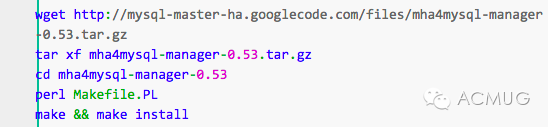
安装完成后会在/usr/local/bin目录下面生成以下脚本文件,前面已经说过这些脚本的作用,这里不再重复。

复制相关脚本到/usr/local/bin目录

4.配置SSH免密码登录(key模式)
这里需要注意的是所有的mysql server节点两两之间必须配成SSH无密码免登录双向模式,否则后面会报错。SSH免密码登录配置的文档可以查看Linux(使用ssh-keygen)设置SSH免密码登录。
5.搭建主从复制环境
搭建MySQL主从复制的文档可以查看linux(Ubuntu)下mysql安装及主从复制,MySQL半复制的文档可以查看Mysql半复制浅谈,这里不再赘述。
6.配置MHA
(1)创建MHA的工作目录,并且创建相关配置文件(在软件包解压后的目录里面有样例配置文件)。

修改app1.cnf配置文件,修改后的文件内容如下(注意,配置文件中的注释需要去掉,我这里是为了解释清楚):


(2)设置relay log的清除方式(在每个slave节点上):

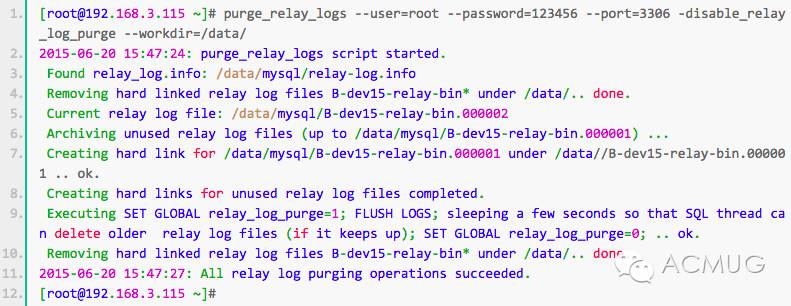
MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF,采用手动清除relay log的方式。在默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。但是在MHA环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能。定期清除中继日志需要考虑到复制延时的问题。在ext3的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在linux系统中通过硬链接删除大文件速度会很快。(在mysql数据库中,删除大表时,通常也采用建立硬链接的方式)
MHA节点中包含了pure_relay_logs命令工具,它可以为中继日志创建硬链接,执行SET GLOBAL relay_log_purge=1,等待几秒钟以便SQL线程切换到新的中继日志,再执行SET GLOBAL relay_log_purge=0。
pure_relay_logs脚本参数如下所示:

(3)设置定期清理relay脚本(三台slave服务器)
添加到crontab定期执行

purge_relay_logs脚本删除中继日志不会阻塞SQL线程。下面我们手动执行看看什么情况。
7.检查SSH配置
检查MHA Manger到所有MHA Node的SSH连接状态:


可以看见各个节点ssh验证都是ok的。
8.检查整个复制环境状况
通过masterha_check_repl脚本查看整个集群的状态




9.检查MHA Manager的状态
通过master_check_status脚本查看Manager的状态:

注意:如果正常,会显示”PING_OK”,否则会显示”NOT_RUNNING”,这代表MHA监控没有开启。
10.开启MHA Manager监控
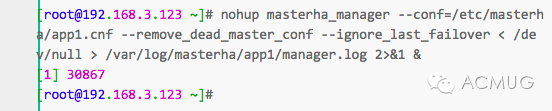
启动参数介绍:
–remove_dead_master_conf      该参数代表当发生主从切换后,老的主库的ip将会从配置文件中移除。
–manger_log                            日志存放位置
–ignore_last_failover                 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录,也就是上面我设置的/data产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为–ignore_last_failover。
查看MHA Manager监控是否正常:

可以看见已经在监控了,而且master的主机为192.168.3.110
11.查看启动日志

其中”Ping(SELECT) succeeded, waiting until MySQL doesn’t respond..”说明整个系统已经开始监控了。
12.关闭MHA Manage监控
关闭很简单,使用masterha_stop命令完成。
13.配置VIP
vip配置可以采用两种方式,一种通过keepalived的方式管理虚拟ip的漂移;另外一种通过脚本方式启动虚拟ip的方式(即不需要keepalived或者heartbeat类似的软件)。这里采用的是keepalived的方式管理vip的漂移。
keepalived方式管理虚拟ip,keepalived配置方法如下:
(1)下载软件进行并进行安装(两台master,准确的说一台是master,另外一台是备选master,在没有切换以前是slave):
(2)配置keepalived的配置文件,在master上配置(192.168.3.110)

其中router_id MySQL HA表示设定keepalived组的名称,将192.168.3.250这个虚拟ip绑定到该主机的eth0网卡上,并且设置了状态为backup模式,将keepalived的模式设置为非抢占模式(nopreempt),priority 80表示设置的优先级为80。下面的配置略有不同,但是都是一个意思。
(3)在候选master上配置(192.168.3.118)

(4)启动keepalived服务,在master上启动并查看日志
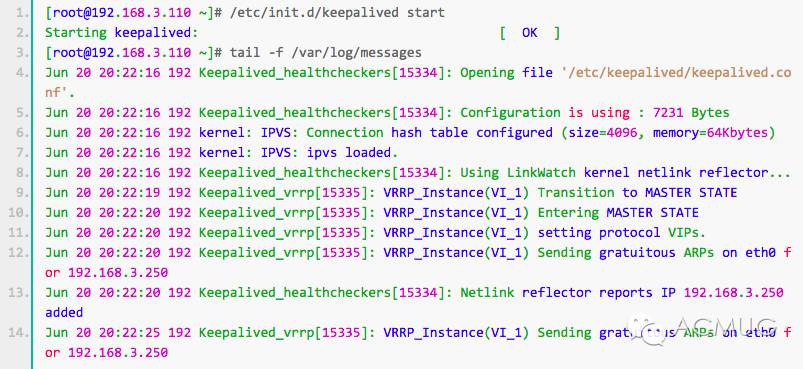
发现已经将虚拟ip 192.168.3.250绑定了网卡eth0上。
(5)查看绑定情况
 在另外一台服务器,候选master上启动keepalived服务,并观察
在另外一台服务器,候选master上启动keepalived服务,并观察

从上面的信息可以看到keepalived已经配置成功。
注意:
上面两台服务器的keepalived都设置为了BACKUP模式,在keepalived中2种模式,分别是master->backup模式和backup->backup模式。这两种模式有很大区别。在master->backup模式下,一旦主库宕机,虚拟ip会自动漂移到从库,当主库修复后,keepalived启动后,还会把虚拟ip抢占过来,即使设置了非抢占模式(nopreempt)抢占ip的动作也会发生。在backup->backup模式下,当主库宕机后虚拟ip会自动漂移到从库上,当原主库恢复和keepalived服务启动后,并不会抢占新主的虚拟ip,即使是优先级高于从库的优先级别,也不会发生抢占。为了减少ip漂移次数,通常是把修复好的主库当做新的备库。
(6)MHA引入keepalived
要想把keepalived服务引入MHA,我们只需要修改切换是触发的脚本文件master_ip_failover即可,在该脚本中添加在master发生宕机时对keepalived的处理。
编辑脚本/usr/local/bin/master_ip_failover,修改后如下,这里完整贴出该脚本(192.168.3.123)。
在MHA Manager修改脚本修改后的内容如下:


现在已经修改这个脚本了,我们现在打开在上面提到过的参数,再检查集群状态,看是否会报错。

 中间内容略去。
中间内容略去。
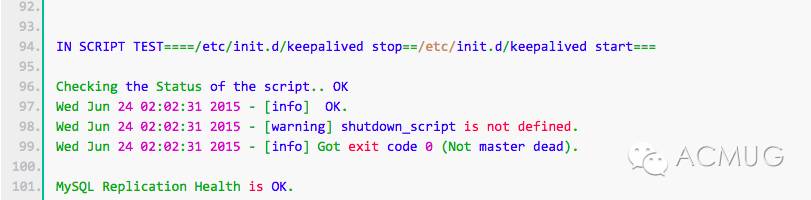
可以看见没有报错。 /usr/local/bin/master_ip_failover添加或者修改的内容意思是当主库数据库发生故障时,会触发MHA切换,MHA Manager会停掉主库上的keepalived服务,触发虚拟ip漂移到备选从库,从而完成切换。当然可以在keepalived里面引入脚本,这个脚本监控mysql是否正常运行,如果不正常,则调用该脚本杀掉keepalived进程。
keepalived的vip漂移原理及配置项说明可以查看文档小谈keepalived vip漂移原理与VRRP协议。
14.MHA测试
到此为止,基本MHA集群已经配置完毕。接下来就是实际的测试环节了。通过一些测试来看一下MHA到底是如何进行工作的。下面将从MHA自动failover、手动failover两种方式来介绍MHA的工作情况。
14.1. 自动Failover(必须先启动MHA Manager,否则无法自动切换,当然手动切换不需要开启MHA Manager监控)
自动failover模拟测试的操作步骤如下:
(1)使用sysbench生成测试数据(使用yum快速安装),sysbench的使用说明可以查看文档sysbench使用详解

在主库(192.168.3.110)上进行sysbench数据生成,在sbtest库下生成sbtest表,共100W记录。

(2)停掉slave sql线程,模拟主从延时(192.168.3.118)

另外两台slave我们没有停止io线程,所以还在继续接收日志。
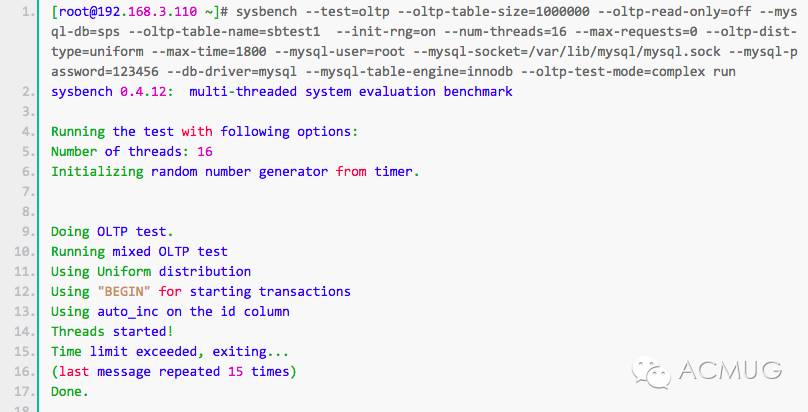
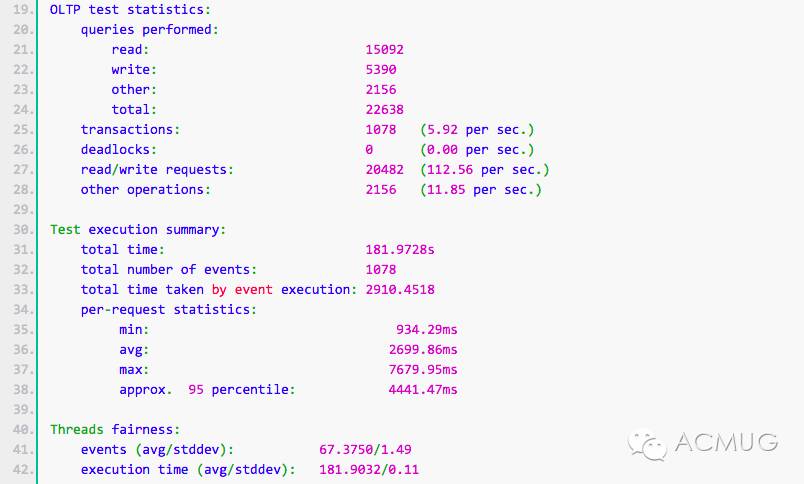
(3)模拟sysbench压力测试
在主库上(192.168.3.110)进行压力测试,持续时间为3分钟,产生大量的binlog。
 (4)开启slave(192.168.3.118)上的IO线程,追赶落后于master的binlog。
(4)开启slave(192.168.3.118)上的IO线程,追赶落后于master的binlog。
 (5)杀掉主库mysql进程,模拟主库发生故障,进行自动failover操作。
(5)杀掉主库mysql进程,模拟主库发生故障,进行自动failover操作。
 (6)查看MHA切换日志,了解整个切换过程,在192.168.3.123上查看日志(注意:由于测试多次切换过程,下面摘录的是192.168.3.118为主机,192.168.3.110为候选主机的切换log):
(6)查看MHA切换日志,了解整个切换过程,在192.168.3.123上查看日志(注意:由于测试多次切换过程,下面摘录的是192.168.3.118为主机,192.168.3.110为候选主机的切换log):

略去中间log。
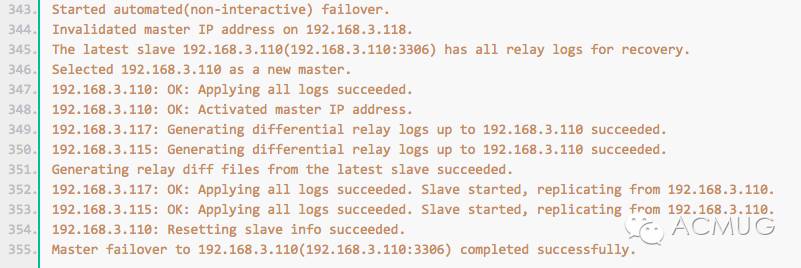
看到最后的Master failover to 192.168.3.110(192.168.3.110:3306) completed successfully.说明备选master现在已经上位了。
从上面的输出可以看出整个MHA的切换过程,共包括以下的步骤:
-
连接主机三次失败确认主机宕机,摘除宕机的vip
-
检查从库中使用的最新binlog file/pos
-
检查从库中使用的最老binlog file/pos
-
获取宕掉主机的binlog:根据步骤1获取的binlog位置开始保存未同步到从机的binlog(导出binlog描述事件,导出影响的binlog数据);将导出的binlog发送到mha-manage服务器指定目录下
-
healthcheck:监控ssh到其他的机器是否正常
-
检查最新binlog file/pos的从机是否有需要恢复其他从机所需的所有relay log
-
如果其他从机跟最新从机pos不一致,需要最新从机的relay log进行一致性恢复
-
检查是否设置候选主机
-
开始候选主机切换:先检查候选主机是否有所有的relay log,没有首先从最新从机恢复,然后将mha收到宕机主机缺省的binlog发送给候选主机,识别差异的relay log并将差异的事件应用所有的relay log,执行vip漂移到候选主机,候选主机恢复结束
-
其他从机relay log恢复:先检查从机是否有所有的relay log,没有首先从最新从机恢复,然后将mha收到宕机主机缺省的binlog发送给从机,识别差异的relay log并将差异的事件应用所有的relay log
-
将所有从机指向为候选主机
启动MHA Manger监控,查看集群里面现在谁是master。
(7)检查切换后数据是主从数据是否一致
在主机和候选主机上分别安装percona-toolkit,安装流程及使用文档请查看percona-toolkit 简明教程。
这里简单说下pt-table-checksum 的工作原理: pt-table-checksum 在主上执行检查语句在线检查mysql复制的一致性, 生成replace 语句,然后通过复制传递到从,再通过update更新master_src 的值。通过检测从上this_src 和master_src 的值从而判断复制是否一致。注意: 使用的时候选择业务地峰的时候运行,因为运行的时候会造成表的部分记录锁定。 使用–max-load 来指定最大的负载情况,如果达到那个负载这个暂停运行。 如果发现有不一致的数据,可以使用pt-table-sync 工具来修复。
在切换后的新主机上使用命令:
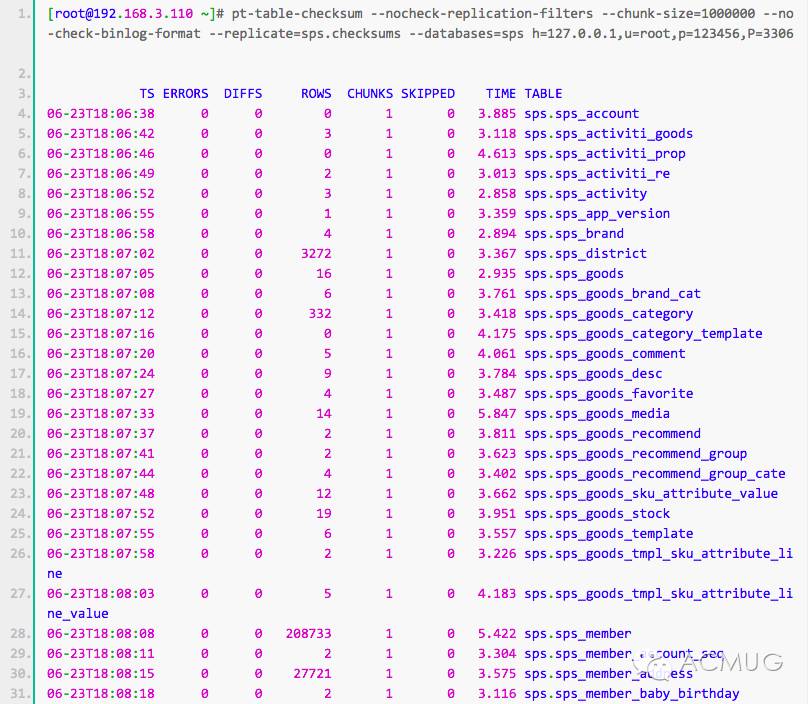
从结果中,我们可以看到DIFFS都为0,说明主从数据一致,故障切换流程没有数据丢失。
14.2.手动Failover(MHA Manager必须没有运行)
手动failover,这种场景意味着在业务上没有启用MHA自动切换功能,当主服务器故障时,人工手动调用MHA来进行故障切换操作,具体命令如下:
注意:如果MHA Manager检测到没有dead的server,将报错,并结束failover:

进行手动切换命令如下:

14.3.修复宕机的Master
通常情况下自动切换以后,原master可能已经废弃掉,待原master主机修复后,如果数据完整的情况下,可能想把原来master重新作为新主库的slave,这时我们可以借助当时自动切换时刻的MHA日志来完成对原master的修复。下面是提取相关日志的命令:

获取上述信息以后,就可以直接在修复后的master上执行change master to相关操作,重新作为从库了。
本文未完,Keepalived+Atlas+LVS部分将在本文(下)中阐述,敬请期待。
注:ACMUG收录技术文章版权属于原作者本人所有。
关注ACMUG公众号,参与社区活动,交流开源技术,分享学习心得,一起共同进步。 


 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

