一、前言
我突然发现,由于业务、网络的复杂性会让主从架构出现各种棘手的问题。
Slave_SQL_Running: No mysql同步故障,遇到过很多次!
初步解决方案只能跳过错误了:
stop slave;
set global sql_slave_skip_counter=1;
start slave;
Slave_IO_Running: No
stop slave;
reset slave all;
CHANGE MASTER TO MASTER_HOST='192.168.1.60',MASTER_USER='repl',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000012',MASTER_LOG_POS=107;
start slave;
show slave status;
如果出现故障可以参考如下两篇文章
http://storysky.blog.51cto.com/628458/259280/
http://www.jb51.net/article/109107.htm
1、在slave机器上设置只读权限并且关闭自动清除执行完的中继日志relay log
将以下参数加入my.cnf里:
[mysqld]
read_only = 1
relay_log_purge = 0
注:设置read_only只读模式的目的是防止slave上被人工误写入数据,保证主从数据一致性。
关闭自动清除执行完的中继日志relay log的目的是假如一台从库没有接受完主库的binlog,通过MHA把最新的slave上的中继日志发送到最老的slave上,识别差异中继日志并补齐数据。
我们可以通过定时任务,写入crontab里,例如每天凌晨5点清除一下relay log,那么可以这样:
安装:
CentOS系统安装crontab:
[root@CentOS ~]# yum install crontabs
定时清理中继日志,
# crontab -l 0 5 * * * /usr/local/mysql/bin/mysql -S /tmp/mysql.sock -uroot -pzhangtongle123 -e "set global relay_log_purge = 1;flush logs;set global relay_log_purge = 0;flush logs;"
-----------------------------------------------------------------------------------------------------------------------
二、数据库进化
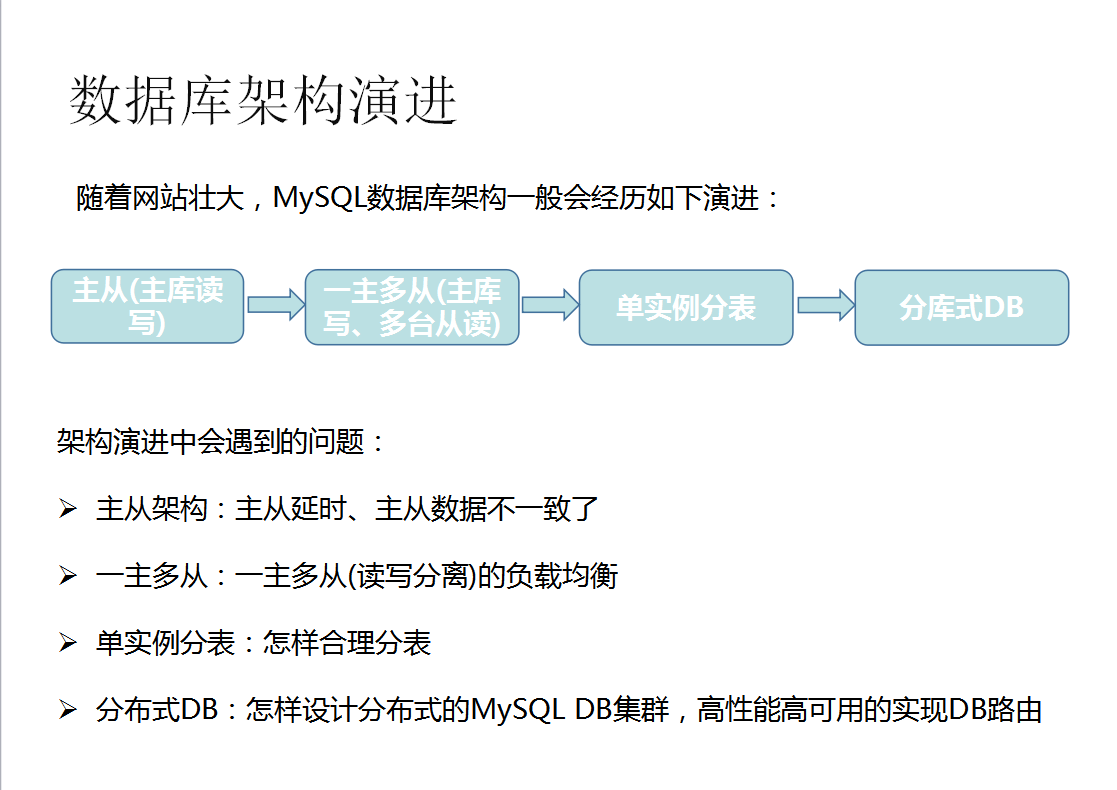
1、淘宝数据库初创

2、开始进化

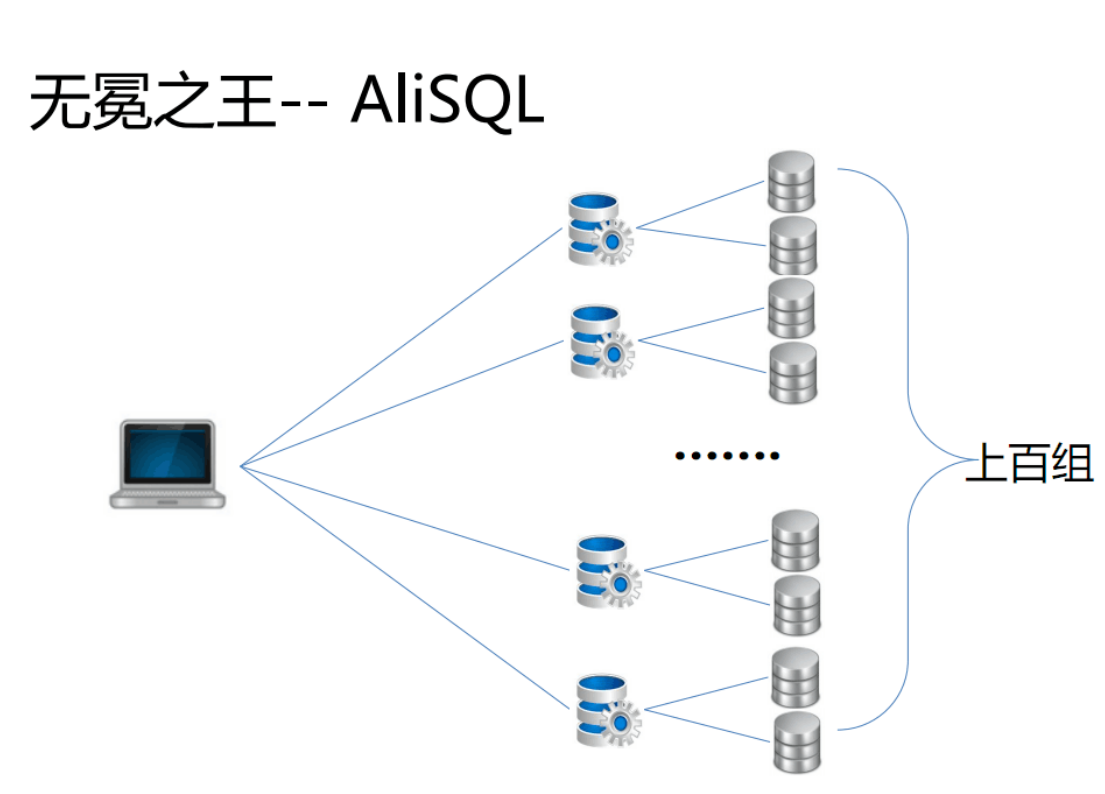
3、进化历程

4、大多数公司的架构

5、读写分离架构实现

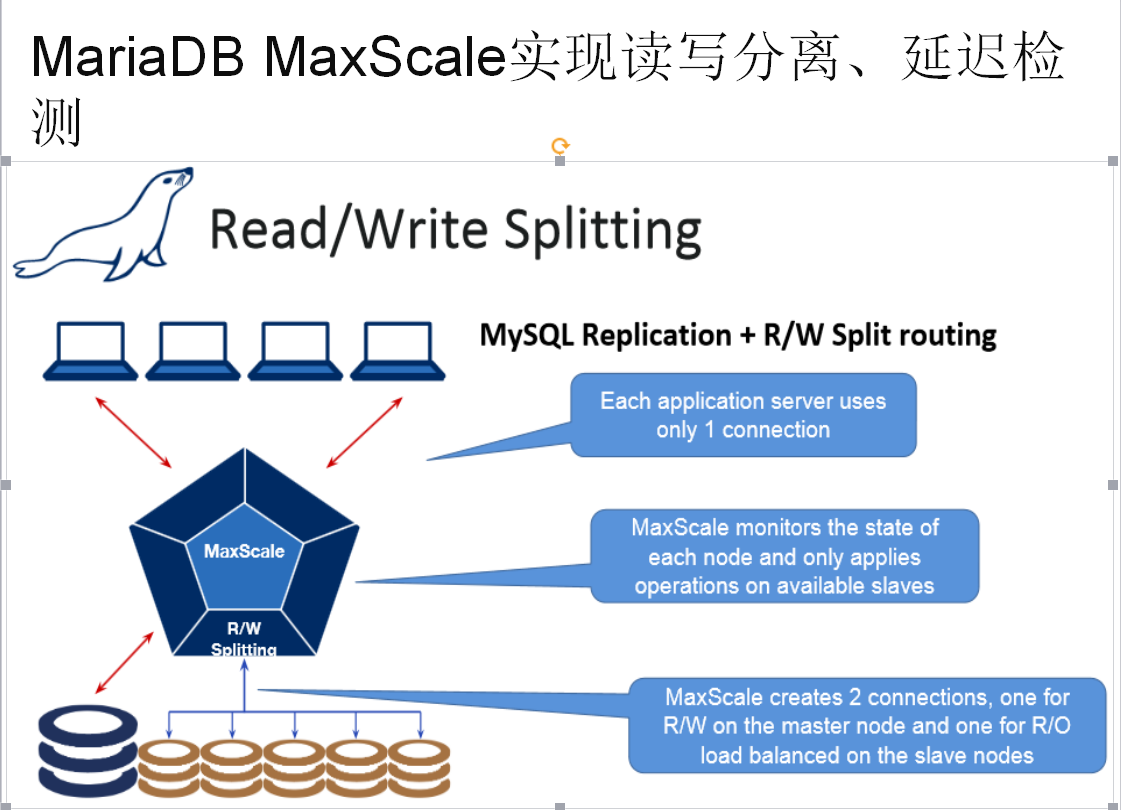


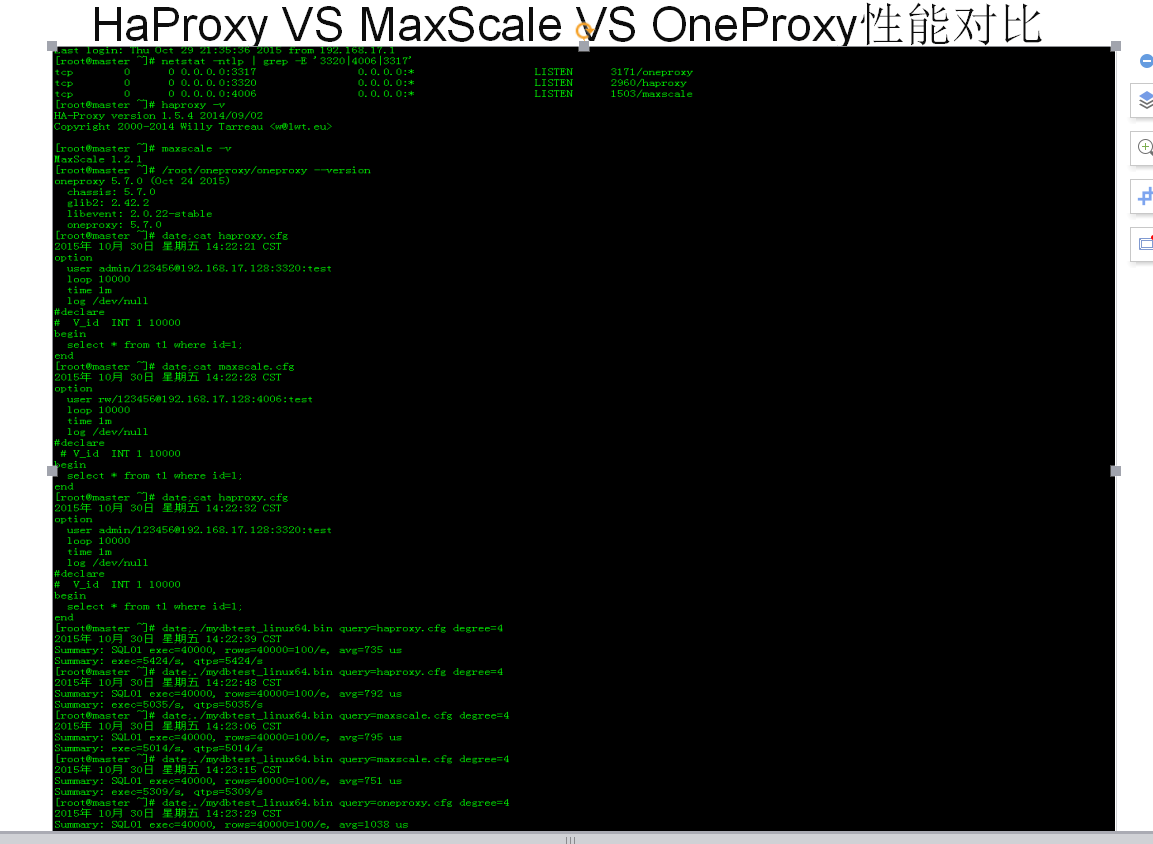
经过性能的基准测试,HaProxy,性能最好,其次MaxxScale 然后是OneProxy、
个人总结:MaxScale,非常灵活,可扩展性强,分库分表不是很成熟,不久的将来应该会很nb。服务要收费,说明人家做的好,才做服务收费!
最重要的问题!只要做集群,主从复制是核心,如果解决在业务高峰期,延迟的问题才是王道~。
保证集群秒级别数据同步!看了一下MySQL5.5是不支持多线程复制的,比它高的版本已经开启了,做好充足迁移可靠的方案,并且测试稳定的时候,可以考虑升级到最新版本~。。用钱直接上最牛逼的大内存这个可以有~,Mysql也可以玩最新版本,但是你得可控,不可控就不要玩~。,单表数据超过1千万,肯定要把xxx日期的,拆开并存储为归档表做归档标识!不拆不行,索引即使做的再好,前端高并发的select,和小白的各种selcet * ,也会堵你的服务器~, 大表就得进行策略性的拆分!以上是个人总结,不喜勿pen~

三、主从复制易发生的问题
1.问题一:主从复制,中继日志不断增长,如何设置中继日志自动清除
vi 配置文件my.cnf,在mysqld下增添
relay_log_purge=1 (自动清除中继日志打开)
重启mysql,这样SQL Thread每执行完一个events时才会判断该relay-log是否需要,已经不再需要则自动删除
2.问题二:主从同步失败,如何快速同步?
跳过错误,继续同步。设置SQL_slave_skip_counter=1;来快速恢复主从架构,但是此时主从架构的数据可能已经不一致了。 set global sql_slave_skip_counter=N; 当N等于1时,表示跳过若干个event,直到当前事务结束,而当N大于1时,每跳过一个event,都要N--设置--slave-skip- errors=[ err_code1[,err_code2][,all]] 跳过出现指定错误的SQL.如果要断开主从架构,应先stop slave io_thread;等待执行完relay log里的内容再stop slave;
3.问题三: io线程始终保持为connecting状态
主从架构中,从库的io_thread一直保持connecting状态。先理解Slave_IO_Running 为connecting,的含义。造成的主要有三个:
1、网络不通 (是否打开防火墙)
2、复制用户的密码不对 (主从同步指定的用户密码主机名限制)
3、pos不对 (指定的position不正确)
4.主键冲突,报1062错误
主从架构中,从库复制报1062错误,主键冲突。如果binlog是基于语句级复制,很容易出现上面的问题。设置 innodb_autoincr_lock_mode=0或是1或修改binlog_format=mixed|row
5.从库同步慢
主从架构中,从库的同步数据非常慢。出现主从同步慢的原因有:
1.主从同步延迟与系统时间的关系,查看主从两台机器间系统时间差
2.主从同步延迟与压力、网络、机器性能的关系,查看从库的io,cpu,mem及网络压力
3.主从同步延迟与lock锁的关系(myisam表读时会堵塞写),尽量避免使用myisam表。一个实例里面尽量减少数据库的数量。
6. change master时报错ERROR 1201 (HY000)
表现:在搭建主从时,报1201错误 。ERROR 1201 (HY000): Could not initialize master info structure; more error messages can be found in the MySQL error log
解决方法:出现这个问题的原因是之前曾做过主从复制!需要reset slave后再change

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

