一、前言
环境: 192.168.1.61 (主库) 、192.168.1.60(从库)、192.168.1.62(从库) 192.168.1.59 位MHA架构的管理机器。
测试:在主库61上创建数据库,表,并插入一条数据,
CREATE DATABASE mydb3 CHARACTER SET UTF8 COLLATE UTF8_BIN;
CREATE TABLE employee(id INT,name VARCHAR(20),gender CHAR(2),birthday DATE,salary double,resume TEXT);
INSERT INTO `employee` VALUES ('1', '张三', '男', '2017-04-30', '2000', ‘大专’);
然后通过主从复制,从库在x.xxx秒左右原封不动就会同步到从库上,随着数据量的增大,主从复制也会浪费机器的性能,一利就有一弊,现在机器性能这么好~,这点性能损耗可以忽略不计,如果性能还是慢的,那是因为架构设计的垃圾,前端程序写的更垃圾,数据库设计的更是垃圾,没有一个好的索引系统,没有一个好的中间层。没有用到缓存的xxx工具,没有效的负载均衡! 大多数程序猿的sql都没有正常成熟的DBA运用的更666,所以请不要忽略DBA,如果程序慢了,可以找个成熟的DBA,分析下慢在哪里!从源头分析赶脚效率哇哇提升是可以的!
然后在在从库上插入数据,这样主从的数据就不一致了。不知道为什么不一致的同学,自学百度脑补数据库的复制技术,以及翻阅我之前偶的博客!
接下来重点:我们用PT工具可以检测出,从库和主库哪里不一致!
安装PT工具
yum install -y https://www.percona.com/redir/downloads/percona-release/redhat/latest/percona-release-0.1-4.noarch.rpm
yum install -y percona-toolkit
1、千万不要有空格,有严格的语法要求,要不然会报错~
----------------------------------------------
#写主库的IP地址
pt-table-checksum h='192.168.1.61',u='root',p='RU5DMF4xbFsvbIggFlrMMuvcAtDXImKMd+lcdMtDOtxT+rjhoFmNXvWWBb6ZdnBFhybZ+YiuZoBdm0SxuOzmhfT1Br9OD5fmaS2NThbdgKwoIiSNJowwyqo0qaf13bvEb7/3KwY5GDfmDByKnM3kuQUX2IBeCnaaQT6zEw2/XjeMD+//2GhZ66DW4kJacVpoAXM4H5Pb3HQf6H4+vE2pHDPEozwvy2qVbjDPZK2f/IVYiyb28ll2U8x0Z9Xf27ZTPRlH8Q==',P=3306 --databases "mydb3" --tables "employee" --nocheck-replication-filters --replicate=mydb3.checksums --no-check-binlog-format
----------------------------------------------
检测主从数据库数据是否一致:

DIFFS 等关1,就代表主从数据不一致。
pt-table-checksum h='192.168.1.61',u='root',p='zhangtongle123',P=3306 --databases "mydb3" --tables "employee" --nocheck-replication-filters --replicate=mydb3.checksums --no-check-binlog-format --replicate-check-only

检测出哪块不一致,下面两个语句执行效果都是一样的:
----------------------------------------------
#写从库的IP地址
pt-table-sync --replicate=mydb3.checksums --sync-to-master h='192.168.1.60',u='root',p='RU5DMJN6XJteKyB4tbbNc7ITzRWcVbNIda3VrIQ535Osqoyvg6c64PL4RqydasBlyLNRgodmYU5dpwTWzhRM+ThV4mXOTX+VQuTi7XZTpsn49WV4r1U45ZFa9IqpBzDuyGNfXfh/9FzYucBBjL3PrkRONQopiL+SIE44Rjli3v7ymQuaWnMSltu4fHHYRDUsfaOtQFGtppb5vwPopwJEpz8m680iguFPs2IDqo6aPHHZxunMNPfJImEdKuI6CCwqqFngKw==',P='3306' --databases=mydb3 --tables=employee --print
----------------------------------------------
----------------------------------------------
#写主库的IP地址
pt-table-sync --replicate=mydb3.checksums h='192.168.1.61',u='root',p='RU5DMKXeqor/IIK/Q2KFhEUhsnB6Ksm+NU0HGtnklLlJxeRGk0VbkZgFjE8bnXImcsj3qElS20ZXoG2zLzQ7w2S/9xK1J3UIXCaWxsW5XajTWGv/giTmcfhJCnfg5nv6sP5DUK6J9bmSyYZI/EdJZPh8sb0ehaE4N7G7QLeY9IPwnJkJbkgmZqhoKHU4huw0QxB6zqOVuKQ7gKjZ8GpfVM/SWymDi0RZrT5PzILiMbEWwyfygyIw5WWBsy31OBvfYEHCFA==',P='3306' --databases=mydb3 --tables=employee --print

删除从库与主库上不一致的数据。
pt-table-sync --replicate=mydb3.checksums h='192.168.1.61',u='root',p='RU5DMImlb+JvZ5okcBDGjvDUXvE8Ti5OyWCpuU+z8C+L4YTkFEDz6I4HaWMllyn1SFXwKaP64fPD+e6Z2F2UQsDw9PcyHE+dhkoN9kroKz7Xl16IrHxR5/7i4nbH4+PmFAidZMMIxonMECVvVVE3xjvW5QHrUfG4zR/AfwbfVtUSJKE9EMdJhKdhcr9sx+tpGr9nwHJVGW9j6/miXCDl1Zts+oERrNVMvs60/ILzIA+kRAAjb19zcR/tlxYkBtjIOq3PoA==',P='3306' --databases=mydb3 --tables=employee --execute

验证:

接下来继续验证主从数据库是否存在不一致:
pt-table-checksum h='192.168.1.61',u='root',p='RU5DMEWpnx8O8txptKRgwVPYMKOtxBdZuouw6bcwrVbPgUl0zqqaQINwGH23G6z2pRvn7jKtVEo+bJeDT0Nz3qFcejFbQLo5uDS2K6YfcEcnWuiHo5rmXO4YM1uRIaDYXmrhDKpJg9FEgYvV+7ZWtSbDfK7vnWJHOWoseCOlNstAyP2jdkcVR8VraPjN/Avs0Atl42GHy0MmbXynDIF3IxGqw1SARWcWNIpoPuKVq9H4UTA1JYPDivkIGDVvIyOpo6+7Iw==',P=3306 --databases "mydb3" --tables "employee" --nocheck-replication-filters --replicate=mydb3.checksums --no-check-binlog-format
图中DIFFS为零证明主从数据已经一致了!

使用PT工具注意事项:
PT-table 在执行的时候,默认会lock住1万行数据,建议是凌晨后进行执行pt-table操作。以及业务低峰期进行执行。
如果哪家公司的DBA,不经常在凌晨以后工作,那说明他不是好的DBA。
二、通过MHA进行数据补齐
开启半同步复制:
slave1:61 mysql> set global sync_binlog=1

主库和从库都需要执行下面的语句:
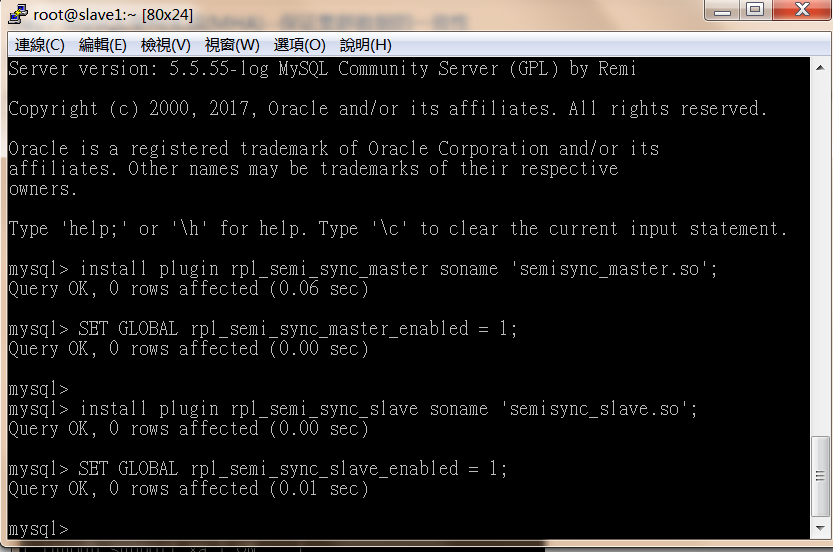
install plugin rpl_semi_sync_master soname 'semisync_master.so';
SET GLOBAL rpl_semi_sync_master_enabled = 1;
install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
为了保险起见:在my.cnf 都加入:
rpl_semi_sync_master_enabled=1
rpl_semi_sync_slave_enabled=1
复制上面的语句在mysql命令行你直接复制即可(记住主库和从库都要执行)。
首先加载vip到slave1。
ip addr add 192.168.1.100/32 dev eth2
查看mha是否开启,并查看复制是否妥当。
masterha_check_status --conf=/etc/app1.cnf
没开启,就开启mha。
mha_sh>./startmha.sh
检查mha环境下复制链路是否健康。
masterha_check_repl --conf=/etc/app1.cnf
首先安装测试工具sysbench :
yum install -y sysbench
需要脑补的mysql基准测试资料:
http://www.cnblogs.com/cbzj/p/6763743.html
http://www.tuicool.com/articles/QFzIF3
http://www.cnblogs.com/cbzj/p/6763743.html
接下来通过下面这条语句做主库slave1,61的压力测试!
压测语句(不知道参数是啥,可以百度自行补脑~)进行主库压测,salve1:61 库名为mydb3
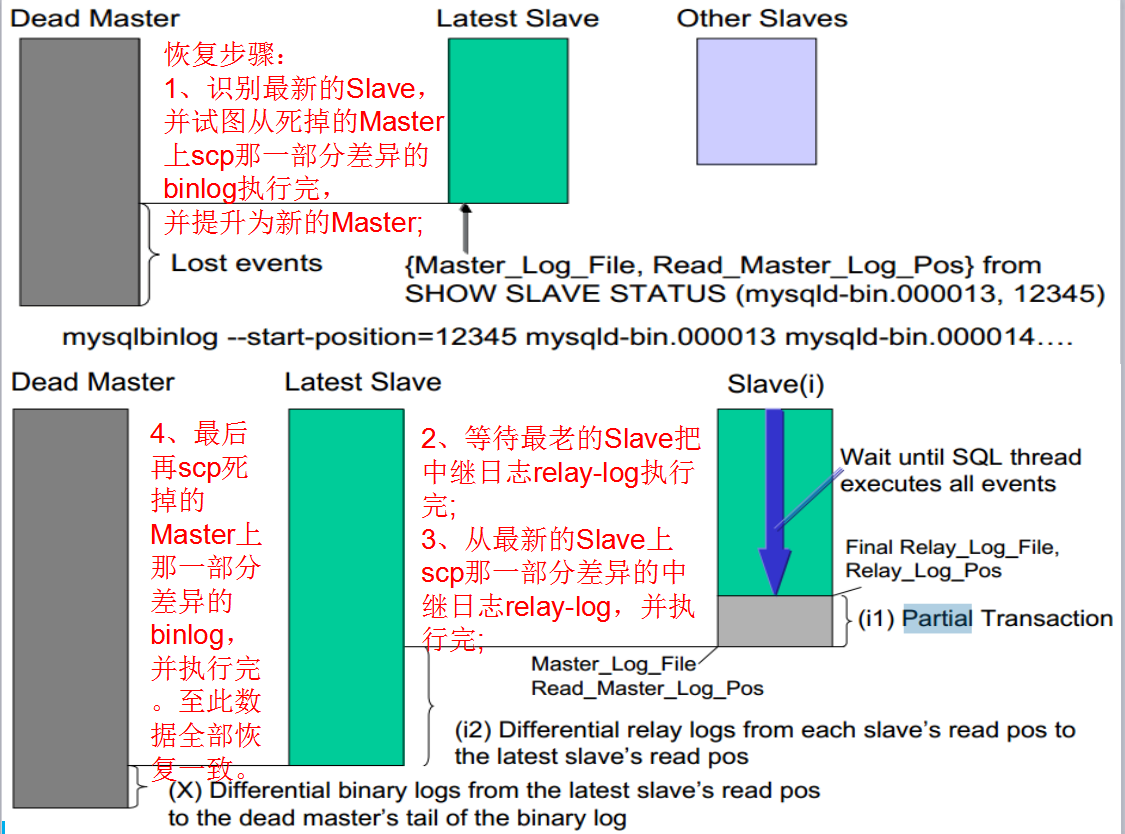
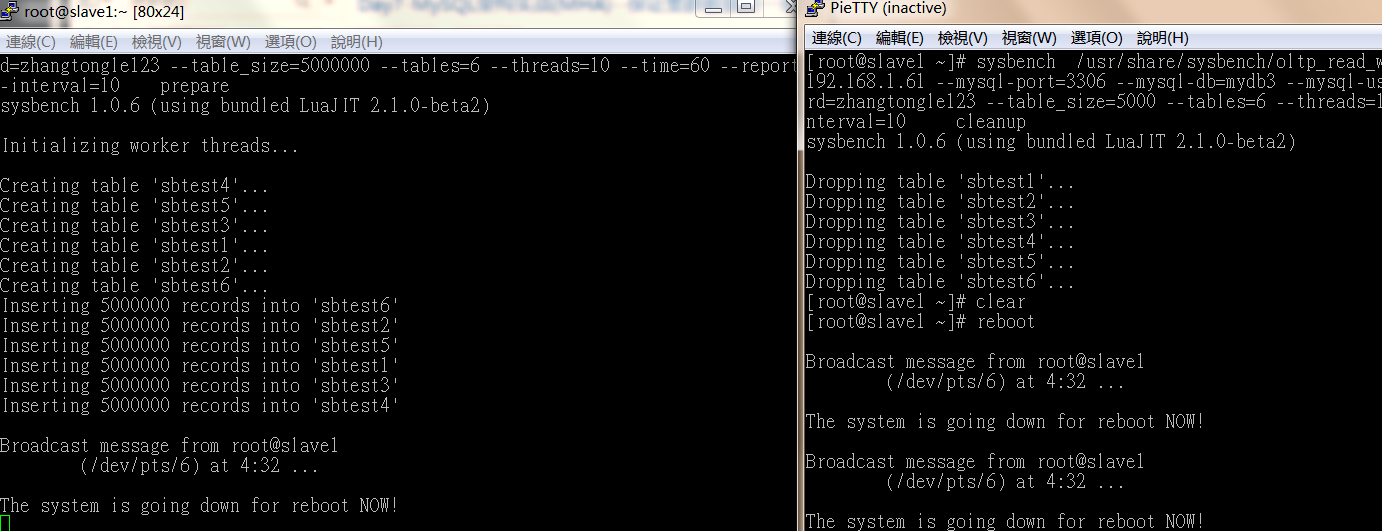
为了趋向真实,在开启mha架构的同时,在主库上生成5百万条数据,生成一多半的时候,主库突然宕机,然后我们在查看对比一下,主从库的数据是否是一致的。
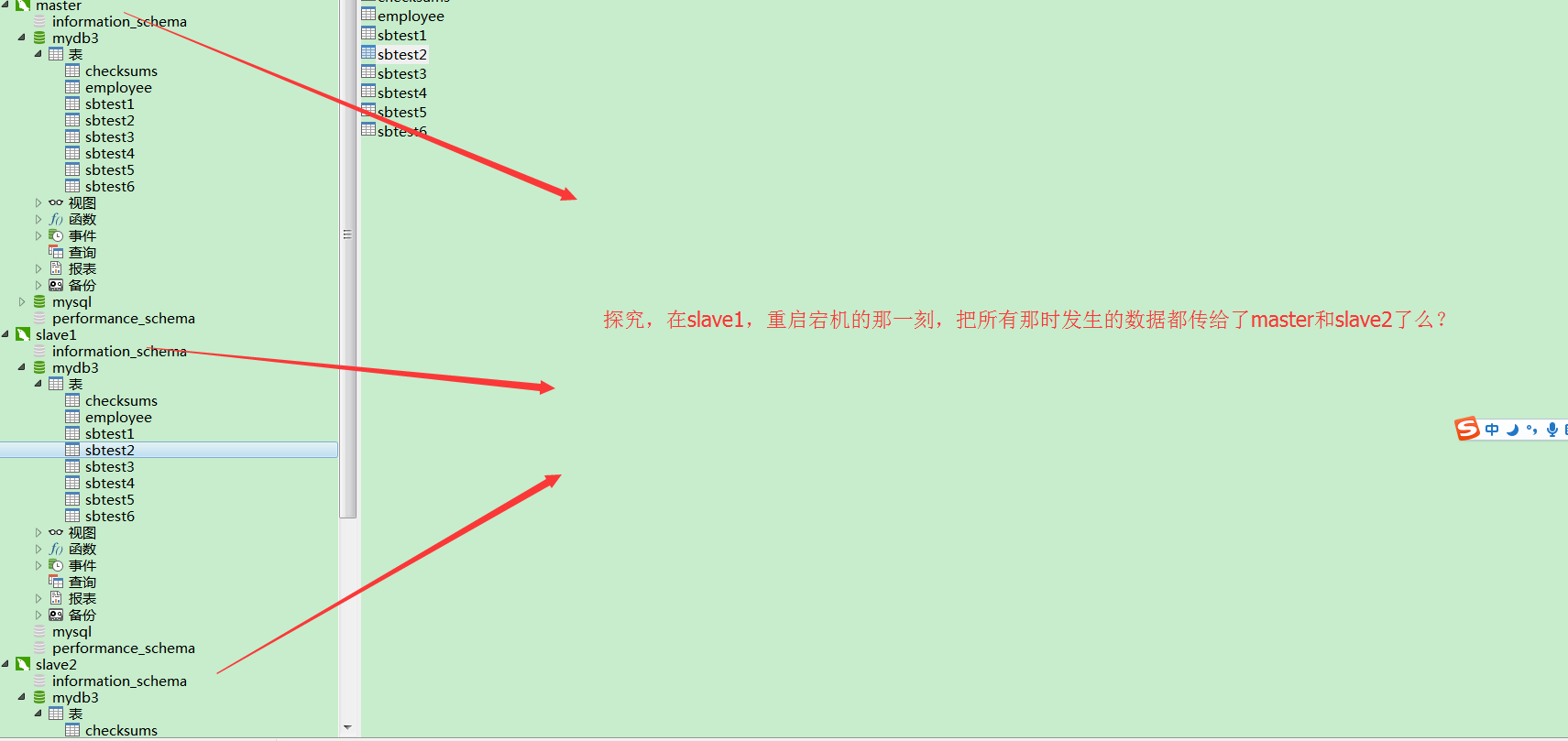
在探寻它们是怎么做的数据补齐。根据我们下面这幅图来研究:
1、准备数据
sysbench /usr/share/sysbench/oltp_read_write.lua --mysql-host=192.168.1.61 --mysql-port=3306 --mysql-db=mydb3 --mysql-user=root --mysql-password=zhangtongle123 --table_size=5000000 --tables=6 --threads=10 --time=60 --report-interval=10 prepare
2、运行
sysbench /usr/share/sysbench/oltp_read_write.lua --mysql-host=192.168.1.61 --mysql-port=3306 --mysql-db=mydb3 --mysql-user=root --mysql-password=zhangtongle123 --table_size=5000000 --tables=6 --threads=10 --time=60 --report-interval=10 run
3、清理
sysbench /usr/share/sysbench/oltp_read_write.lua --mysql-host=192.168.1.61 --mysql-port=3306 --mysql-db=mydb3 --mysql-user=root --mysql-password=zhangtongle123 --table_size=500000 --tables=6 --threads=10 --time=60 --report-interval=10 cleanup
接下来我们开两个窗口,一个用sysbench 用来生成5百万条数据,另一个用来在生成过程中模拟宕机, 在slave1上执行reboot操作。
mha架构成功把虚拟ip移动到master 60上。

然后我们把刚才死掉的slave1,变成master的从库。
在app1.cnf 配置的log目录下
>cd /var/log/masterha
>grep -i 'change' manager.log 并把里面的change 语句复制出来在有slave1机器上执行。
CHANGE MASTER TO MASTER_HOST=' 192.168.1.60', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000005', MASTER_LOG_POS=408, MASTER_USER='repl', MASTER_PASSWORD='123456';
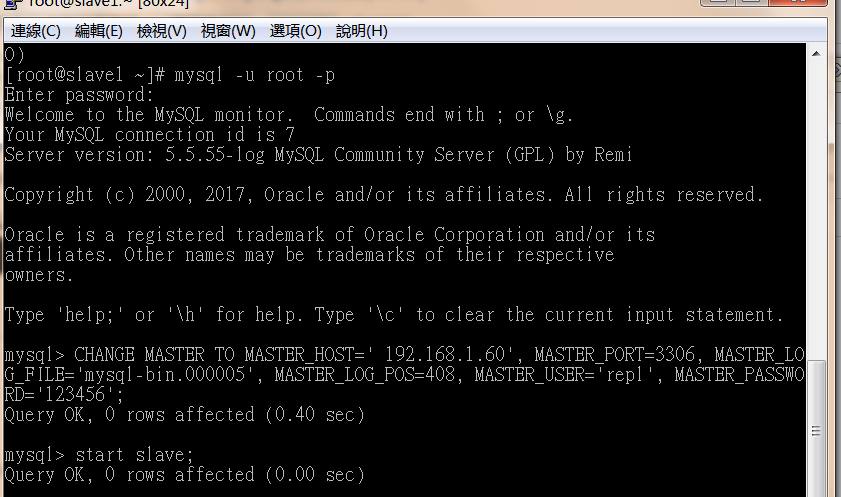
备注:有可能链接不成功:
stop slave;
reset slave all;
CHANGE MASTER TO MASTER_HOST='192.168.1.60', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000006', MASTER_LOG_POS=107, MASTER_USER='repl', MASTER_PASSWORD='123456';
START SLAVE;
show slave status
接下来我们利用PT工具检查集群中数据是否一致。
pt-table-checksum h='192.168.1.60',u='root',p='RU5DMOVHdr0N3jqRFaA3eL1a/NtSdSAzRr3lId4ivXK2QUMfcyfT+jmL0jnIc1uZYkZsZ4EMP/LFOTFp4baB8sX4H80fweroeS3FRGIuZ2Ovxo0wYBLJfj/bowtpeiOYoPxhJYT8IdANQX8ybnG2wGeP+tKkDpmfM/88bpL9xVAVoU1Ud+H26e7UJH12OXdLFFJC/TSoClWI6vpJp3T3vp3k9g5rl8qiimAyc3OMZMhOfT0NySTLAY2Dde+LXOItgamk/DIjRmZqmW3uAbhhCvA0zxYwnF5QMDBK5hEYbZUd/NwVwfl+Dvgj1+sk0KkqwgTMYIfKls63E0Tha8Jn8qtW/NDwGbekJao4kinGdcTeoj5zIRi6o7ZcDGYRXs2w+bXvN5w5joNOck1Ovd42eBXzsL6rVuJcdT77ipqD+hkKMwsg',P=3306 --databases "mydb3" --tables "sbtest5" --nocheck-replication-filters --replicate=mydb3.checksums --no-check-binlog-format
OK ~-结局是一致的!
期间会因为主从不一致出现主从失败:
解决方案
stop slave;
reset slave all;
set global sql_slave_skip_counter=1;
start slave;

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

