一、前言
三、为什么要学ETL
- “生产工具的进步是生产力发展的标志”。和传统的编写代码相比,ETL工具在效率(包括代码复用)、可靠性、低出错率、可维护性上面绝对都是巨大的进步;
- 对于程序员而言,使用ETL工具意味着很多习惯的改变,这个需要适应!我相信在ETL领域,编程语言的工作未来可能会减少到总任务量的10%,剩下90%均需要借助ETL工具来实现;
- 和任何工具一样,导入期都比较漫长,但是请各位务必坚持下去,因为回报会非常丰厚!
- 和任何工具一样,ETL工具也有自己的局限性,了解工具,熟悉工具的局限的领域是学习工具的目的之一;
- 使用ETL工具实现会非常容易,因此重要的就是大家的设计思路了。不要轻言ETL实现不了而轻易转到脚本或者其他编程语言,我本人就经历了多次,本来打算放弃ETL工具了结果再想想,发现另外一条设计路径完全可以用ETL实现;
- 在一定程度上Kettle的运行效率的确不如脚本,但是说实话从易用性和可维护性角度,以及日益便宜的硬件(内存,CPU),我觉得这点运行效率的损失完全不是问题;
- 特殊针对企业内部IT的人员:ETL工具队企业内部IT(尤其是针对很多开发的工作已经外包的情况)一个很好的选择,毕竟维护性和开发效率都很高,而且又不会把自己拖入繁复的代码维护和修改之中(改个ETL跟打游戏差不多,前提是你的设计思路很清晰)。
- 学习和使用ETL的最重要的基础,我相信是对数据库的了解和感觉。毕竟很懂ETL的step都和数据库密切相关,例如Kettle里面的DB Lookup步骤在MySQL数据库表建索引后效率可以提升10倍以上。输出表的结构设计和关联因此非常重要;
常用的ETL工具比较分析 (Kettle,Talend,Informatica 等)
软件成本包括多方面,主要包括软件产品, 售前培训, 售后咨询, 技术支持等。
开源产品本身是免费的,成本主要是培训和咨询,所以成本会一直维持在一个较低水平。
商业产品本身价格很高,但是一般会提供几次免费的咨询或支持,所以采用商用软件最初成本很高,但是逐渐下降。
风险:
项目都是有风险的尤其是大项目。
项目的风险主要包括:超出预算,项目延期,没有达到用户的满意和期望
开源产品由于价格上的优势,可以在很大程度上降低项目的风险。
Talend:有 GUI 图形界面但是以 Eclipse 的插件方式提供。
Kettle:有非常容易使用的 GUI,出现问题可以到社区咨询。
Informatica:有非常容易使用的 GUI,但是要专门的训练。
技术支持:
Talend:主要在美国
Kettle:在美国,欧洲(比利时,德国,法国,英国),亚洲(中国,日本,韩国)都可以找到相关技术支持人员。
Informatica:遍布全世界
Inaplex Inaport:主要在英国
部署:
Talend:创建 Java 或perl 文件,并通过操作系统调度工具来运行
Kettle:可以使用 job 作业方式或操作系统调度,来执行一个转换文件或作业文件,也可以通过集群的方式在多台机器上部署。
Informatica:需要有 Server
Inaplex Inaport:需要 .net 2.0
Talend:需要手工调整,对特定数据源有优化知识。
Kettle:比 Talend 快,不过也需要手工调整,对 Oracle 和 PostGre 等数据源做了优化,同时也取决于转换任务的设计。
Informatica:是最快的
数据质量:
Talend:在 GUI 里有数据质量特性,可以手工写 SQL 语句。
Kettle:在 GUI 里有数据质量特性,可以手工写 SQL 语句、java脚本、正则表达式来完成数据清洗。
Informatica:专门有一个产品 Informatica Data Quality 来保证数据质量
Inaplex Inaport:因为只处理特定数据,所以比较容易进行数据清洗。
监控:
Talend:有监控和日志工具
Kettle:有监控和日志工具
Informatica:有非常详细的监控和日志工具
Inaplex Inaport:有监控和日志工具
Talend:各种常用数据库,文件,web service。
Kettle:非常广泛的数据库,文件,另外可以通过插件扩展。
Informatica:各种数据源
1、Kettle概念
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
3.3运行Kettle
解压之后Windows下找到$KETTLE_HOME/spoon.bat,双击运行.
欢迎界面如下图所示:

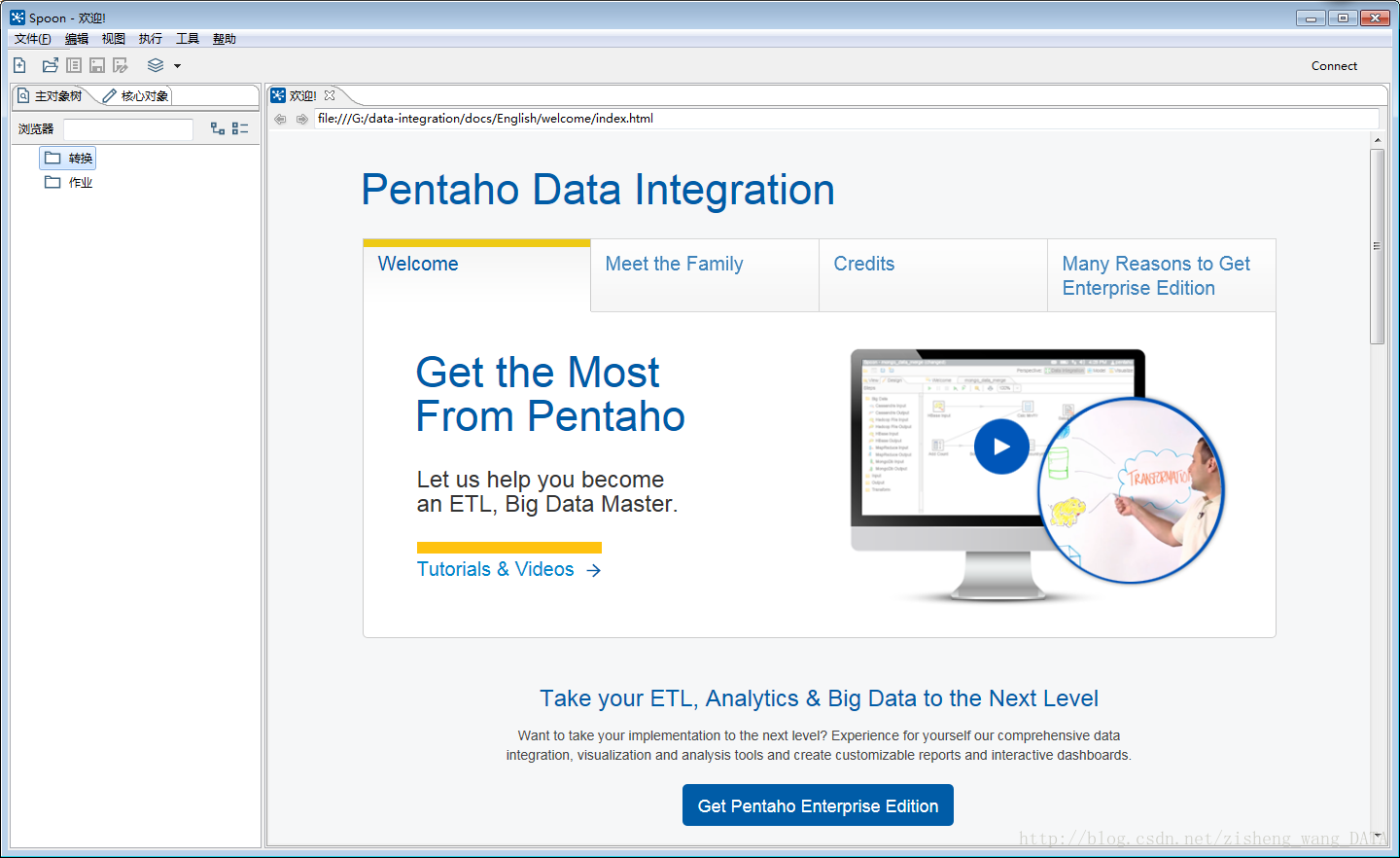
4、Kettle组件介绍与使用
4.1 Kettle使用
Kettle提供了资源库的方式来整合所有的工作,;
1)创建一个新的transformation,点击保存到本地路径,例如保存到G:/etltest下,保存文件名为Trans,kettle默认transformation文件保存后后缀名为ktr;
2)创建一个新的job,点击保存到本地路径,例如保存到G:/etltest下,保存文件名为Job,kettle默认job文件保存后后缀名为kjb;
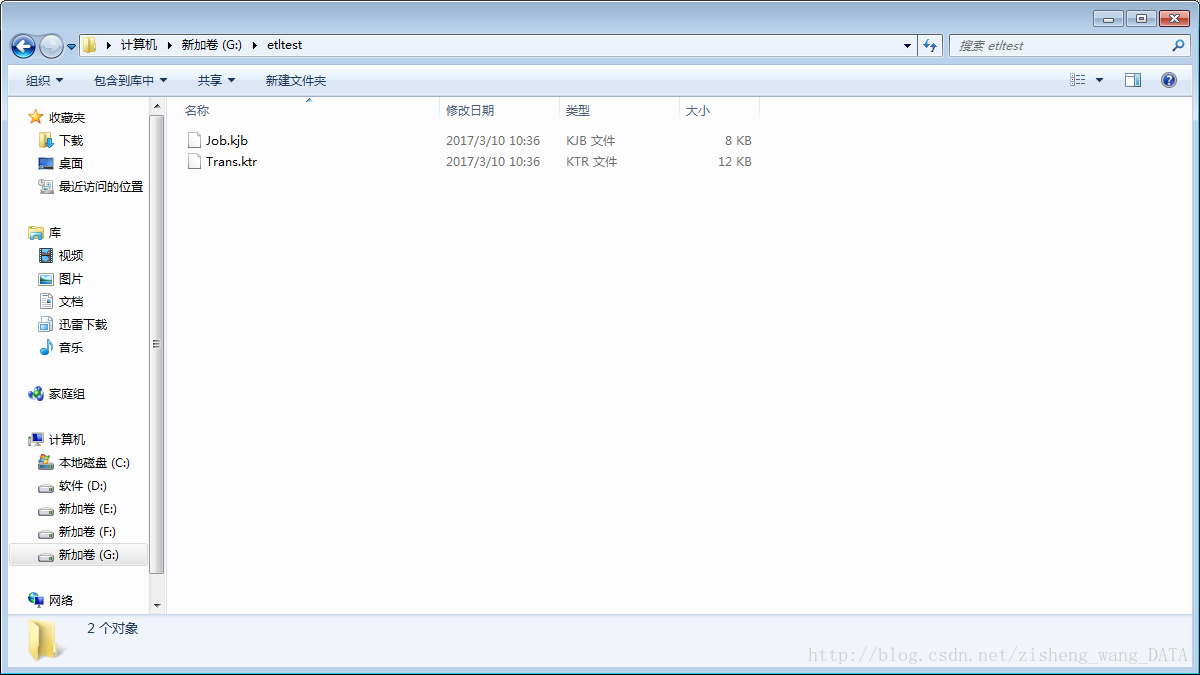
4.2 组件树介绍
4.2.1 Transformation的主对象树和核心对象分别如下图:
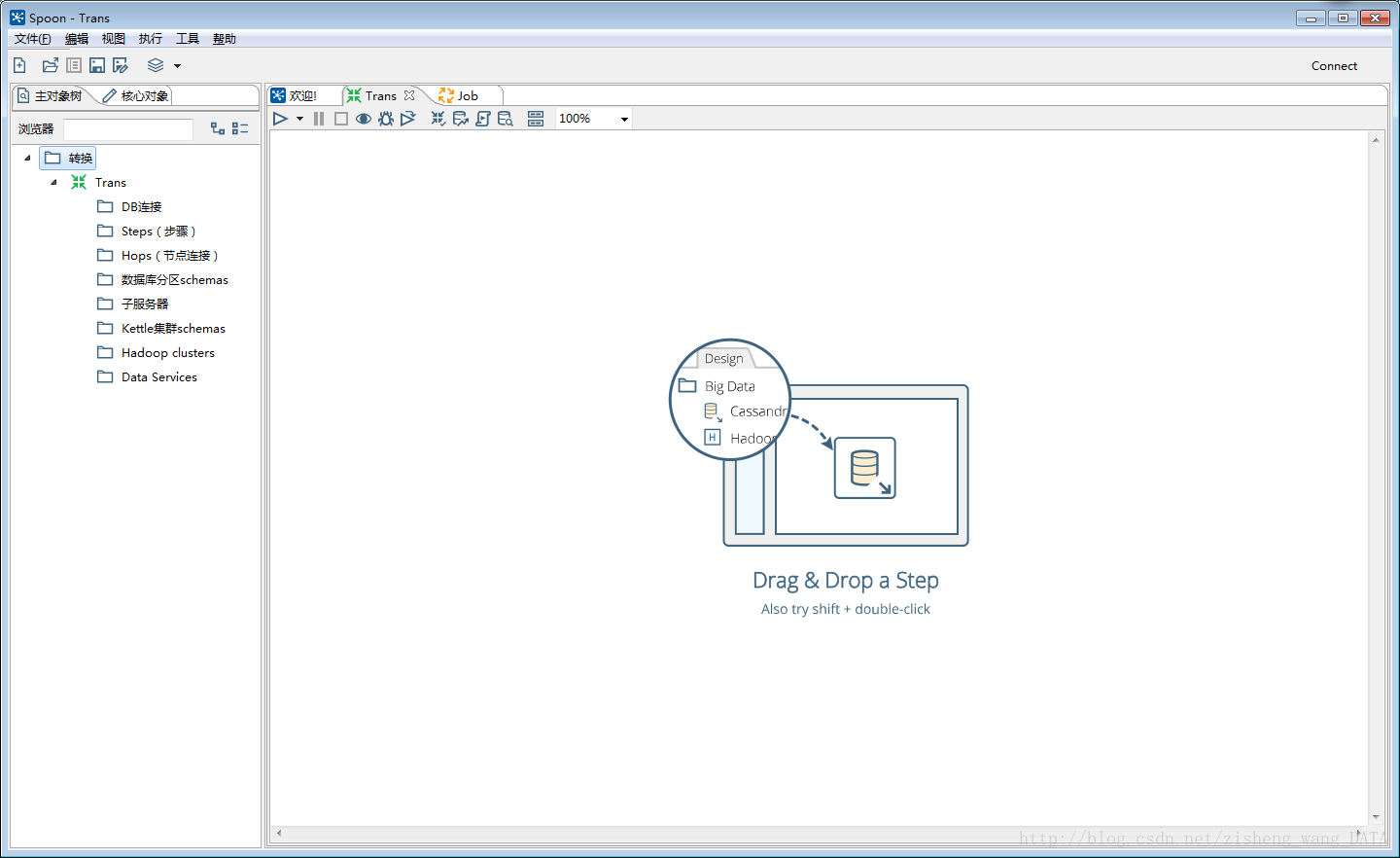
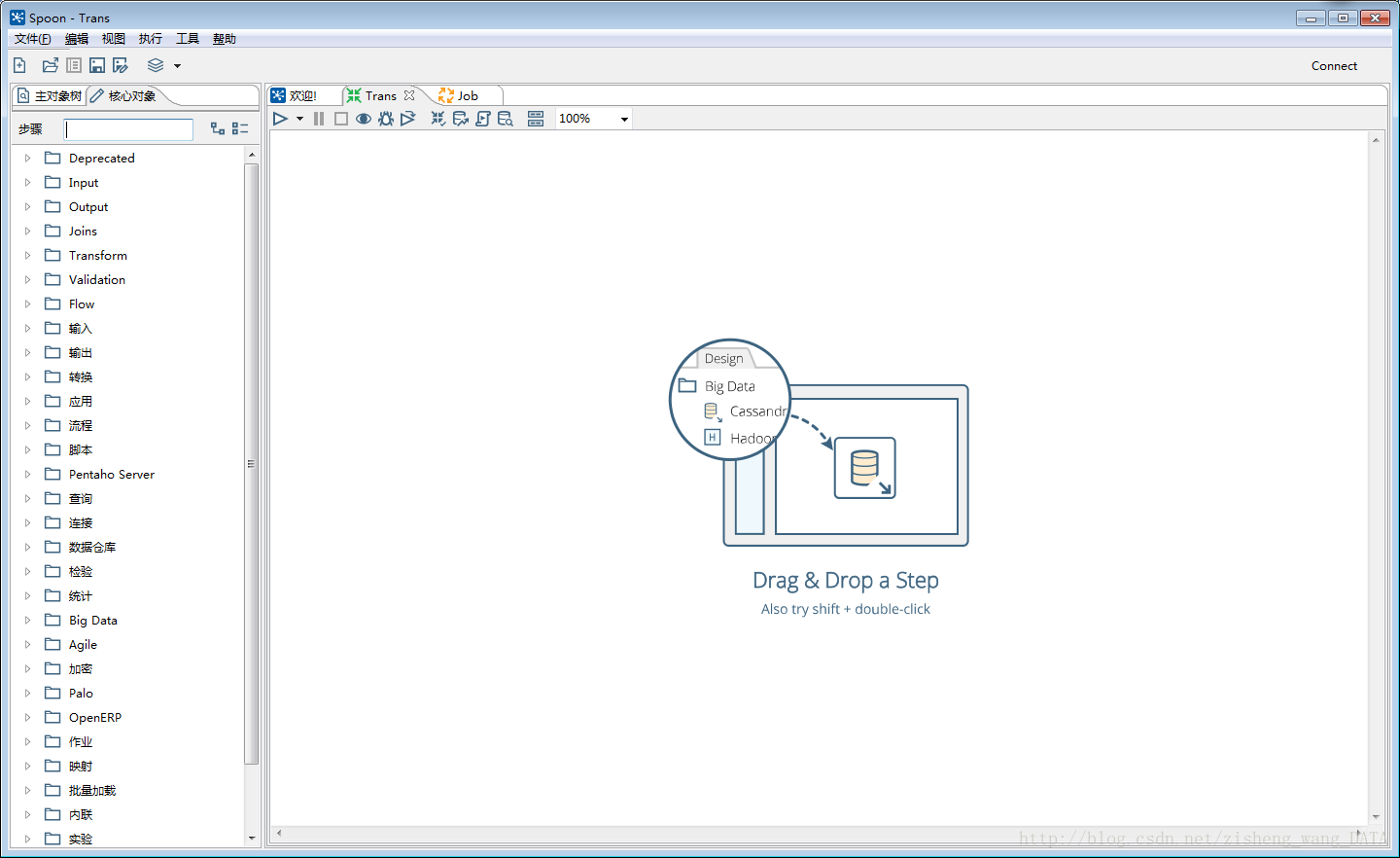
Transformation中的节点介绍如下:
主要对象树:菜单列出的是一个transformation中基本的属性,可以通过各个节点来查看。
DB连接:显示当前transformation中的数据库连接,每一个transformation的数据库连接都需要单独配置。
Steps:一个transformation中应用到的环节列表
Hops:一个transformation中应用到的节点连接列表
核心对象菜单列出的是transformation中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加:
Input:输入环节
Output:输出环节
Lookup:查询环节
Transform:转化环节
Joins:连接环节
Scripting:脚本环节
4.2.2 Job的主对象树和核心对象分别如下图:
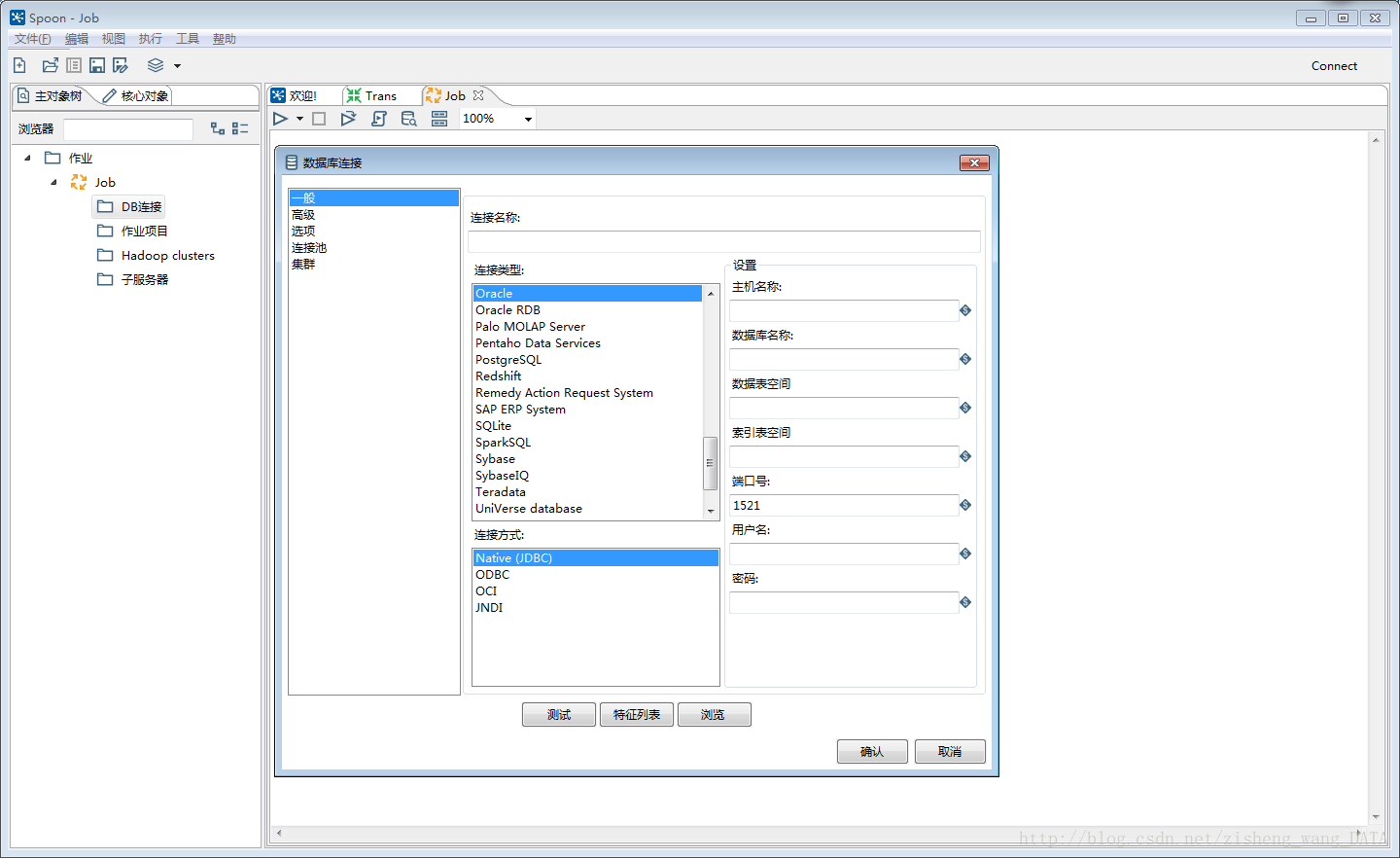
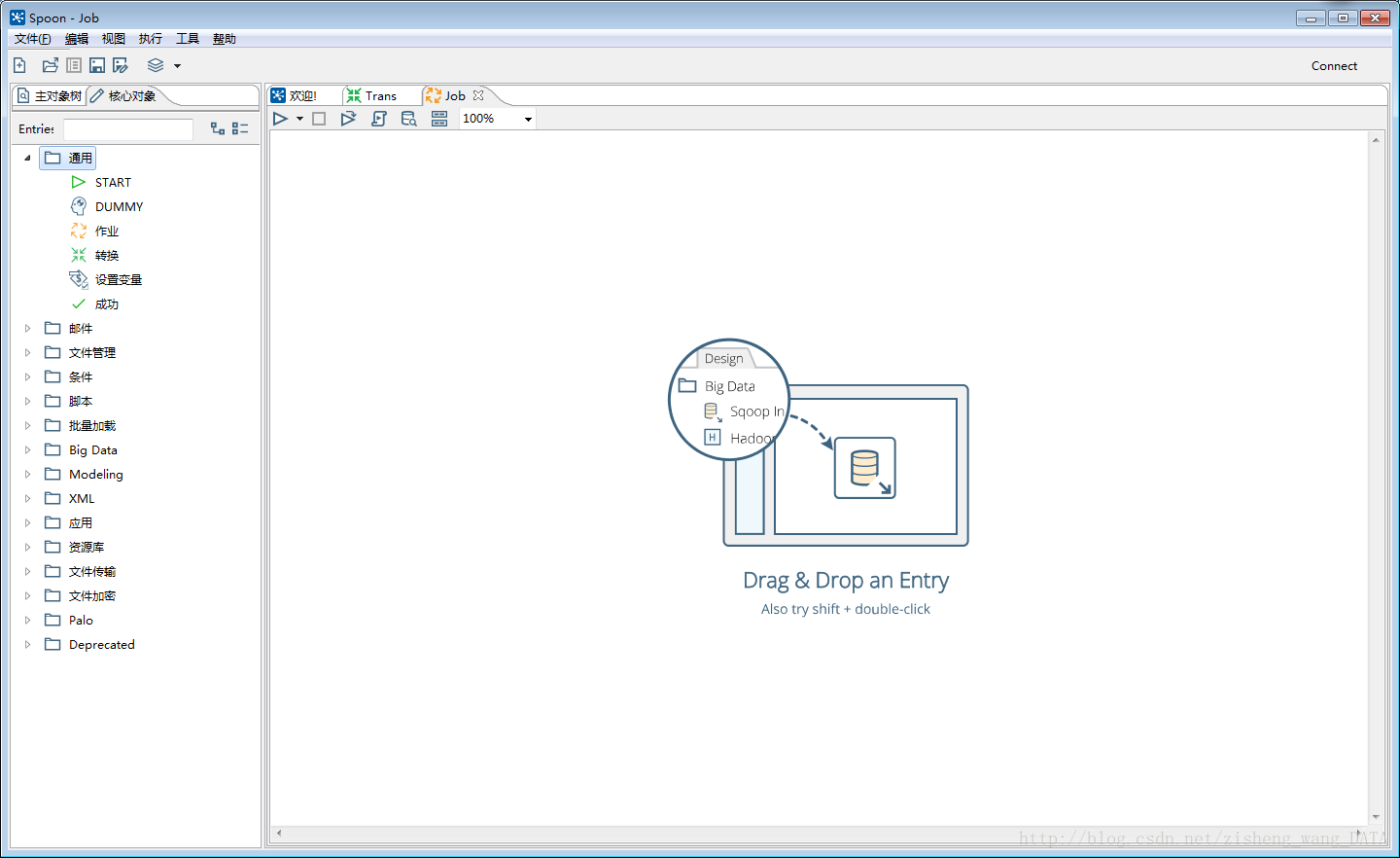
DB连接:显示当前Job中的数据库连接,每一个Job的数据库连接都需要单独配置。
Job entries/作业项目:一个Job中引用的环节列表。
核心对象菜单:列出的是Job中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加。
每一个环节可以通过鼠标拖动来将环节添加到主窗口中。
【例2】 运用资源库
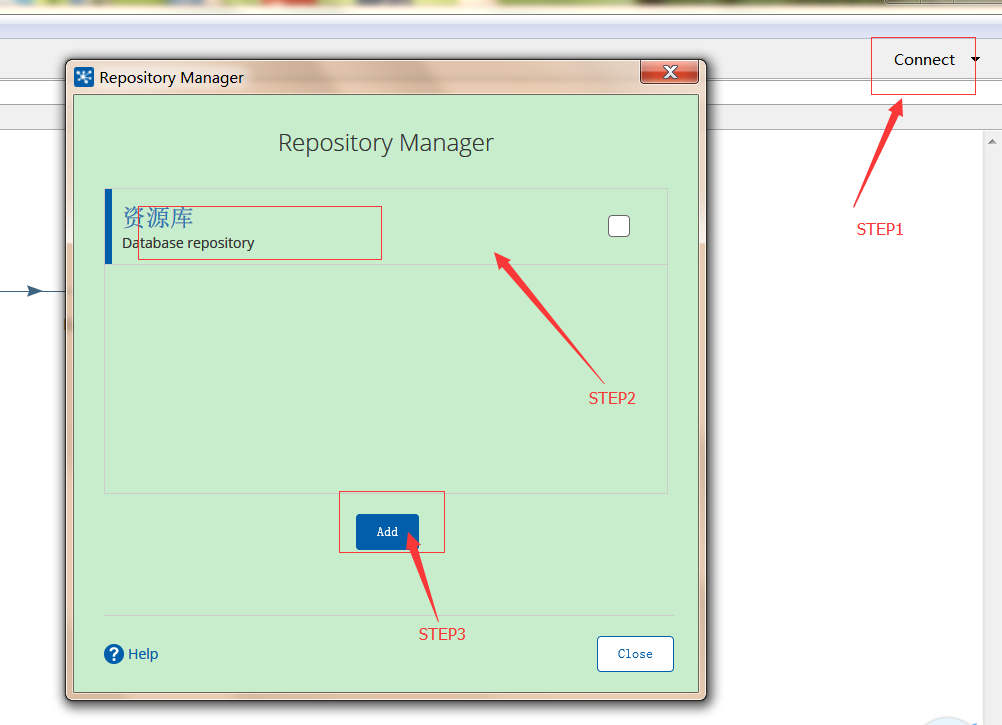
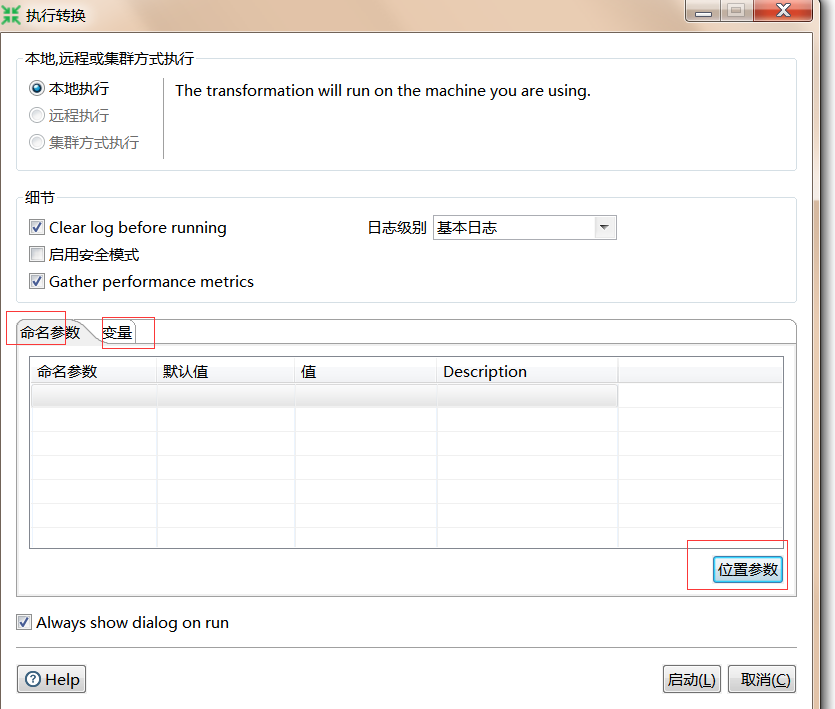
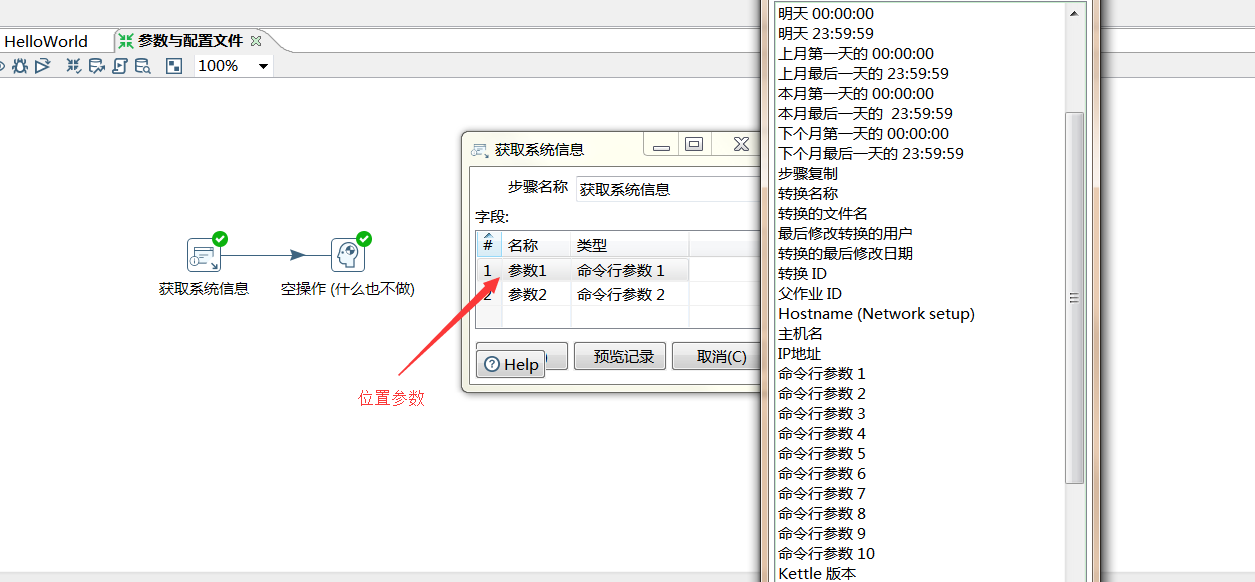
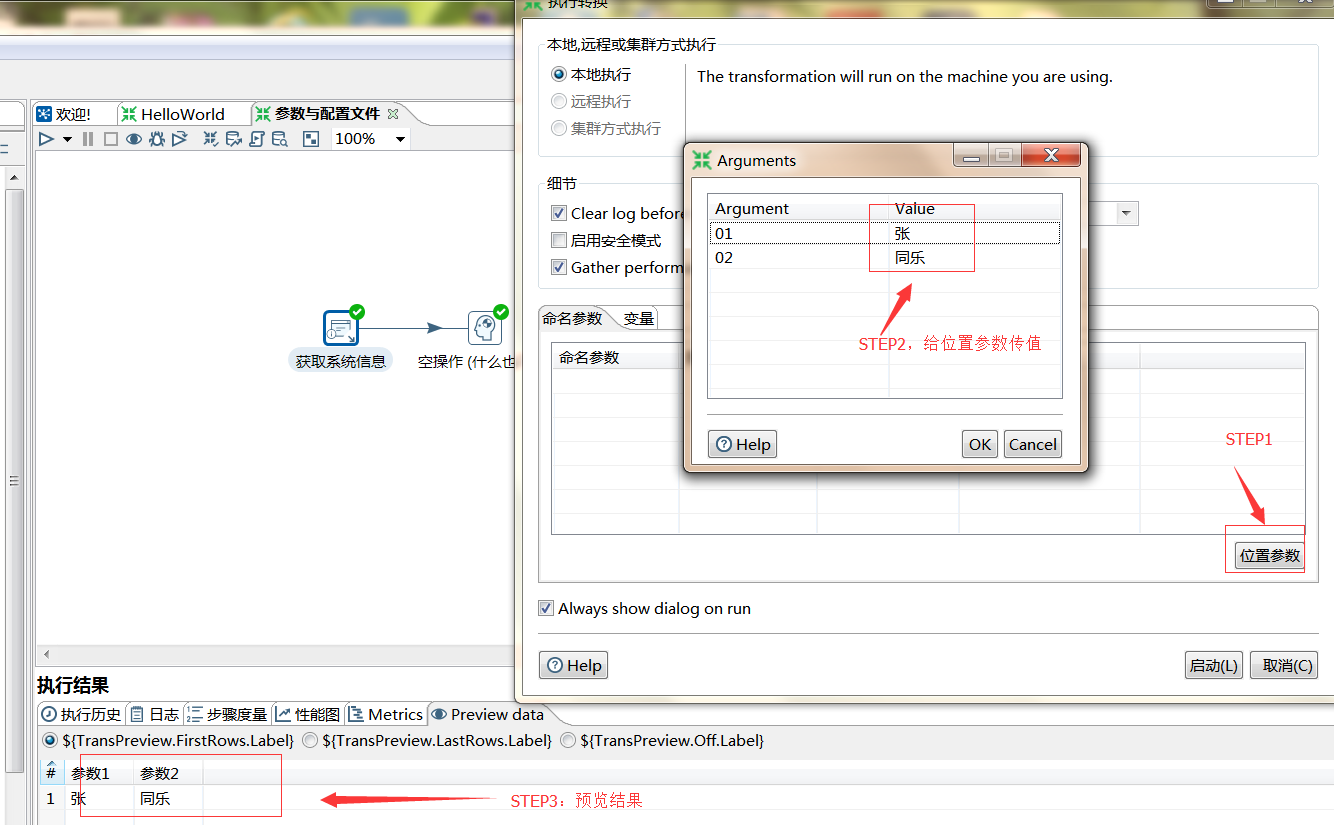
位置参数:
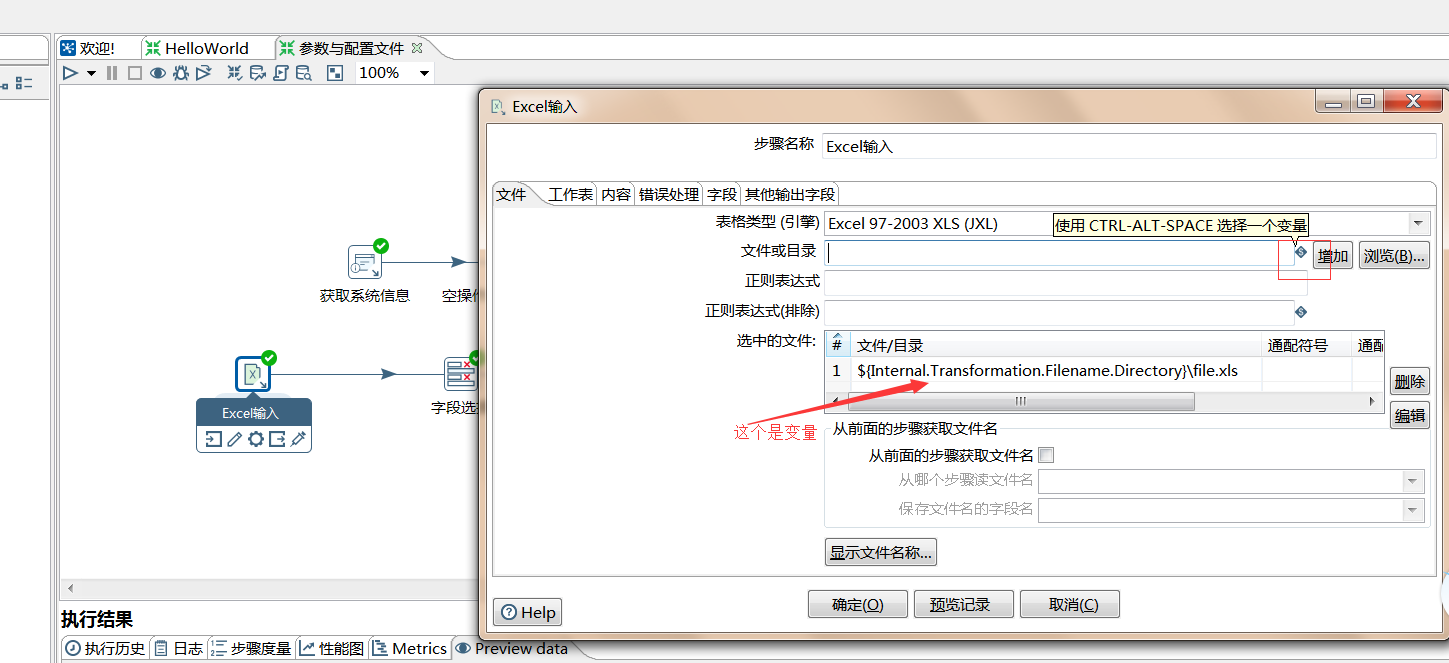
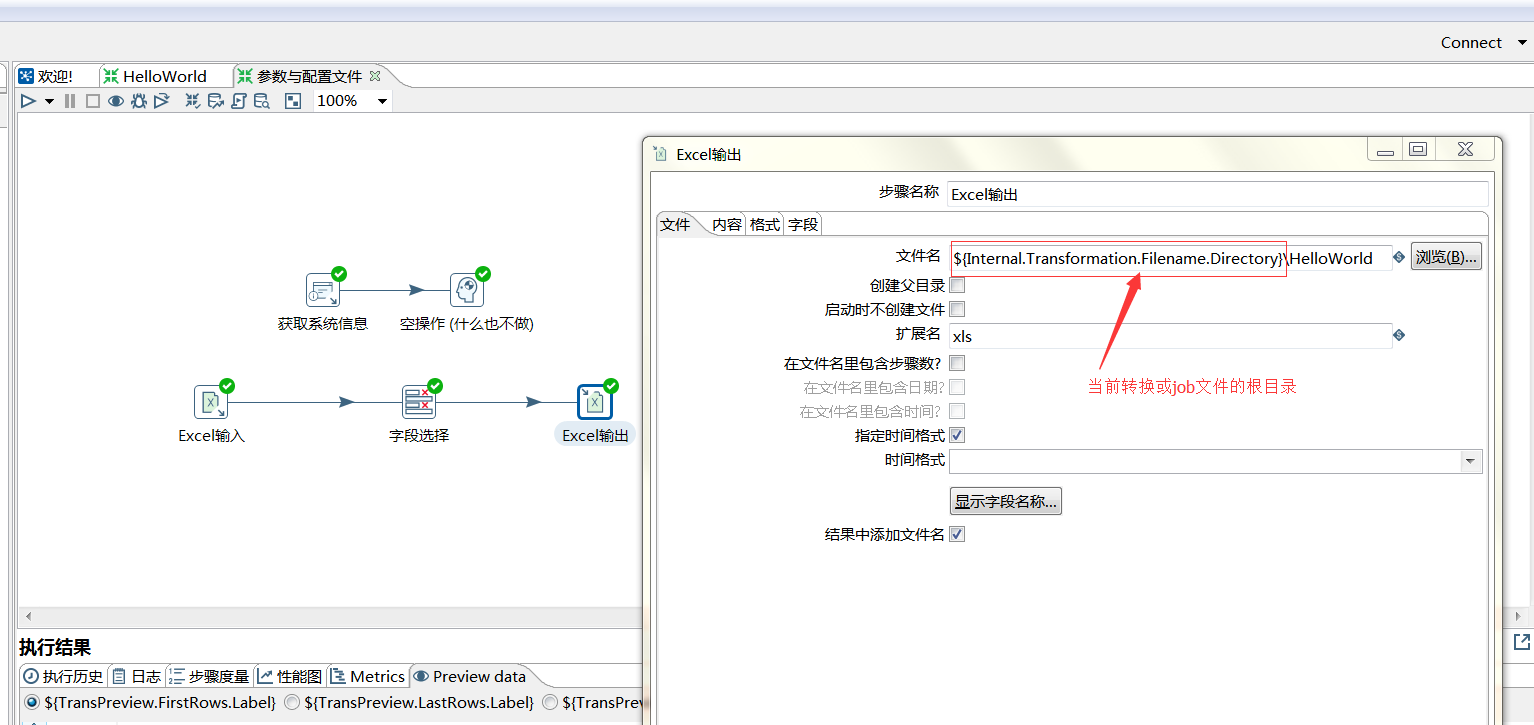
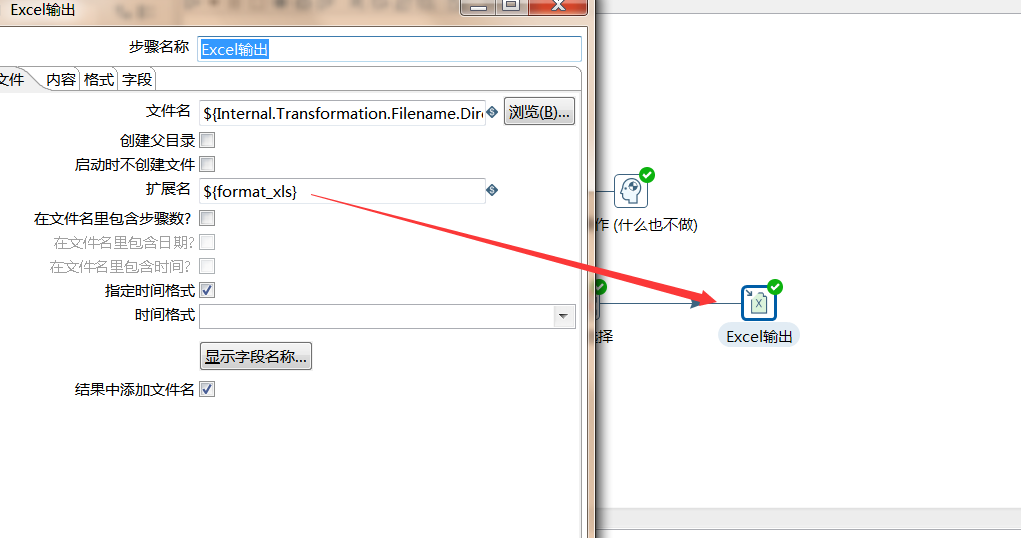
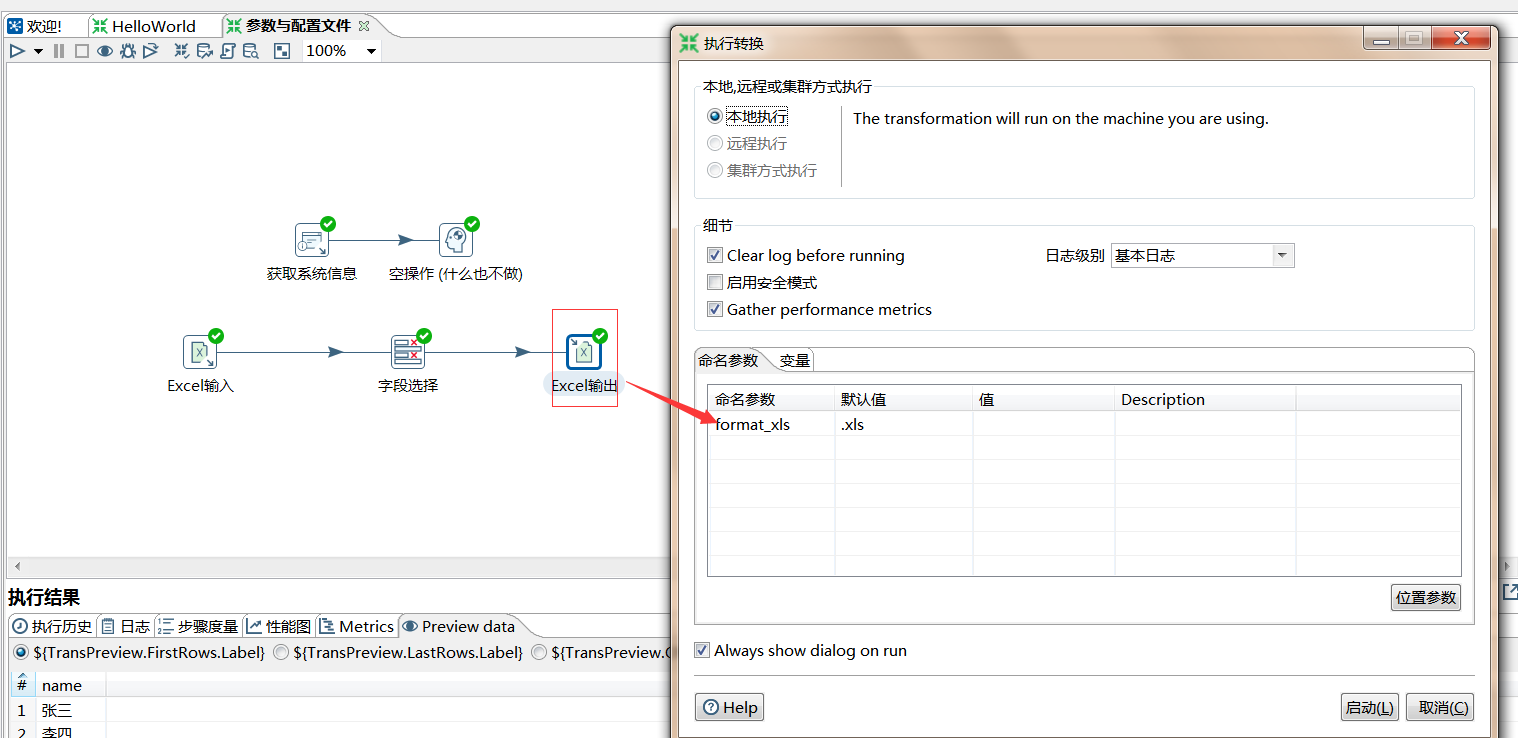
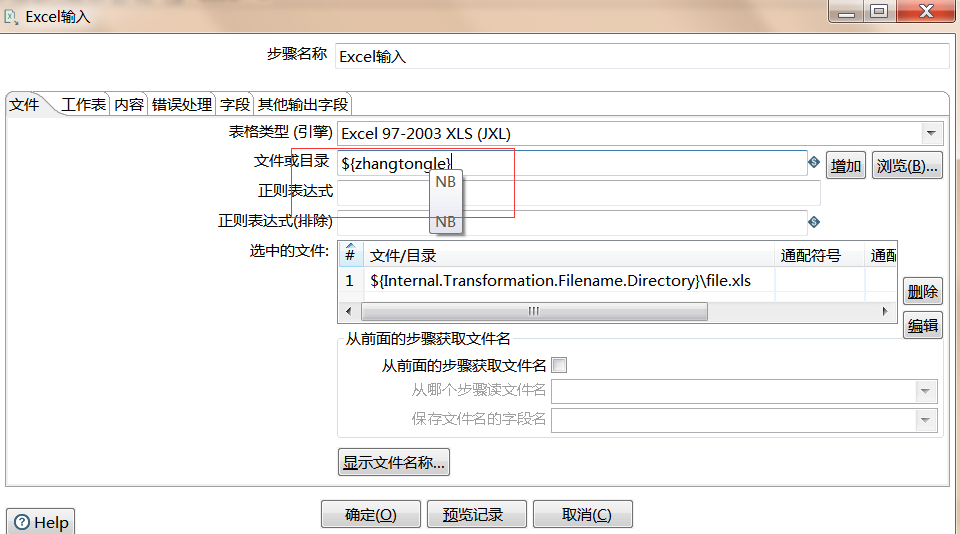
外部文件变量
在此文件夹下:C:UsersAdministrator.kettle

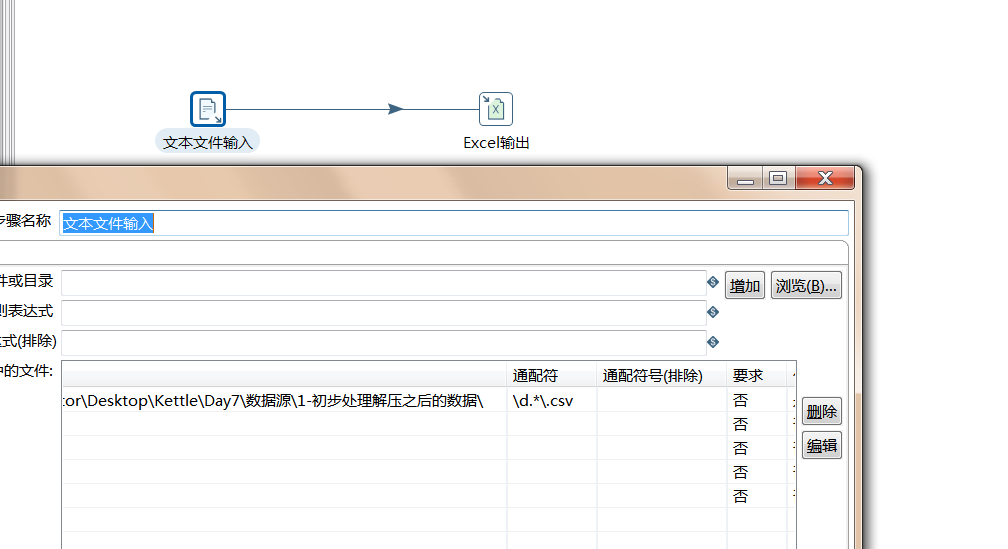
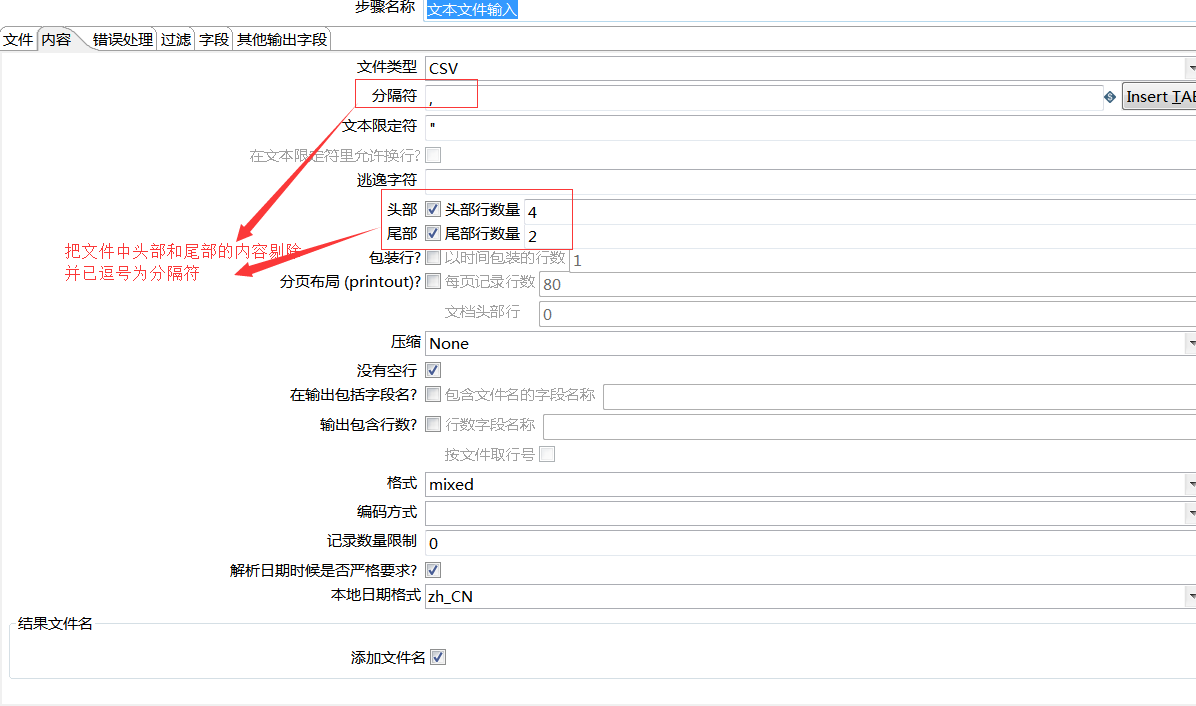
【例5】处理复杂表头的Excle
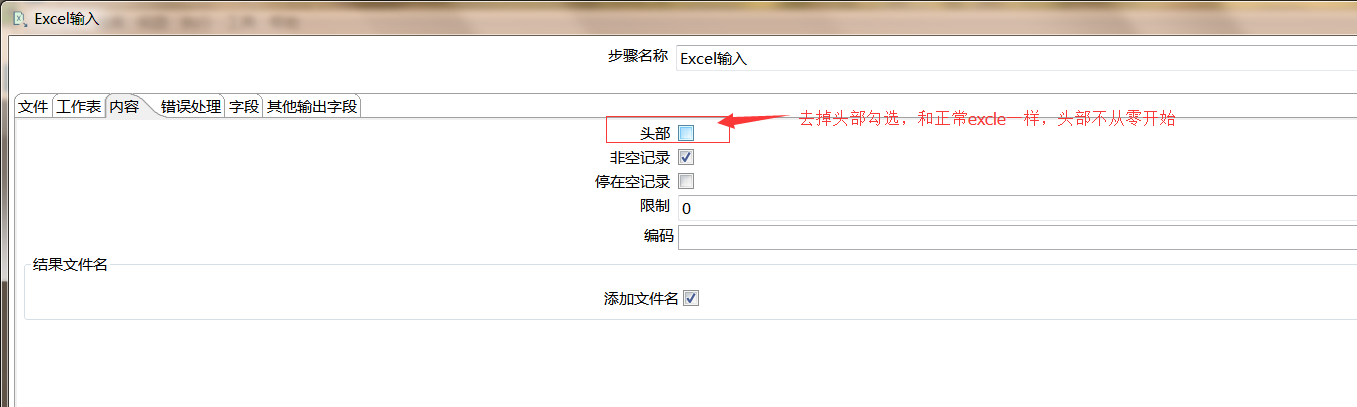
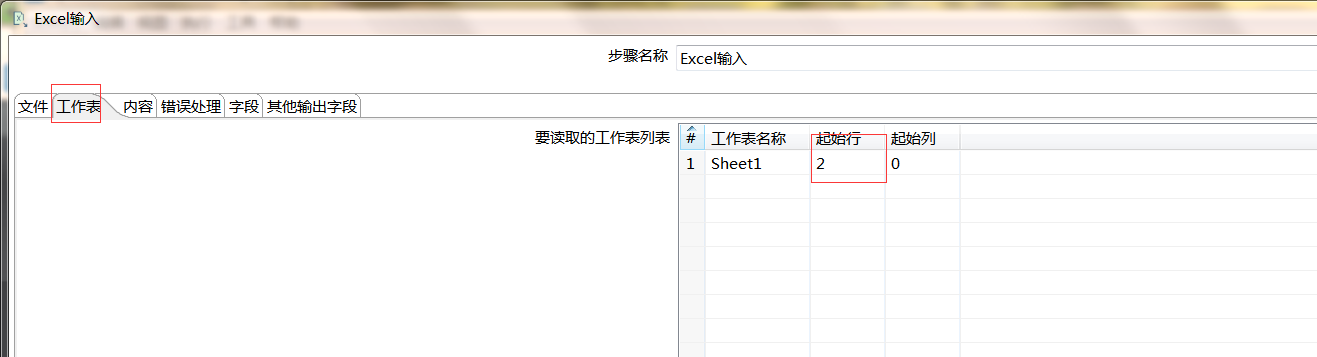

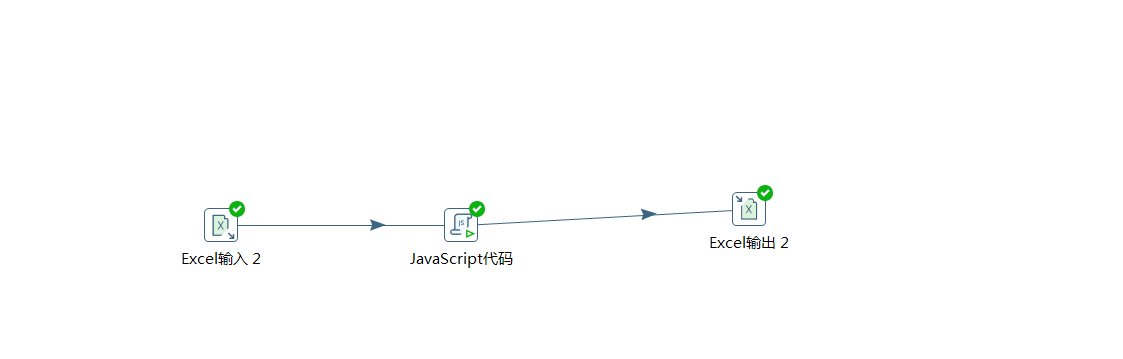
 |

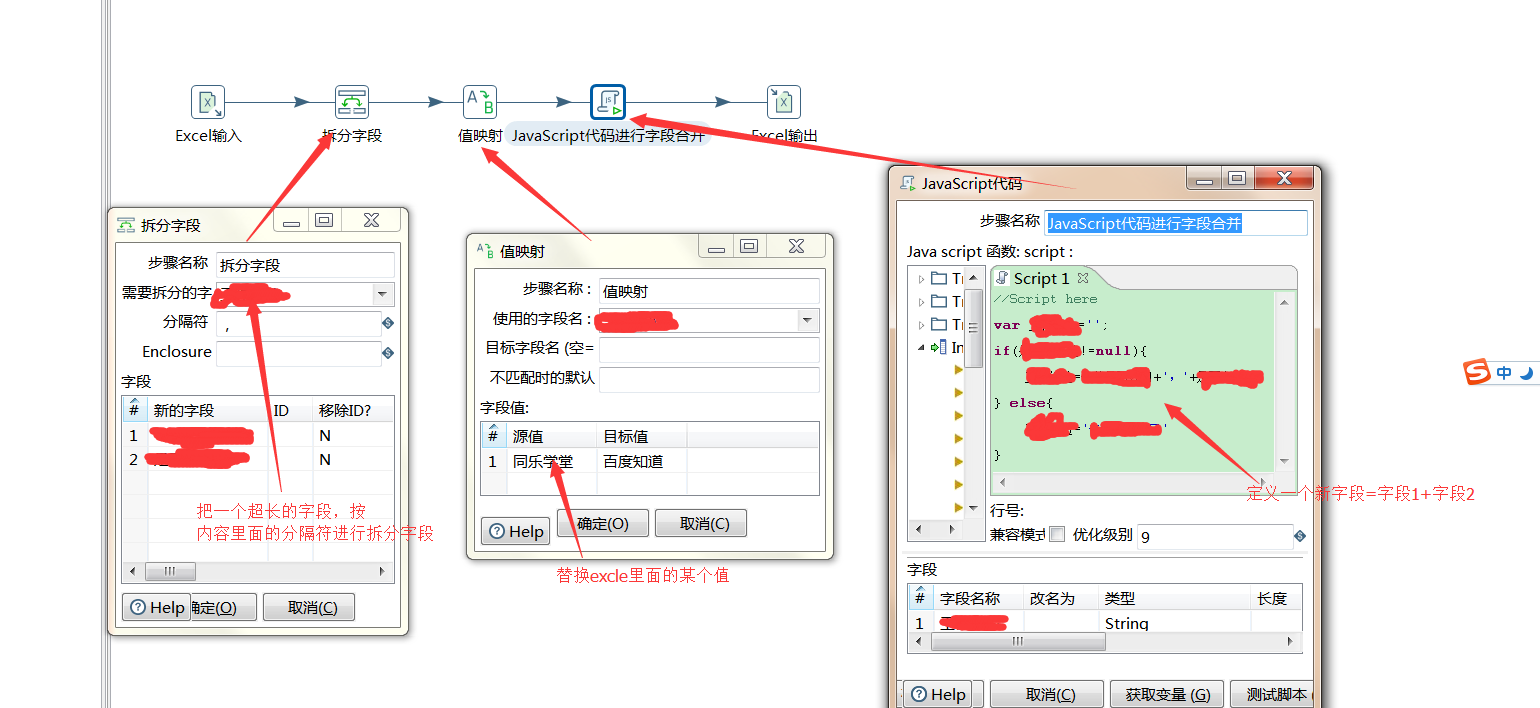
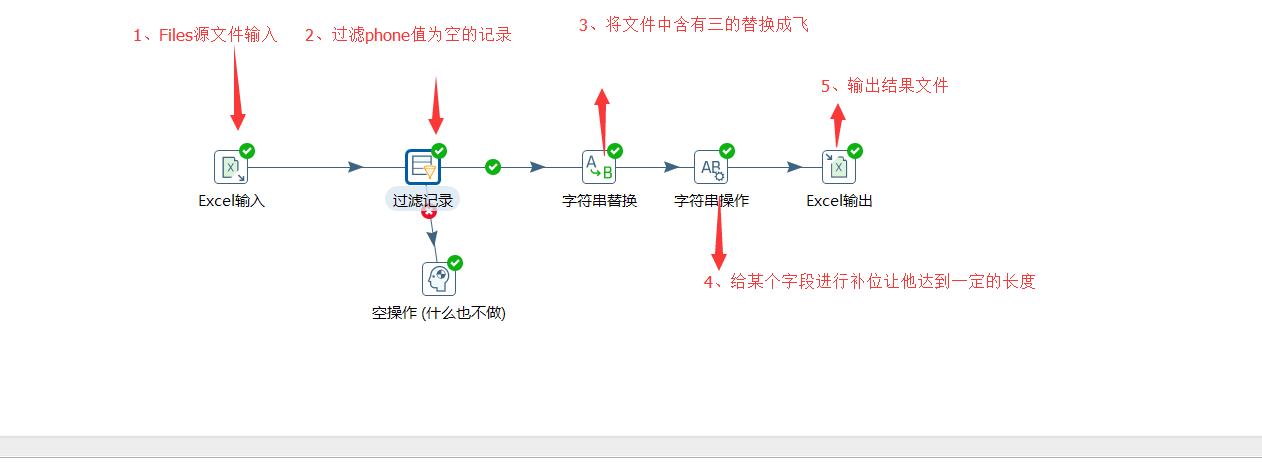
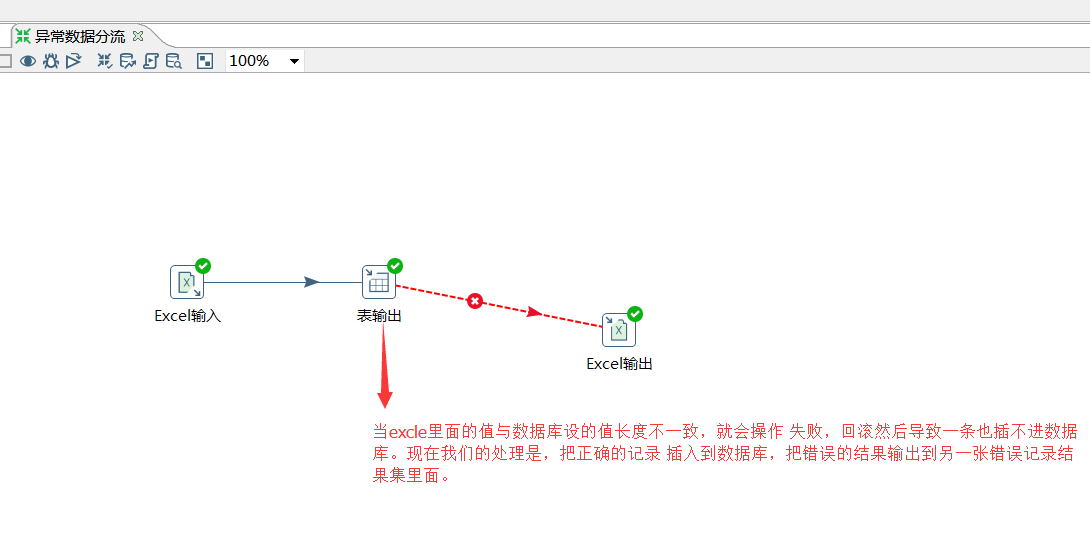

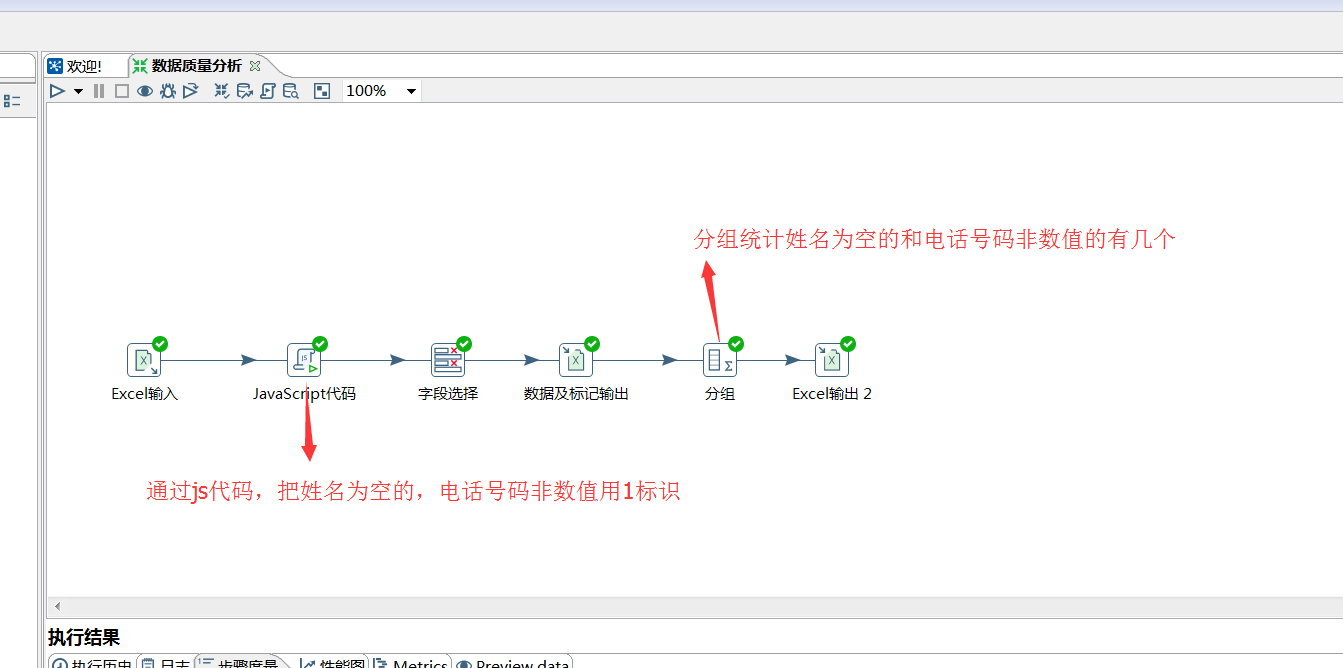

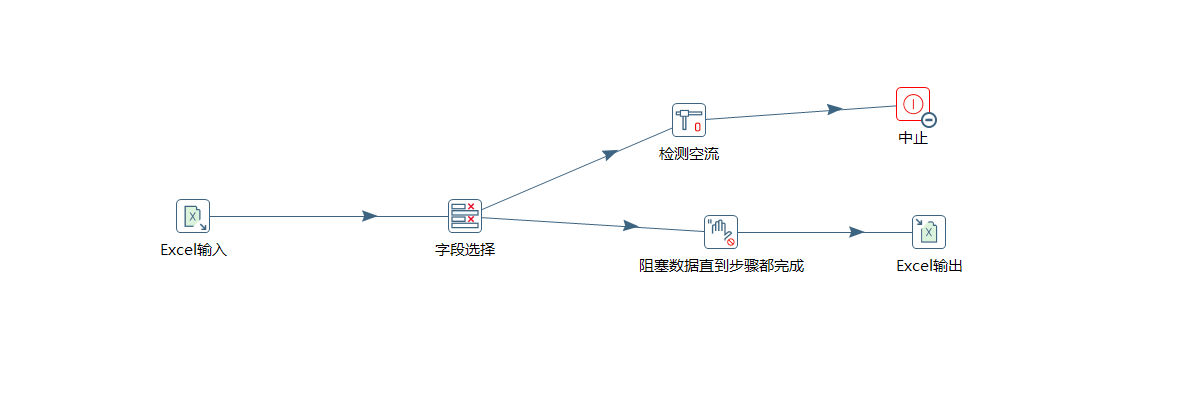
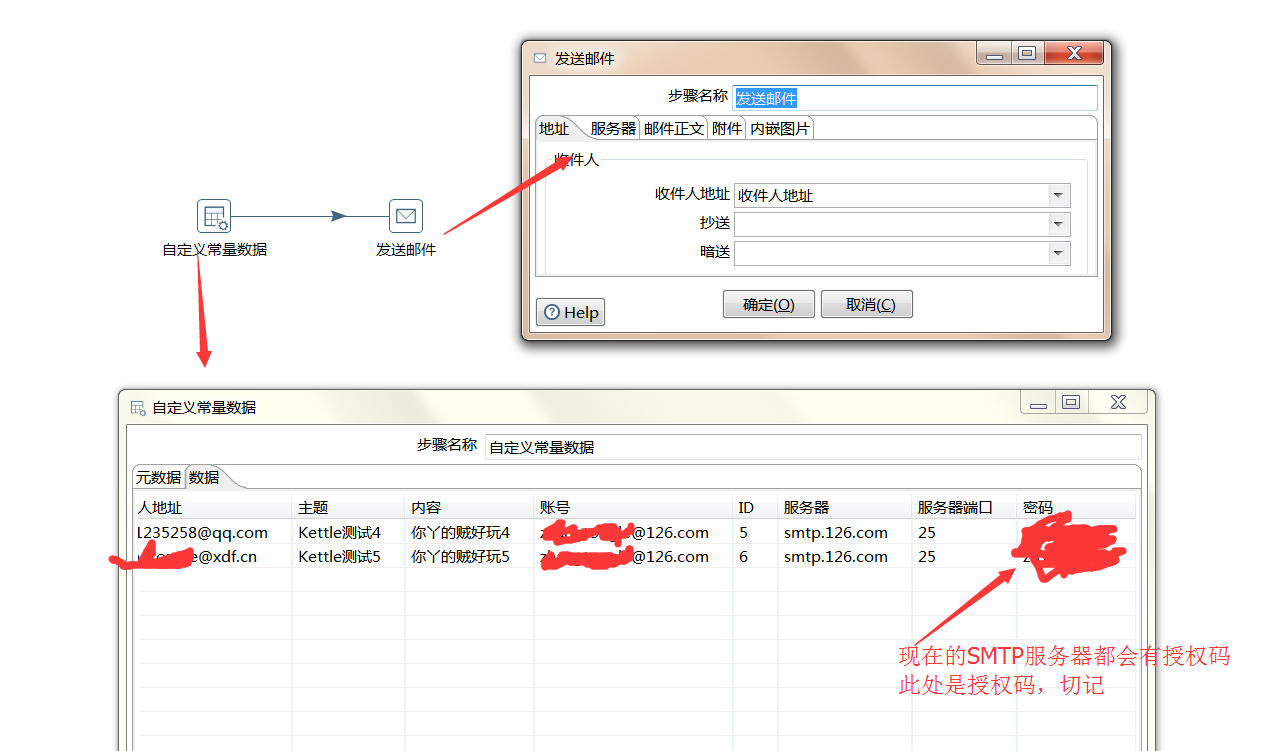
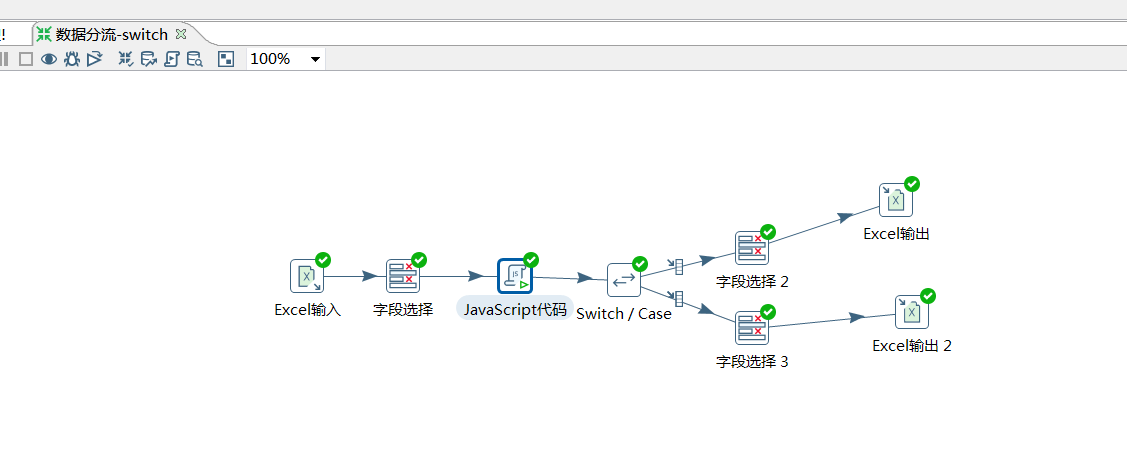
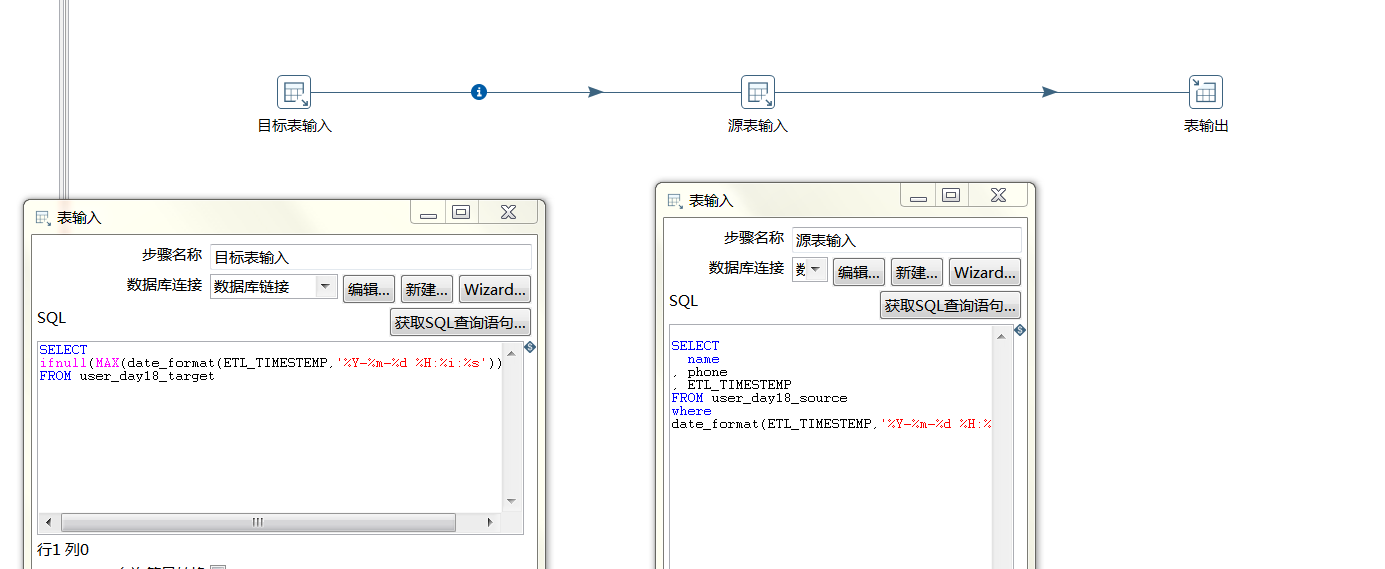

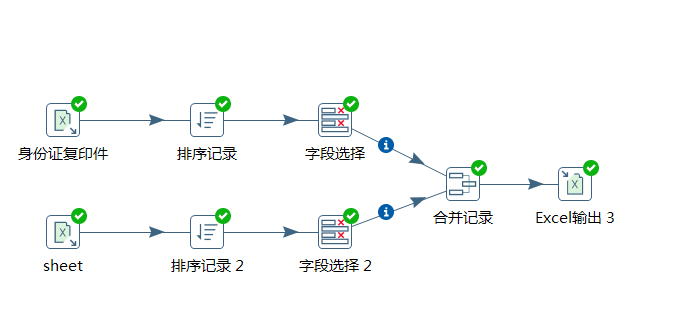
该步骤用于将两个不同来源的数据合并,这两个来源的数据分别为旧数据和新数据,该步骤将旧数据和新数据按照指定的关键字匹配、比较、合并。
需要设置的参数:
旧数据来源:旧数据来源的步骤
标志字段:设置标志字段的名称,标志字段用于保存比较的结果,比较结果有下列几种。
1. “identical” – 旧数据和新数据一样
2. “changed” – 数据发生了变化;
3. “new” – 新数据中有而旧数据中没有的记录
关键字段:用于定位两个数据源中的同一条记录。
比较字段:对于两个数据源中的同一条记录中,指定需要比较的字段。
合并后的数据将包括旧数据来源和新数据来源里的所有数据,对于变化的数据,使用新数据代替旧数据,同时在结果里用一个标示字段,来指定新旧数据的比较结果。
注意:
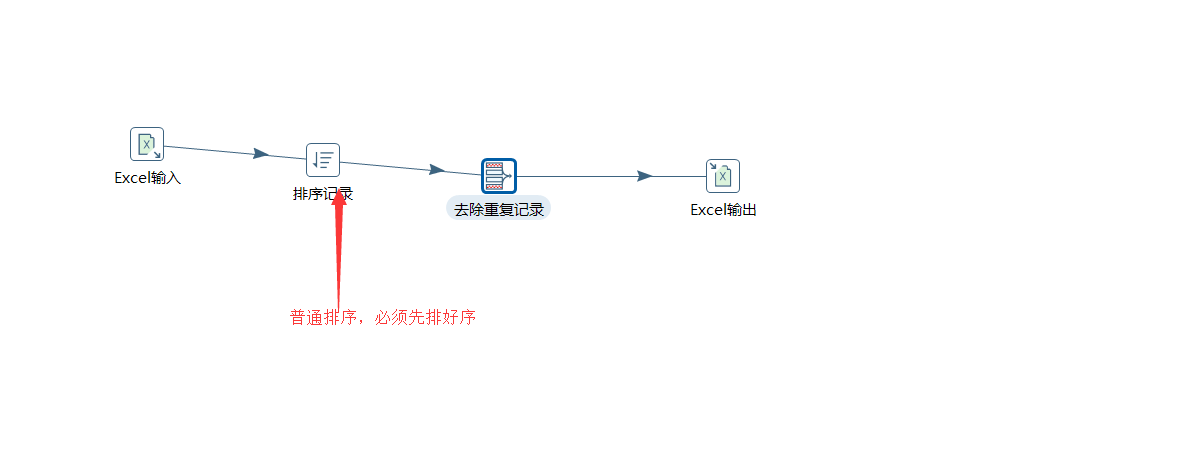
旧数据和新数据需要事先按照关键字段排序。
旧数据和新数据要有相同的字段名称。
例子:
旧数据:
field1, field2
1, 1
2, 2
3, 3
4, 4
新数据
field1, field2
1, 1
2, 9
5, 5
设置:标志字段是flag,关键字段是 field1, 比较字段是field2
合并后的数据
field1; field2; flag
1; 1; identical
2; 9; changed
3; 3; deleted
4; 4; deleted

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~





