一 Spark在百度
百度构建了国内规模最大的Spark集群之一:实际生产环境,最大单集群规模1300台(包含数万核心和上百TB内存),公司内部同时还运行着大量的小型Spark集群。百度分布式计算团队从2011年开始持续关注Spark,并于2014年将Spark正式引入百度分布式计算生态系统中,在国内率先面向开发者及企业用户推出了支持Spark并兼容开源接口的大数据处理产品BMR。
1.1.1 现状
当前百度的Spark集群平均每天提交应用量多达数百,已应用于凤巢、大搜索、直达号、百度大数据等业务。Spark的三个优点使之在百度得到快速发展:
1)快速高效。首先,Spark使用了线程池模式,任务调度效率很高;其次,Spark可以最大限度地利用内存,多轮迭代任务执行效率高。
2)API友好易用。这主要基于两个方面:第一,Spark支持多门编程语言,可以满足不同语言背景的人使用要求;第二,Spark的表达能力非常丰富,并且封装了大量常用操作。
3)组件丰富。Spark生态圈当下已比较完善,在官方组件涵盖SQL、图计算、机器学习和实时计算的同时,还有很多第三方开发的优秀组件,足以应对日常的数据处理需求。
1.1.2 百度开放云BMR的Spark
BMR的全称是Baidu MapReduce,但是这个名称已经不能完全表示出这个平台:BMR是百度开放云的数据分析服务产品。BMR是基于百度多年大数据处理分析经验,面向企业和开发者提供按需部署的Hadoop & Spark集群计算服务,让客户具备海量数据分析和挖掘能力,从而提升业务竞争力。
如图9-1所示,BMR基于BCC(百度云服务器),建立在HDFS和BOS(百度对象存储)分布式存储之上,其处理引擎包含了MapReduce和Spark,同时还使用了HBase数据库。在此之上,系统集成了Pig、Hive、SQL、Streaming、GraphX、MLLib等专有服务。在系统的最上层,BMR提供了一个基于Web的控制台,以及一个API形式的SDK。Scheduler在BMR中起到了管理作用,使用它可以编写比较复杂的作业流。

图9-1 BMR整体架构
类似于一般的云服务,BMR中的Spark同样随用随起,集群空闲即销毁,帮助用户节省预算。此外,集群创建可以在3~5分钟内完成,包含了完整的Spark+HDFS+YARN堆栈。同时,BMR也提供Long Running模式,并有多种套餐可选。
在安全上,用户拥有虚拟的独立网络,在同一用户全部集群可互联的同时,BMR用户间网络被完全隔离。同时,BMR还支持动态扩容,节点规模可弹性伸缩。
除此之外,在实现Spark全组件支持的同时,BMR可无缝对接百度对象存储(BOS)服务,借力百度多年的存储研发经验,保证数据存储的高可靠性。
1.1.3 在Spark中使用Tachyon
在Spark使用过程中,用户经常困扰于3个问题:首先,两个Spark实例通过存储系统来共享数据,这个过程中对磁盘的操作会显著降低性能;其次,因为Spark崩溃所造成的数据丢失;最后,垃圾回收机制,如果两个Spark实例需要同样的数据,那么这个数据会被缓存两次,从而造成很大的内存压力,并降低性能。而在百度,计算集群和存储集群往往不在同一个地理位置的数据中心,在大数据分析时,远程数据读取将带来非常高的延时,特别是ad-hoc查询。因此,将Tachyon作为一个传输缓存层,百度通常会将之部署在计算集群上。首次查询时,数据会从远程存储取出,而在以后的查询中,数据就会从本地的Tacnyon上读取,从而大幅改善了延时问题,如图9-2所示。

图9-2 Tachyon的整体架构
在百度,Tachyon的部署还处于初始阶段,大约部署了50台机器,主要服务于ad-hoc查询。但是相信随着Spark在百度的快速发展,Tachyon也一定会得到更加广泛的应用。
二、Spark在阿里
阿里也是国内最早使用Spark的公司之一,同时也是最早在Spark中使用了YARN的公司之一。
值得一提的是,淘宝网络数据挖掘和计算团队负责人明风先生也是国内著名的Spark方面的专家。明风和他的团队针对淘宝的大数据和应用场景,在MLlib、GraphX和Streaming三大块进行了广泛的模型训练和生产应用,并且取得了很好的效果。
尤其是他们利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产环境中的推荐算法,包括(但不局限于)以下的计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。可以说,淘宝技术团队在利用Spark来解决多次迭代的机器学习算法、高计算复杂度的算法方面,在国内居于领先的位置。
此外,阿里积极拥抱并回馈开源社区,对Spark社区的各个Feature和PR选择性地进行跟进和贡献。同时,阿里的内部版本和社区版本也保持同步性和一致性。阿里也在积极打造Spark周边的生产环境,包括MLStudio调度平台,使得Spark在阿里巴巴的应用更具推广性,可以满足大部分算法工程师和数据科学家的需求。
三、 Spark在腾讯
腾讯Spark集群已经达到8000台的规模,是当前已知的最大的Spark集群。每天运行了超过10000个作业,作业类型包括ETL、SparkSQL、机器学习、图计算和流式计算。
腾讯的广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上,支持每天上百亿的请求量。基于日志数据的快速查询系统业务构建于Spark之上的Shark,利用其快速查询以及内存表等优势,承担了日志数据的实时查询工作。在性能方面,普遍比Hive高2~10倍,如果使用内存表的功能,性能将会比Hive高百倍。
此外,腾讯使用千台规模的Spark集群来对千亿量级的节点对进行相似度计算,通过实验对比,性能是MapReduce的6倍以上,是GraphX的2倍以上。相似度计算在信息检索、数据挖掘等领域有着广泛的应用,是目前推荐引擎中的重要组成部分。随着互联网用户数目和内容的爆炸性增长,对大规模数据进行相似度计算的需求变得日益增强。在传统的MapReduce框架下进行相似度计算会引入大量的网络开销,导致性能低下。腾讯借助Spark对内存计算的支持以及图划分的思想,大大降低了网络数据传输量;并通过在系统层次对Spark的改进优化,使其可以稳定地扩展至上千台规模。
四、Spark在Amazon中的应用
亚马逊云计算服务AWS(Amazon Web Services)提供IaaS和PaaS服务。Heroku、Netflix等众多知名公司都将自己的服务托管其上。AWS以Web服务的形式向企业提供IT基础设施服务,现在通常称为云计算。云计算的主要优势是能够根据业务发展扩展的较低可变成本替代前期资本基础设施费用。利用云,企业无须提前数周或数月来计划和采购服务器及其他IT基础设施,即可在几分钟内即时运行成百上千台服务器,并更快达成结果。
1.亚马逊AWS云服务的内容
目前亚马逊在EMR中提供了弹性Spark服务,用户可以按需动态分配Spark集群计算节点,随着数据规模的增长,扩展自己的Spark数据分析集群,同时在云端的Spark集群可以无缝集成亚马逊云端的其他组件,一起构建数据分析流水线。
亚马逊云计算服务AWS提供的服务包括:亚马逊弹性计算云(Amazon EC2)、亚马逊简单存储服务(Amazon S3)、亚马逊弹性MapReduce(Amazon EMR)、亚马逊简单数据库(Amazon SimpleDB)、亚马逊简单队列服务(Amazon Simple Queue Service)、Amazon DynamoDB以及Amazon CloudFront等。基于以上的组件,亚马逊开始提供EMR上的弹性Spark服务。用户可以像之前使用EMR一样在亚马逊动态申请计算节点,可随着数据量和计算需求来动态扩展计算资源,将计算能力水平扩展,按需进行大数据分析。亚马逊提供的云服务中已经支持使用Spark集群进行大数据分析。数据可以存储在S3或者Hadoop存储层,通过Spark将数据加载进计算集群进行复杂的数据分析。
亚马逊AWS架构如图1-7所示。
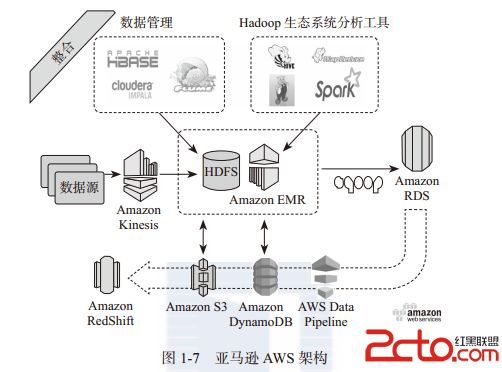
2.亚马逊的EMR中提供的3种主要组件
Master Node:主节点,负责整体的集群调度与元数据存储。
Core Node:Hadoop节点,负责数据的持久化存储,可以动态扩展资源,如更多的CPU Core、更大的内存、更大的HDFS存储空间。为了防止HDFS损坏,不能移除Core Node。
Task Node:Spark计算节点,负责执行数据分析任务,不提供HDFS,只负责提供计算资源(CPU和内存),可以动态扩展资源,可以增加和移除Task Node。
3.使用Spark on Amazon EMR的优势
构建速度快:可以在几分钟内构建小规模或者大规模Spark集群,以进行数据分析。
运维成本低:EMR负责整个集群的管理与控制,EMR也会负责失效节点的恢复。
云生态系统数据处理组件丰富:Spark集群可以很好地与Amazon云服务上的其他组件无缝集成,利用其他组件构建数据分析管道。例如,Spark可以和EC2 Spot Market、Amazon Redshift、Amazon Data pipeline、Amazon CloudWatch等组合使用。
方便调试:Spark集群的日志可以直接存储到Amazon S3中,方便用户进行日志分析。
综合以上优势,用户可以真正按需弹性使用与分配计算资源,实现节省计算成本、减轻运维压力,在几分钟内构建自己的大数据分析平台。
4.Spark on Amazon EMR架构解析
通过图1-8可以看到整个Spark on Amazon EMR的集群架构。下面以图1-8为例,分析用户如何在应用场景使用服务。
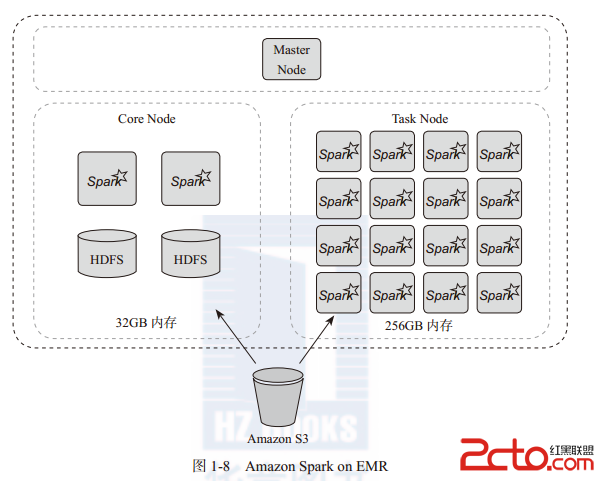
构建集群,首先创建一个Master Node作为集群的主节点。之后创建两个Core Node存储数据,两个Core Node 总共有32GB的内存。但是这些内存是不够Spark进行内存计算的。接下来动态申请16个Task Node,总共256GB内存作为计算节点,进行Spark的数据分析。
当用户开始分析数据时,Spark RDD的输入既可以来自Core Node中的HDFS,也可以来自Amazon S3,还可以通过输入数据创建RDD。用户在RDD上进行各种计算范式的数据分析,最终可以将分析结果输出到Core Node的HDFS中,也可以输出到Amazon S3中。
5.应用案例:构建1000个节点的Spark集群
读者可以通过下面的步骤,在Amazon EMR上构建自己的1000个节点的Spark数据分析平台。
1)启动1000个节点的集群,这个过程将会花费10~20分钟。
./elas2c-mapreduce --create –alive
--name "Spark/Shark Cluster" \
--bootstrap-ac2on
s3://elasBcmapreduce/samples/spark/0.8.1/install-spark-shark.sh
--bootstrap-name "Spark/Shark"
--instance-type m1.xlarge
--instance-count 1000
2)如果希望继续动态增加计算资源,可以输入下面命令增加Task Node。
--add-instance-group TASK
--instance-count INSTANCE_COUNT
--instance-type INSTANCE_TYPE
执行完步骤1)或者1)、2)后,集群将会处于图1-9所示的等待状态。
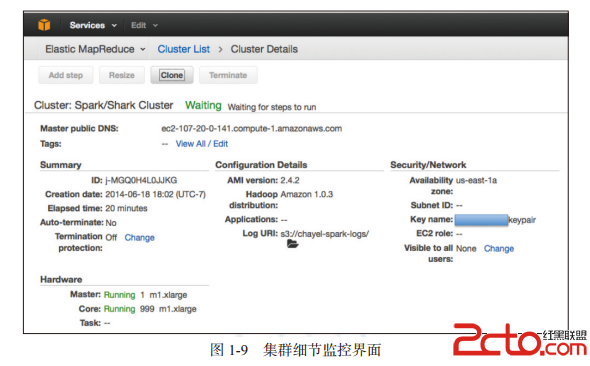
进入管理界面http://localhost:9091可以查看集群资源使用状况;进入http://localhost: 8080可以观察Spark集群的状况。Lynx界面如图1-10所示。
3)加载数据集。
示例数据集使用Wiki文章数据,总量为4.5TB,有1万亿左右记录。Wiki文章数据存储在S3中,下载地址为s3://bigdata-spark-demo/wikistats/。
下面创建wikistats表,将数据加载进表:
create external table wikistats
(
projectcode string,
pagename string,
pageviews int,
pagesize int
)
ROW FORMAT
DELIMITED FIELDS
TERMINTED BY"
LOCATION 's3n://bigdata-spark-demo/wikistats/';
ALTER TABLE wikistats add partition(dt='2007-12')location 's3n://bigdata-spark-
demo//wikistats/2007/2007-12';
......

4)分析数据。
使用Shark获取2014年2月的Top 10页面。用户可以在Shark输入下面的SQL语句进行分析。
Select pagename,sum(pageviews) c from wikistats_cached where dt='2014-01'
group by pagename order by c desc limit 10;
这个语句大致花费26s,扫描了250GB的数据。
云计算带来资源的按需分配,用户可以采用云端的虚机作为大数据分析平台的底层基础设施,在上端构建Spark集群,进行大数据分析。随着处理数据量的增加,按需扩展分析节点,增加集群的数据分析能力。
五、优酷土豆应用Spark完善大数据分析案例
大数据,一个似乎已经被媒体传播的过于泛滥的词汇,的的确确又在逐渐影响和改变着我们的生活。也许有人认为大数据在中国仍然只是噱头,但在当前中国互联网领域,大数据以及大数据所催生出来的生产力正在潜移默化地推动业务发展,并为广大中国网民提供更加优秀的服务。优酷土豆作为国内最大的视频网站,和国内其他互联网巨头一样,率先看到大数据对公司业务的价值,早在2009年就开始使用Hadoop集群,随着这些年业务迅猛发展,优酷土豆又率先尝试了仍处于大数据前沿领域的Spark/Shark 内存计算框架,很好地解决了机器学习和图计算多次迭代的瓶颈问题,使得公司大数据分析更加完善。
MapReduce之痛
提到大数据,自然不能不提Hadoop。HDFS已然成为大数据公认的存储,而MapReduce作为其搭配的数据处理框架在大数据发展的早期表现出了重大的价值。可由于其设计上的约束MapReduce只适合处理离线计算,其在实时性上仍有较大的不足,随着业务的发展,业界对实时性和准确性有更多的需求,很明显单纯依靠MapReduce框架已经不能满足业务的需求了。
优酷土豆集团大数据团队技术总监卢学裕就表示:“现在我们使用Hadoop处理一些问题诸如迭代式计算,每次对磁盘和网络的开销相当大。尤其每一次迭代计算都将结果要写到磁盘再读回来,另外计算的中间结果还需要三个备份,这其实是浪费。”
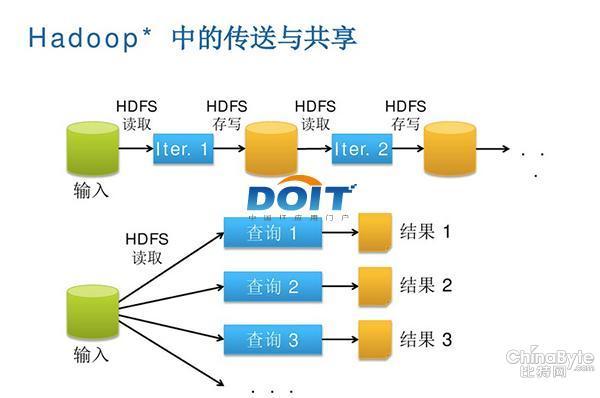
图一:Hadoop中的数据传送与共享,串行方式、复制以及磁盘IO等因素使得Hadoop集群在低延迟、实时计算方面表现有待改进。
据悉,优酷土豆的Hadoop大数据平台是从2009年开始采用,最初只有10多个节点,2012年集群节点达到150个,2013年更是达到300个,每天处理数据量达到200TB。优酷土豆鉴于Hadoop集群已经逐渐胜任不了一些应用,于是决定引入Spark/Shark内存计算框架,以此来满足图计算迭代等的需求。
Spark是一个通用的并行计算框架,由伯克利大学的AMP实验室开发,Spark已经成为继Hadoop之后又一大热门开源项目,目前已经有英特尔等企业加入到该开源项目。
、
图二:Spark内存计算框架使得数据共享比网络和磁盘快10倍到100倍。
“我们大数据平台对快速需求的响应延时,尤其是在商业智能BI以及产品研究分析等需要多次对大数据做Drill Down与Drill Up时,等待成了效率杀手。” 优酷土豆集团大数据团队技术总监卢学裕表示。
用Spark/Shark完善大数据分析
目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。优酷土豆属于典型的互联网公司,目前运用大数据分析平台的主要工作是运营分析、机器学习、广告定向优化、搜索优化等方面。
优酷土豆集团大数据团队技术总监卢学裕表示:“优酷土豆的大数据平台已经用了很多年,突出问题主要包括:第一是商业智能BI方面,公司的分析师提交任务之后需要等待很久才得到结果;第二就是大数据量计算,比如进行一些模拟广告投放之时,计算量非常大的同时对效率要求也比较高,用Hadoop消耗资源非常大而且响应比较慢;最后就是机器学习和图计算的迭代运算也是需要耗费大量资源且速度很慢。”
因此,面对复杂任务、交互式查询以及流在线处理时,Hadoop与MapReduce并不适用。Spark/Shark这种内存型计算框架则比较适合各种迭代算法和交互式数据分析,可每次将弹性分布式数据集(RDD)操作之后的结果存入内存中,下次操作可直接从内存中读取,省去了大量的磁盘IO,效率也随之大幅提升。优酷土豆集团大数据团队大数据平台架构师傅杰表示:“一些应用场景并不适合在MapReduce里面去处理。通过对比,我们发现Spark性能比MapReduce提升很多。”

图三:Spark/Shark内存计算框架实时日志聚合处理。
“比如在图计算方面,视频与视频之间存在的相似关系,这就构成了一个图谱,通过图谱来做聚类,再给用户做视频推荐。” 优酷土豆集团大数据团队技术总监卢学裕表示。
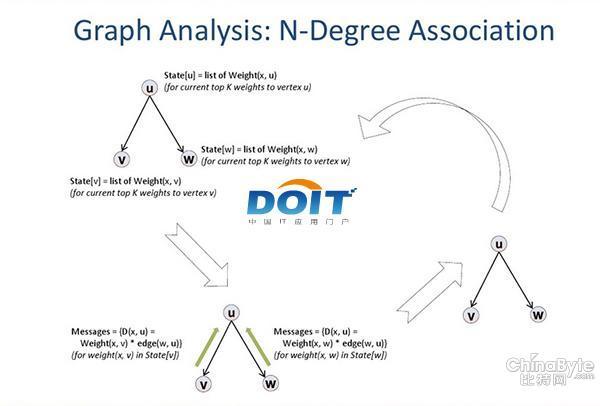
图四:图计算分析N度关联算法示意图。
优酷土豆集团大数据团队技术总监卢学裕表示:“我们进行过图计算方面的测试,在4台节点的Spark集群上用时只有5.6分钟,而同规模的数据量,单机实现需要80多分钟,并且内存吃满,单机无法实现Scale-Out,不能计算更大规模数据。”
“在今天,数据处理要求非常快。比如优酷土豆的一些客户、广告商往往临时就需要看一下投放效果。所以在前端应用不变的情况下,如果能更快的响应市场的需要就变得很有竞争力。市场是瞬息万变的,有一些分析结果也需要快速响应成一个产品,Spark集成到数据平台正能发挥这样的效果。” 优酷土豆集团大数据团队大数据平台架构师傅杰补充道。
据了解,优酷土豆采用Spark/Shark大数据计算框架得到了英特尔公司的帮助,起初优酷土豆并不熟悉Spark以及Scala语言,英特尔帮助优酷土豆设计出具体符合业务需求的解决方案,并协助优酷土豆实现了该方案。此外,英特尔还给优酷土豆的大数据团队进行了Scala语言、Spark的培训等。
“优酷土豆作为国内视频行业第一家商用部署Spark/Shark方案的公司,从视频行业的多样化分析角度来看是个非常好的方案。未来,英特尔将会继续与优酷土豆在Spark/Shark进行合作,包括硬件配置的优化以及整体方案的优化等”英特尔(中国)有限公司销售市场部互联网及媒体行业企业客户经理李志辉介绍道。
未来:将Spark/Shark融入到Hadoop 2.0
对于大数据而言,Hadoop已经构建完成了较为完善的生态系统,特别是Hadoop 2.0版本在今年推出之后,改善了诸多缺点。而Spark/Shark计算框架其实与Hadoop并不冲突,Spark现在已经可以直接运行在Yarn的框架之上,成为Hadoop生态系统之中不可或缺的成员。
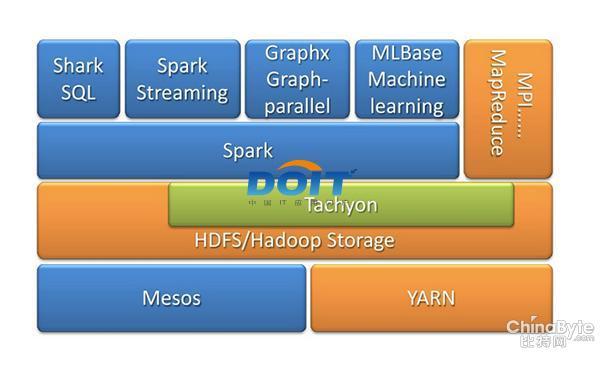
图五:Spark On Yarn 。
优酷土豆集团大数据团队大数据平台架构师傅杰表示:“目前Hadoop 2.0已经发布了release版本,我们已经启动了对Hadoop 2.0的升级预演。这中间还涉及到我们在1.0版本上修改的一些特性需要迁移和验证,我们希望做到在不影响业务的情况下实现平滑升级,预计在明年Q1完成升级。Hadoop 2.0将会是非常强大的,不再仅仅是MapReduce,还能融入Spark,能够让用户可以根据数据处理应用需求的不同来选择合适的计算框架。
六、小结
Spark在国内的应用越来越广泛,除了上面提到的百度、阿里和腾讯,现在京东、优酷土豆、携程等互联网公司也在使用Spark。除了Spark的使用,华为、星环科技等公司也在做基于Spark的商业解决方案,尤其是星环科技,基于Spark做了很多二次开发。除此之外,英特尔上海有超过10个人的团队在做Spark的开发,是Spark非常重要的贡献者。
来源: Spark大数据处理: 技术、应用与性能优化(图书)
Spark技术内幕:深入解析Spark内核架构设计与实现原理(图书)
51cto:http://database.51cto.com/art/201403/433982.htm(博客)

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


![spark streaming知识总结[优化]-同乐学堂](https://www.ztloo.com/wp-content/uploads/2017/04/63ba4d80dfb07ad447c0682ef688098b-220x76.jpg)




