一、前言
本章将介绍HBase相关的一些比较核心的理论概念并剖析其实现逻辑,深入浅出锄
绍HBase实现中所涉及的理论基础。当然,HBase的实现涉及很多方面的知识,本章分别
从存储结构、持久化实现、预写日志、写人和查询流程、数据备份及压缩等多方面阐述。
在阐述过程中,为了形象地说明问题,会枚举不少示例和代码讲解,希望能够加深读者的
认识。
HBase作为一个分布式、面向列的高性能数据库,无论批量写人和读取的性能都很高,
而能够具备这些特性,其内部实现必定使用了一些特殊、高效的算法和机制。如何保证海量
数据下的读写性能?如何保证容错?如何灾备如何存储实际数据和日志?等等问题都会浮
现在读者的脑海中。本章将会对这些问题做全面、深人解释,希望读者在阅读完本章后,都
能找到上述问题的答案。
核心结构
对于数据库产品,底层存储架构直接决定了数据库的特性和使用场景。众所周知,传
统RDBMS(关系型数据库)使用B树及B+树作为数据存储结构,B树及B+树作为成熟
的存储结构应用在数据库领域已经有几十年的历史。相对而言,RDBMS的替代品,NosQL
之一的HBase的底层存储结构与其有着根本上的不同。HBase使用LSM树
(日志结构合并树)作为底层存储的数据结构。
当然,RDBMS并不是只能采用B+树类型的结构,而且也不是所有的NoSQL解决方案
都使用了与之不同的结构。通常我们都能看到各式各样的混搭型的技术方案,它们都具有一个相同的目标;使用解决当前问题的最佳策略。下面将会解释LSM树与B+树的不同,以及为何选用LSM作为Hbase的底层存储架构。
二、 [HBase] LSM树 VS B+树
LSM树是Hbase里非常有创意的一种数据结构,它和传统的B+树不太一样,下面先说说B+树。
1 B+树
相信大家对B+树已经非常的熟悉,比如Oracle的普通索引就是采用B+树的方式,下面是一个B+树的例子:
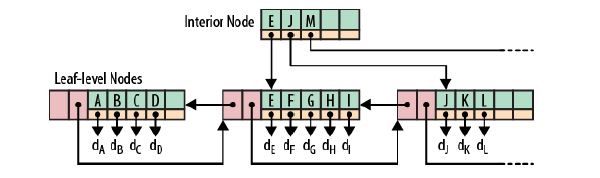
根节点和枝节点很简单,分别记录每个叶子节点的最小值,并用一个指针指向叶子节点。
叶子节点里每个键值都指向真正的数据块(如Oracle里的RowID),每个叶子节点都有前指针和后指针,这是为了做范围查询时,叶子节点间可以直接跳转,从而避免再去回溯至枝和跟节点。
B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。
对于大量的随机写也一样,举一个插入key跨度很大的例子,如7->1000->3->2000 ... 新插入的数据存储在磁盘上相隔很远,会产生大量的随机写IO.
从上面可以看出,低下的磁盘寻道速度严重影响性能(近些年来,磁盘寻道速度的发展几乎处于停滞的状态)。
2 LSM树
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
为了更好的说明LSM树的原理,下面举个比较极端的例子:
现在假设有1000个节点的随机key,对于磁盘来说,肯定是把这1000个节点顺序写入磁盘最快,但是这样一来,读就悲剧了,因为key在磁盘中完全无序,每次读取都要全扫描;
那么,为了让读性能尽量高,数据在磁盘中必须得有序,这就是B+树的原理,但是写就悲剧了,因为会产生大量的随机IO,磁盘寻道速度跟不上。
LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。
它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。
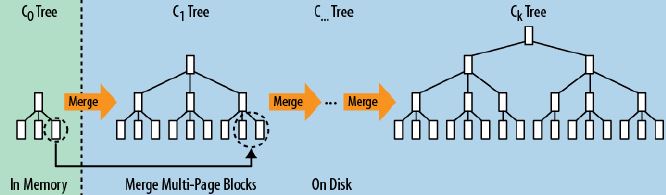
以上就是LSM树最本质的原理,有了原理,再看具体的技术就很简单了。
1)首先说说为什么要有WAL(Write Ahead Log),很简单,因为数据是先写到内存中,如果断电,内存中的数据会丢失,因此为了保护内存中的数据,需要在磁盘上先记录logfile,当内存中的数据flush到磁盘上时,就可以抛弃相应的Logfile。
2)什么是memstore, storefile?很简单,上面说过,LSM树就是一堆小树,在内存中的小树即memstore,每次flush,内存中的memstore变成磁盘上一个新的storefile。
3)为什么会有compact?很简单,随着小树越来越多,读的性能会越来越差,因此需要在适当的时候,对磁盘中的小树进行merge,多棵小树变成一颗大树。
三、理解这个图很重要
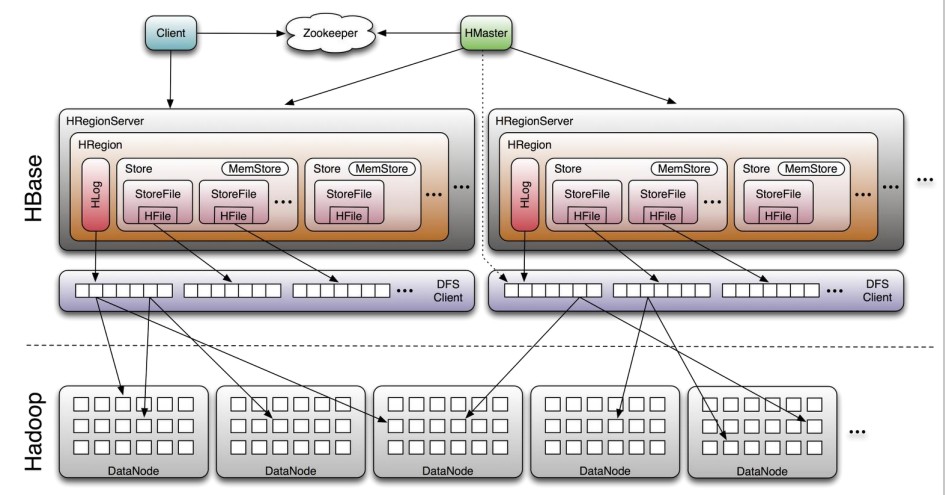
3.1 、底层持久化
绝大部分的用户不需要关心数据在HBase到底是如何存储的,但是当对HBase进行性能
调优和高级选项配置时,仍需要了解这方面的知识。例如,前面两章中提到的一些配置参数,
另一方面,如果HBase相关进程崩溃,或者更严重的情况如机器宕机,读者需要恢复数
据或者重新安装HBase,以及升级HBase版本。这个时候,读者需要知道数据存储的路径,
如何通过HDFS访问这些数据,如何使用故障恢复命令等。读者可以利用下面即将讲到的知
识来排查和解决上面提到的各种问题。
3.1.1 、 存储基本架构
通过上图可直观、形象地理解H8ase的文件存储层的各组成部分,图中展示了HBase
与HDFS是如何协作来存储数据的。
HBase处理的两种基本文件类型一个用于WAL(Write-Ahead Log),另一个用于实际
的数据存储。文件主要是由HRegionserver处理、在某些情况下,HMaster也会执行底
层的文件操作。当存储在HDFS中时,文件实际上会被划分为很多小Block,如果需要配置
系统来更好地处理更大或更小的文件时,则需要了解更多的细节内容,这些内容将在下
节里描述。
通常的工作流程是,一个新的客户端为找到某个特定的行键首先需要连接ZooKeeper
Qurom。它会从ZooKeeper检索持有-ROOT-Region的服务器名、通过这个信息,它询问拥
有-ROOT-Region的Regionserver,得到持有对应行健的.META表Region的服务器名。这
两个操作的结果都会被缓存下来,因此只需要查找一次、最后,它就可以查询.META.服务
器,然后检索包含给定行键的Region所在的服务器、
一旦它知道了给定的行键所处的位置,比如,在哪个Region里,它也会缓存该信息,
同时直接连接持有该Region的HRegionserver。现在,客户端就有了去哪里获取行的完整信
息而不需要再去查询.META.服务器。
在启动HBase时,HMaster负责把Region分配给每个HRegionserver,包括-ROOT一
和.META表。
HRegionserver打开Region然后创建对应的HRegion对象,当HRegion被打开后,它就
会为表中预先定义的每个HColumn Family创建一个Store实例,每个Store实例又可能有多
个StoreFile实例,StoreFile是对被称为HFile的实际存储文件的一个简单封装、一个Store
实例还会有二个Memstore,以及一个由HRegionserver共享的HLog实例(WAL相关的类)。
3.1.2 、HDFS文件
Hbase在Hadoop上有一个可配置的根目录,默认配置为/hbase,该路径可以通过配置hbase.site.xml 配置
Hbase文件可以分为两类,一是直接位于Hbase根目录下面的文件;二是位于表目录下面的文件。
1.根目录
第二类文件是由HLog实例处理的WAL文件,这些文件创建在HBase根目录下一个称
为·logs的目录中。.logs目录下包含针对每个取egionserver的子目录。在每个子目录下,通常有
几个HLog文件(因为日志的切换而产生),来自相同Regionserver的Region共享这些HLog文件。
对于最近创建的文件通常日志文件大小为o,因为HDFs正使用二个内置的append支持来
对文件进行写人,同时对于读取者来说只有那些完整的Block才是可用的,包括hadoop fs-lsr命
令。尽管写操作的数据被安全地持久化,但是当前写人的日志文件大小信息有些轻微的不同步。
日志文件每小时切换一次(默认60分钟)后,这个时间是由hbase.regionserver.logroll.period
配置项控制。等日志文件切换后,可以查看其正确大小,因为该文件已经被关闭了,所以
HDFS可以获取正确的状态。而其之后的新日志文件大小又会变成0
当日志文件不再需要时,现有的变更已经持久化到存储文件中了,它们就会被移到
HBase根目录的.o161ogs目录中。这是在日志文件达到上面的切换阈值时触发的。老的日志
文件默认会在10分钟后被Mast·r删除,通过hbase.master.lowleaner.ttl设定。Master默认每
分钟会对这些文件进行检查,可以通过hbase.master.cleaner.interval设定。
hbase.id 和hbase.version 文件包含集群的唯一ID和文件格式版本号、这两个文件都是内部使用、通常无需关心。
此外,随着时间的推移还会产生一些根目录级的文件。splitlog和.corrupt 目录分别是日志split进程用来存储总监split文件的损坏的日志文件。.archive 用于存储表的归档和快照。
2、表目录
Hbase中的每个表都有它自己的目录,位于hbase根目录只有放下。 每个表目录包含一个名为.tableinfo 的顶层文件,该文件保存了针对该表 HTableDescriptor 序列化后的内容,包含了元数据信息,
同时可以被读取,比如通过实用工具可以查看表的定义;.tmp目录包含一些中间数据,比如当 .tableinfo 被更新时该目录就会被用到。
3、Region
Region目录也包含了一个.regioninfowenjian ,其中包含了Region的HRegionInfo的序列化信息,类似于 .tableinfo,它也可以通过外部工具来查看关于Region的相关信息。
hbase的 hbck工具可以用它来生成丢失的表条目元数据。
可选的.tmp目录是按需创建的,用来存储临时文件,比如某个合并产生的重新写回的文
件。一旦该过程结束,它们会被立即移入Region目录。在极端情况下,你可能会看到一些残
留文件,在重新打开Region时它们会被清除。
在WAL回放期间,任何尚未提交的修改会写人每个Region各自对应的文件中。这是
第一个阶段,之后假设日志splitting过程成功完成,然后会将这些文件原子性地move到
recovered.edits目录下。当打开该Region时,Regionserver能够看到这些恢复文件然后回放
相应的记录。
注意:
WAL的spliting和Region的splitting之间有明显的区别。有些时候,在文件系统中
很难区分文件和目录的不同,因为它们两个都涉及了splits这个名词。为避免错误和
混淆,这里强调了这个区别,以确保你已经理解了二者的不同。
且一个Region因为容量大小而需要split,会创建一个与之对应的SPlits目录,用来筹
划产生两个子Region。通常只需要几秒或更短的时间,该过程成功之后它们会被移人表目录
下用来形成两个新的Region,每个代表原始Region的一半。
换句话说,如果发现一个Region目录下没有.tmp目录,那么说明目前它上面没有执行合并。如果也没有Recovered.edits目录,那么说明目前没有针对她的WAL回放。
4、Hbase Region的拆分和合并
•拆分决定因素
Hbase中的表的region的拆分主要由以下的因素决定
Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”)
其中R是该region中所包含的该表的region的数量,一般情况下如果memstore.flush.size 的值是128M,那么当开始新建一张表并开始写入数据时,当达到128M开始第一次拆分,之后依次是512MB, 1152MB, 2GB, 3.2GB, 4.6GB, 6.2GB时候开始进行拆分,当达到max.filesize的设定值时便会永远在storefile 达到max.filesize进行拆分(默认情况下这个值是10G,在0.90.x版本是256M,现在版本中的默认是是10G),需要特别注意的是filessize指的是store下的storefile的大小并不是整个region的大小,一个region可能包含很多个store,确切的说是该表有多少个family就有多少个store,当某个family下的storefile达到以上标准是就会拆分整个region而不管改region下的其他的store下的storefile是否已经达到触发条件。按照我的理解,当第一次拆分后所生成的两个新的region,而这两个region有可能会被分配给不同的region server所以当这个region server 进行第二次拆分的时候R的值有可能是1而不是2,这样一直到所有的region server的节点全部分配到一个region为此(这还需要进一步去验证,因为我至今还搞不清楚当一个region进行拆分式会不会把拆分后的两个region都assign给父region所在的region server,当然我这样的猜测的依据是当出现一个hot region的时候通过手工拆分region可以达到负载均衡的目的,既然是达到负载均衡那肯定是把拆分后的俩region分配到了不同的region sever否则负载均衡大约无从谈起)。
•预拆分
region拆分的另一个问题是当一个新表刚开始建立的时候,默认是一个region这就意味着所有的客户端请求都要去请求这个region所在的region server,这样子其实限制了整个集群的能力,一直到数据足够大到能够触发拆分,并且拆分到的region能够均匀的分布到各个region server中去之后才能发挥整个集群的威力。按照上面的拆分约定,第一次拆分仅仅是store的数据达到128M,这并不算大,但是并不意味着可以等待这样的自动拆分,设想一种极端的情况,表建立之后就有1000个客户端同时请求写入数据,那么要等待自动拆分到足够region的数量才能够均衡这样的1000个客户端请求,那效率依然是十分低下的。解决的办法是在创建表的时候进行预拆分,就是在建表的时候先预先创建多个region这样子客户端请求的时候就可以分散到不同的region server去请求写入。
第一种对表进行预拆分的方法
$ hbase org.apache.Hadoop.hbase.util.RegionSplitter test_table HexStringSplit -c 10 -f f1:f2:f3
表名:test_table
拆分的region的数量:10
family:f1,f2,f3
第二中预拆分的方法是,当知道rowkey的分布的时候可以指定每个预拆分的region的rowkey的开始值:
hbase(main):015:0> create 'test_table', 'f1', SPLITS=> ['a', 'b', 'c']
•手动拆分
当出现hot region的时候,通常是因为rowkey设计不合理造成的,比如说是自增长的ID,会导致连续的行集中在同一个region中(默认是10G),如果这个region中连续的rowkey都是近一个月的数据,而客户端请求得最为频繁的也是当月的数据,那么就会造成所有请求当月数据的的客户端都连接到该region,导致阻塞,所以彻底解决办法是对rowkey进行良好的设计以让rowkey在集群中均匀分布,如果hot region已经产生,那么就需要手动的去拆分region以让拆分出来的两个region或者数个region分布到不同的region server中去
hbase(main):024:0> split 'b07d0034cbe72cb040ae9cf66300a10c', 'b'
•拆分流程
详细的拆分流程可以参考我转的文章《Apache HBase Region Splitting and Merging》,总得来说可以分为,当一个region要拆分的时候会首先将该region下线,然后block住所有的对该region的客户端请求(所以在事务系统中在拆分的策略上进行均衡),拆分的时候会在首先在父region下建立两个referencefile用来指向父region的首行和末行,但是referencefile并不会从父region中拷贝数据,之后HDFS上建立两个字region的目录然后分别拷贝上步建立的referencefile文件,记住referencefile虽然只是指向父region的数据但是却可以当做子的storefile(分别占据父region的一半数据)使用,完成子region的创建之后会想meta表发送新产生的region的元数据信息。当子的region的memstore不断flush成为新的storefile文件,达到一定数量级的时候就会触发合并(下面会提到),合并的时候就会去父region提取属于它的那一半的数据加上它自己的新生成的storefile的数据,合并完成之后就会自动删除referencefile的文件。
•合并
客户端的数据写入region的时候并不会直接写到storefile中而是先写到内存缓冲区memstore(比如大小128M)中,满了之后会flush到store下成为单独的storefile,所以一个store下可能会有多个storefile,当storefile的个数达到设定值(默认是3)时就会合并成一个大的storefile,而当一个storefile达到上述的临界值又会自动进行拆分。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~





